Hadoop本読書会 - 13章 ZooKeeper
最終更新:ID:hgJMx3CHVA 2011年04月01日(金) 00:02:28履歴
Hadoop本13章が分かりやすい解説になっているとは言えないので、勉強会資料を書き起こしてます。Hadoop本は参考書程度に。(terurou)
ZooKeeperとは
ZooKeeperの使いどころ
ZooKeeperの採用実績
ZooKeeperの資料
ZooKeeperの特徴
ZooKeeperのデータモデル
znode
一時ノード(ephemeral nodes)
シーケンシャルznode
ACL(Access Control List)
Watcher
一貫性(データ整合性の保証)
ZooKeeperの内部実装
基本的な考え方
Zab(ZooKeeper Atomic Broadcast)プロトコル
リーダーの選出
アトミックブロードキャスト
トランザクションログとスナップショット
セッション
tick
インストール
インストール(スタンドアロン)
コマンドラインツール(対話環境)
クラスタの構築
運用時の設定ポイント
APIの概要
ZooKeeperクライアントライブラリが用意されている言語
基本API
Watcher
getData()で設定したWatcherで検知できるイベント
getChildren()で設定したWatcherで検知できるイベント
exists()で設定したWatcherで検知できるイベント
ACL
識別照明(認証方法)
パーミッション
実装例
同期的にZooKeeperサービスへ接続
Queue, Priority Queue, Barriers
Primitive Counter
cages - A distributed synchronization library for Zookeeper
ZooKeeperとは 
- A Distributed Coordination Service for Distributed Applications
- 「分散システムのための分散協調サービスです(キリッ」 『えっ』「えっ」
- 簡単に言うと分散システムでの面倒なところをよしなにしてくれるモノ
- 分散システムでロック・メタデータ共有・データ更新時のイベント通知等を行ってくれる
- Google MapReduceファミリーのChubbyに該当するモノ
ZooKeeperの使いどころ
- 分散環境での同期処理
- 分散MessageQueue
- クラスタのリーダーノード(マスタノード)の確定、ダウン時のノード切り替え
- シーケンシャルカウンタ
- あなたはロックも共有メモリもない分散環境な世界でAtomicなカウンタを実装できますか?
- アプリケーション設定情報の管理・共有
- 1箇所で設定内容を更新すると、それがダイナミックに拡散・適用されていくような仕組みを実装できる
- などなど
ZooKeeperの採用実績
- HBase
- クラスタノードのIPアドレスルックアップ、ノード死活監視
- Rackspace
- メールサービス
- Yahoo!Inc
- 複数サービスで広く利用(クラスタ管理、構成管理、共有、ロックなど)
- その他 http://wiki.apache.org/hadoop/ZooKeeper/PoweredBy を参照
ZooKeeperの資料
ZooKeeperの特徴
- シンプルなAPI
- 高いパフォーマンス
- Readのパフォーマンス重視
- Read:Write = 10:1 の場合に最も高いパフォーマンスを発揮する、らしい
- http://hadoop.apache.org/zookeeper/docs/r3.3.2/zoo... に"ZooKeeper is fast. It is especially fast in "read-dominant" workloads. ZooKeeper applications run on thousands of machines, and it performs best where reads are more common than writes, at ratios of around 10:1." って書いてある
