
NetCDF 
インストール
最新版はソースからコンパイルする。とりあえずaptで簡単に。
sudo apt-get install netcdf-bin libnetcdf-dev
Grib
中身を確認する。
$ wgrib hogehoge.grib
バイナリファイルとして書きだす。
grib形式のファイルはwgribコマンドを使って4バイトバイナリファイルに書き換えることができる。grepコマンドやcalコマンドを使えば必要な変数のみを抜き出すこともできる。バイナリファイルはFortran等で計算するのに便利である。
- 全てのデータをヘッダーなしバイナリとして出力する。
$ wgrib pgb.201008 -d all -nh -o pgb.201008.bin
- ジオポテンシャル高度(HGT)のみを抜き出してヘッダーなしバイナリで出力。地表(sfc)の値は配列が異なるのでvオプションで除く。
$ wgrib pgb.201008 | grep :HGT: | grep -v sfc | wgrib -nh -i pgb.201008 -o pgb.201008.bin
- ジオポテンシャル高度(HGT)と気温(TMP)を抜き出してヘッダーなしバイナリで出力。
$ wgrib pgb.201008 | egrep ":HGT:|:TMP:" | grep -v sfc | wgrib -nh -i pgb.201008 -o pgb.201008.bin
- HGTのデータの後ろにTMPのデータの入ったバイナリをつくる。
$ wgrib pgb.201008 | grep :HGT: | grep -v sfc | wgrib -nh -i pgb.201008 -o pgb.201008.bin $ wgrib pgb.201008 | grep :TMP: | grep -v sfc | wgrib -nh -i pgb.201008 -append -o pgb.201008.bin注意
- 複数の変数をegrepで抜き出したり、すべてのデータを出力した場合は変数の格納順はもとのgribファイルの順番になる。例えばNCEP/DOE再解析データの場合2000年を境に格納順が変わっているので注意が必要。この場合はgrepで1変数ずつ抜き出してappendオプションやcatでつなげるのが確実。
GrADSバイナリ
GrADSで読む
ctlファイルを作って読み込む。
Fortranで読み書き
GrADSでは時間ごとの各物理量が経度、緯度、鉛直の情報をもって入っている。鉛直の情報は必ずしもなくてもよい(例えば地表気圧や可降水量などは 鉛直レベルはない)が時間、経度、緯度の情報は必ず持たなければならない。
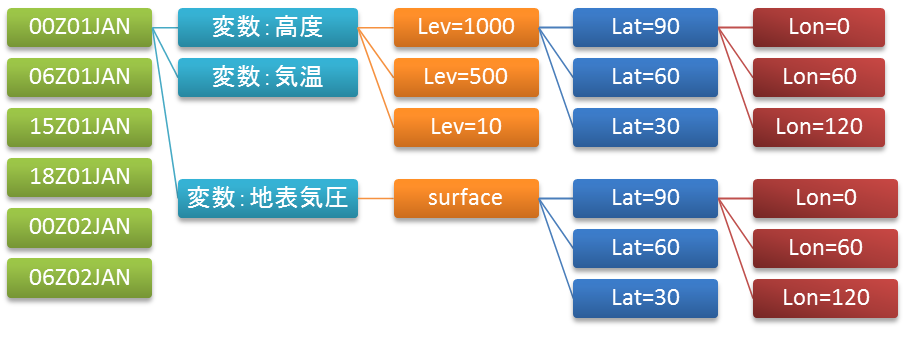
鉛直1層が1レコードになるように4バイトバイナリで読み書きすればよい。 すなわちレコード長は4×経度格子数×緯度格子数で読み書きする。Fortranで書き込むときの配列は、
鉛直1層が1レコードになるように4バイトバイナリで読み書きすればよい。 すなわちレコード長は4×経度格子数×緯度格子数で読み書きする。Fortranで書き込むときの配列は、
u(lat, lon, lev)の形の配列が時間-変数の階層で入るようにする。
- 読み込み
INTEGER, PARAMETER :: nlon=144, nlat=75, nlev=13, ntim=12 REAL :: data(nlon, nlat, nlev, ntim) OPEN(11, FILE="hogehoge.bin", ACCESS="direct", FORM="unformatted", RECL=4*nlon*nlat*nlev*ntim) READ(11, REC=1) data CLOSE(11)intel fortranの場合標準でのダイレクトアクセスは要素で数えるので -assume byterecl オブションをつけること。GrADSで読む前にls -lコマンド等でデータセットの大きさを確認する。
(データセットのサイズ)= (東西格子数)×(南北格子数)× {(変数1の鉛直格子数)+ (変数2の鉛直格子数)+ …} × 4バイト