- 参照データは全てメモリ内(ヒープ)に保持している
- 高可用性
- 単一障害点は存在しない
- 厳密なデータ整合性
- 大規模なデータを保持するようには設計されていない
ZooKeeperのデータモデル
ZooKeeperのデータはツリー型(階層構造)のインメモリデータベースに保持される
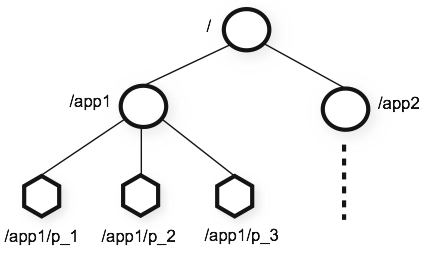
znode
- ZooKeeperではノードのことをznodeと呼ぶ
- znodeにはデータを格納できる
- 基本的には数バイト〜数キロバイト程度の小さなデータを格納する想定
- 1つのznodeに格納できるデータは最大1MB
- ZooKeeperという名前は予約語なのでznodeの名前には使用できない
- znodeのパスは /node1/node1-1/node1-1-1 のように / 区切りで記述する
- ルートノード名は /
- "."や".."のような相対パス指定は不可能
一時ノード(ephemeral nodes)
- ZooKeeperクラスタ−クライアント間の通信セッションが接続されている間だけ存在するznode
- 一時ノードを作成したクライアントからのセッションが終了すると、そのznodeは削除される
- 一時ノードには子ノードを作成できない
シーケンシャルznode
- シーケンシャルフラグを有効にしてznodeを生成すると、名前の末尾にインクリメンタルカウンタの値が付与される
- /a/b- という名前でznodeを生成すると、実際に生成されるzondeは /a/b-1 や /a/b-2 のようになる
- シーケンシャルznodeを生成する際、慣例的にパスの末尾を - とする(やらなくても良い
- カウンタの値は親ノードが内部的に保持する
ACL(Access Control List)
- znodeは生成時にACLを指定して、細かなアクセス制御をかけることができる
Watcher
- クライアントはznodeに対してWatcherを設定することができる
- Watcherが設定されたznodeで変更が発生すると、Watcherを登録したクライアントでトリガが起動される
- 一度通知されると、そのWatcherは削除される
一貫性(データ整合性の保証)
- Sequential Consistency(順序一貫性)
- クライアントからほぼ同時に更新が行われても、クラスタ側では必ず送信された順に更新内容が適用される
- ただし更新の直後・ほぼ同時に参照されたとしても、最新データが読み出せることは保証していない(これを回避するAPIは用意されている)
- Atomicity(アトミック性)
- 更新処理は必ず成功か失敗のどちらかとなる
- Single System Image
- クラスタ上のどのサーバに接続していても、必ず同一のデータを参照できる
- Reliability (耐久性、信頼性)
- いったん更新が適用されたら、その内容は必ず保存され、取り消すことはできない
- サーバが障害などで停止したとしても、再起動すればデータは復元される
- Timelines
- クラスタ上のどのサーバに接続してもある程度(数十秒程度、設定に依存)新しいデータを参照することが保証される
ZooKeeperの内部実装
基本的な考え方
- 更新時の整合性を保つため、更新処理は必ず1台のリーダー(マスタサーバ)がコントロールする
- znodeツリーはリーダーから追従者(スレーブサーバ)にレプリケーションされる
- 全てのサーバで同一のznodeツリー(データセット全体)をオンメモリで保持する
- アンサンブル(クラスタ)中の過半数のサーバが稼動している限りサービスは稼働する
- 5ノードのアンサンブルであれば、2ノードまでは落ちても大丈夫
- 6ノードのアンサンブルの場合、2ノードまでしか落とせないので注意
- 1/2は過半数とはみなされない
- もしネットワーク障害で3台-3台に分割されてしまった場合、どちらもサービスが死んでしまう!
- 必ず奇数台でノードでアンサンブルを構成する
- 2台でアンサンブルを構成しても全く意味が無い・・っ!