になっているはずである。バイナリファイルの値も確認したければodコマンドを使う。$ od -t f4 pgb.200608.bin <--4バイト浮動小数点を10進数表示 0000000 2.600000e+01 2.600000e+01 2.600000e+01 2.600000e+01 * 0001100 2.100000e+01 2.200000e+01 2.300000e+01 2.400000e+01 0001120 2.400000e+01 2.500000e+01 2.600000e+01 2.700000e+01 0001140 2.800000e+01 2.900000e+01 3.000000e+01 3.100000e+01 0001160 3.200000e+01 3.300000e+01 3.400000e+01 3.500000e+01 0001200 3.600000e+01 3.600000e+01 3.700000e+01 3.800000e+01 0001220 3.900000e+01 3.900000e+01 4.000000e+01 4.000000e+01出力結果の見方を一応記しておく。詳しくはodコマンドについてメモる予定。
- 一番左はアドレスを8進数で記したもの。上記の例では4バイトの数字が4つで1行なので16バイトで1行分。8進数でバイトを表せば1行20(8×2)バイトになる。
- 2列目からが数字を表す。0001100番地に21、0001104番地に22、0001110番地に23、0001114番地に24ということ。
- アスタリスクは同じデータが連続して入っているため省略したことを表す。つまり0000020番地から0001174番地まで26が連続して入っているということ。
他形式に変換する。
lats4dが便利。こちらが参考になる。
ctlファイルをつくる。
grib2ctl.plとgribmapを使う。
gribファイルの場合はgrib2ctl.plを使ってctlファイルを作り、gribmapでidxファイルを作る。idxファイルはgrib形式のファイルを直接見るのに必要(バイナリでは不要)。
$ grib2ctl.pl pgb.201008 > pgb.201008.ctl $ gribmp -e -i pgb.201008.ctl
ctlファイルを自作する。
バイナリファイルの場合はデータセットに合わせてctlファイルを作らなければならない。grib2ctl.plで作ったctlファイルを適当に書き換えればよい。
| dset | データセットのファイル名 | ctlファイルを使いたいデータセットのファイル名に書き換える。optionsでtemplateを使って複数のファイルをまとめて一つのファイルに書くこともできる。 |
|---|---|---|
| index | idxファイル名 | grib、grib2形式のデータを読むのに必要なgribmapで作成するidxファイル名。任意でよい。バイナリ形式を使うときは必要ないのでコメントアウトか削除しておく。 |
| undef | 欠損値・未定義値 | 一致した値を欠損値として無視する。欠損値が無くても指定する。 |
| title | タイトル | GrADSのqueryで表示されるファイル名。 |
| dtype | データセットのファイル形式 | データセットのファイル形式を指定する。grib2形式(NCEP/DOE)ならgrib 2、バイナリならばdtypeは指定しないので削除かコメントアウトする。 |
| options | オプション | yrev(緯度方向のデータが北側から入っている場合)、zrev(鉛直方向のデータが上層から入っている場合)、template(複数のデータセットをまとめて扱う場合)など。 |
| xdef,ydef,zdef | 東西、南北、鉛直方向の格子情報。 | 格子点、鉛直層の情報を記述する。 |
| tdef | 時系列情報 | データの時系列情報を記述する。時間間隔の単位はmn(分)、hr(時間)、 dy(日)、mo(月)、yr(年)である。 |
| vars | 変数の種類 | vars以下に記述する変数の種類数を指定する。 |
| 変数名 | 変数の情報 | 変数の鉛直レベル等の情報を記述する。 |
| endvars | 終点 | ctlファイルの終わり。以下は何も書いてはいけない。 |
格子情報・時系列情報の記述。
等間隔で格子情報が格納されている場合はlinearで記述する。
xdef 格子点数 linear 開始緯度 格子間隔例