Zab(ZooKeeper Atomic Broadcast)プロトコル
- ZooKeeper独自プロトコル
- 「完全に順序保証されたシンプルなブロードキャストプロトコル」
- 次の2つのフェーズで実行される
リーダーの選出
- アンサンブル中からリーダーを選出する
- リーダーが選出されるとリーダーと追従者の状態を同期を行う
- 過半数の追従者が同期完了した時点で、リーダー選出フェーズを終了する
- リーダー選出は非常に高速、200msec程度
- リーダーに障害が発生した場合は再度リーダーの選出が行われる
- リーダーの再選出後にノードが復帰すると追従者となる
アトミックブロードキャスト
- (追従者)クライアントから更新リクエストを受け取る
- (追従者)更新リクエストをリーダーに転送する
- (リーダー)更新内容を追従者にブロードキャストする
- (追従者)更新内容を保存し、リーダーへ通知する
- (リーダー)過半数の追従者が更新できたことを検知したら、更新内容をコミットする
- (リーダー)クライアントへ更新成功のレスポンスを返す
トランザクションログとスナップショット
- ZooKeeperはサービス復帰の際、トランザクションログとスナップショットを使ってデータを復旧する
- トランザクションログ
- データ更新操作のログ
- スナップショット
- ある時点でのznodeツリーのメモリダンプ
- トランザクションログが一定サイズ(デフォルト64MB)を超えるか、一定回数(デフォルト100,000回)書きこまれると、スナップショットを作成する
セッション
- クライアントからZooKeeperサービスに接続する際、アンサンブルのノードリストを渡すようになっている
- クライアントはノードリストから1台を選択し、セッションをオープンする
- 接続中のノードに障害が発生してTCPコネクションが切れた場合、ノードリストから別のノードを選択し、自動的に再接続を行う
- APIレベルで見ると、セッションはアクティブなままと扱われる
tick
- ZooKeeperの処理における基準となる時間単位・期間(初期設定では2000msec)
- データ更新やセッションタイムアウトなどはtickによる仮想クロックをベースに制御する
- 複数のサーバで内部クロックをまったく同一にすることは不可能なので、実クロックで制御することはありえない
インストール
インストール(スタンドアロン)
- Java6のインストール
- http://hadoop.apache.org/zookeeper/releases.html#D... からバイナリをダウンロードして展開
- 執筆時点の最新版は3.3.2
- cp conf/zoo_sample.cfg conf/zoo.cfg
- zoo.cfgのdataDirを任意のパスに修正
- 例 dataDir=/var/zookeeper/server1/data
- bin/zkServer でサービスが起動する
コマンドラインツール(対話環境)
- bin/zkCliを使う
- 定義されていないコマンドを入力するとコマンドリストが表示される
- zkCliの起動
- bin/zkCli
- znodeの作成
- create path data
- 例 /test aaa
- 子ノードの取得
- ls path
- 例 ls /
- zkCliの終了
- quit
クラスタの構築
- スタンドアロンとの違いはzoo.cfgに server.n=hostname:port:port を追加するだけで良い
- server.1=192.168.1.1=2888:3888
- server.2=192.168.1.2=2888:3888
- server.3=192.168.1.3=2888:3888
- 1つ目のポートはリーダー時の追従者接続用、2つ目のポートはリーダー選出時の接続用
- 前述したとおりだが、アンサンブルのノード台数は奇数になるようにする
運用時の設定ポイント
- スナップショットとトランザクションログは古いデータが自動的に削除されるわけではないので、定期的に削除する必要がある
- アンサンブルのノード数を動的に追加・削除することはできない
- zoo.configの設定変更→サービス再起動が必要
- いちおう動的に変更できるようにする意思はあるようだが、実装時期は不明 https://issues.apache.org/jira/browse/ZOOKEEPER-10...
- zoo.configの詳細な設定内容についは http://hadoop.apache.org/zookeeper/docs/current/zo... を参照
- リーダーは負荷が高くなりやすいため、サーバ台数が3台以上の場合はzoo.configでleaderServes=noと設定すると、クライアントがリーダーへ接続できなくなる
- こうすることでリーダーが更新処理のみに注力できる
- サービスの監視が必要な場合はJMXを利用可能
- JVMのヒープサイズはスワップアウトしないようなサイズを指定する
- スワップアウトしてしまうとパフォーマンスが大きく劣化してしまう
APIの概要
ZooKeeperクライアントライブラリが用意されている言語
- Java
- ZooKeeper自体がJavaで書かれてるし当然
- C言語(contrib)
- Perl, Python(contrib)
- 実体はC言語バインディング
- Ruby(GitHub)
- .NET(GitHub)
基本API
| create | znodeの生成 |
| delete | znodeの削除 |
| exists | znodeの存在判定、存在する場合はメタデータの取得 |
| getChildren | 子ノードのリストを取得, リストは必ず昇順ソートされている |
| getData, setData | znodeのデータ取得・設定 |
| getACL, setACL | znodeのACL取得・設定 |
| sync | データの更新操作が(クライアントが接続中の)クラスタノードに伝搬するまで待機する |
Watcher
- getData(), getChildren(), exists() のパラメータとしてWatcherを指定できる
getData()で設定したWatcherで検知できるイベント
- NodeDeleted
- NodeDataChanged
getChildren()で設定したWatcherで検知できるイベント
- NodeChildrenChanged
- NodeDeleted
exists()で設定したWatcherで検知できるイベント
- NodeCreated
- NodeDeleted
- NodeDataChanged
ACL
getACL(), setACL()で取得・設定する
識別照明(認証方法)
| digest | ユーザ名/パスワードで制御 |
| host | ホスト名で制御 |
| ip | IPアドレスで制御 |
パーミッション
| CREATE | 子ノードの生成可否 |
| READ | データ、子ノードの読取可否 |
| WRITE | データの書込可否 |
| DELETE | 子ノードの削除可否 |
| ADMIN | ACLの設定可否 |
実装例
同期的にZooKeeperサービスへ接続
- ZooKeeperクラスはnewすると自動的にサービスへ接続しに行くが、非同期で接続処理を行う
- これでは非常に使いづらいため、java.util.concurrent.CountDownLatchを使い、接続完了するまで処理を待ち合わせる
- この例では、サービスに接続できなかったケースに対応していない(ずっと待機する)
- Timerを利用して一定時間待っても接続されない場合は接続を打ち切ってExceptionを投げるようにすると良い
import org.apache.zookeeper.ZooKeeper
import org.apache.zookeeper.Watcher
import org.apache.zookeeper.WatchedEvent
import java.util.concurrent.CountDownLatch
class ZkConnectionHelper {
static def ZooKeeper connect(String hosts, int timeout) {
def lock = new CountDownLatch(1)
def zk = new ZooKeeper(hosts, timeout, new Watcher() {
def void process(WatchedEvent event) {
if (event.state == KeeperState.SyncConnected) {
lock.countDown()
}
}
})
lock.await() //接続されるまで(lock.countDown()が呼ばれるまで)処理を止める
return zk
}
}
Queue, Priority Queue, Barriers
Primitive Counter
- CAS(Compare-and-Swap)でカウンタを実現する
- CASとは?
import java.nio.ByteBuffer
import org.apache.zookeeper.ZooKeeper
import org.apache.zookeeper.ZooDefs.Ids
import org.apache.zookeeper.CreateMode
import org.apache.zookeeper.KeeperException
class PrimitiveCounter {
private ZooKeeper zk
private String path
PrimitiveCounter(ZooKeeper zk, path) {
this.zk = zk
this.path = path
if (zk.exists(path, false) == null) {
zk.create(path, toBytes(0), Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT)
} else {
get() //既にPathが存在している場合、カウンタ用のznodeであるか確認する
}
}
def long incrementAndGet() {
def counter
while (true) {
try {
def stat = zk.exists(path, false)
if (stat == null) throw new RuntimeException()
byte[] data = zk.getData(path, false, stat)
counter = toLong(data) + 1
zk.setData(path, toBytes(counter), stat.getVersion())
break;
} catch (KeeperException e) {
}
}
return counter
}
def long get() {
def stat = zk.exists(path, false)
if (stat == null) throw new RuntimeException()
byte[] data = zk.getData(path, false, stat)
return toLong(data)
}
private def byte[] toBytes(long value) {
return ByteBuffer.allocate(8).putLong(value).array()
}
private def long toLong(byte[] value) {
return ByteBuffer.wrap(value).getLong()
}
}
cages - A distributed synchronization library for Zookeeper

このページへのコメント
Ah71zR <a href="http://bovcojljjklz.com/">bovcojljjklz</a>, [url=http://abhpovcvbqsp.com/]abhpovcvbqsp[/url], [link=http://brqhhbkayhsh.com/]brqhhbkayhsh[/link], http://zdmlnbyrrhxr.com/