xdef 144 linear 0.000000 2.500000 <---東経0度から2.5度間隔で144格子 tdef 384 linear jan1979 1mo <---1979年1月から1か月ずつ384か月分指定した高度や緯経度の場合はlevelsで記述する。
zdef levels 高度1 高度2 …例
zdef 17 levels 1000 925 850 700 600 500 400 300 250 200 150 100 70 50 30 20 10
変数名の記述
変数名(GrADSの描画での変数名)とその鉛直レベルを記述する。ユニットの情報はgrib形式を読む際に必要なのでgrib2ctl.plで得られたものを流用するのがよい。バイナリ形式なら意味はないので適当な値(99など)にしておく。地表気圧など鉛直レベルがない変数の鉛直レベルは0にする。変数は格納されている順に記述していく。
vars 変数の種類数 変数1 鉛直レベル ユニット 変数1の説明 変数2 鉛直レベル ユニット 変数2の説明 変数2 鉛直レベル ユニット 変数2の説明 … ENDVARS例
vars 2 ABSVprs 17 41,100,0 ** Absolute vorticity [/s] PRESsfc 0 1,1, 0 ** surface Pressure [Pa] ENDVARS
複数ファイルを1つのctlファイルで扱う。
連続した時系列が複数ファイルに分かれている場合
ctlファイルのオプションにtemplateオプションを付け加えれば複数のデータファイルを1つのctlファイル、idxファイルで扱える。データセットを年月日や時間の分かる名前にする。例えば2010年8月のデータなら"pgb.201008"、1993年7月21日のデータなら"21jul93.dat"などとする。ctlファイルのdsetの項目で年月日や時間の部分を以下のような変数に変えてかく。詳細は GrADS本家のページを参照。
ファイル名が"pgb.201008"、"pgb.201007"であれば"pgb.%y4%m2"となり、"21jul93.dat"、"25aug94.dat"等であれば "%d2%mc%y2.dat"となる。時系列情報tdefの初期値、時間間隔をデータセットに合わせて書けばOK。
例:1979-2010年の月平均データをまとめて読む
| %y4 | 4桁の年 |
|---|---|
| %m2 | 2桁の月 |
| %mc | 3文字の月 |
| %d2 | 2桁の日付 |
例:1979-2010年の月平均データをまとめて読む
dset ^pgb.anl.%y4%m2.avrg.grib index ^pgb.anl.avrg.grib.idx *---ここは適当に決めてgribmapすればよい。 … options yrev template … tdef 384 linear jan1979 1mo *---1ヵ月ごとに1979年1月から12*32=384個のデータ
時系列が連続していない場合
例えば6,7月の連続したデータが数年分ある場合、上記の方法だと使わないデータまで用意しなければならず無駄が多い。またプログラムでの処理においても月毎に分けるのは都合が悪い。
この場合は少し変則的だがアンサンブルの次元を使う。すなわち時系列(例えば6月15日-9月15日)は同じデータが年毎に分かれているときは以下のようにctlファイルをつくればいい。
この場合は少し変則的だがアンサンブルの次元を使う。すなわち時系列(例えば6月15日-9月15日)は同じデータが年毎に分かれているときは以下のようにctlファイルをつくればいい。
dset ^hgt500.%e.bin options template undef 9.9999e+20 title NCEP/NCAR Reanalysis daily pressure xdef 49 linear 80.0 2.5 ydef 29 linear 0.0 2.5 zdef 1 levels 500 tdef 92 linear 15jun1974 1dy edef 10 names 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 vars 1 hgt 1 0 ** geopotential height endvars描画するときは
ga-> set ens 2001 ga-> set time 01jul1974で2001/7/1を指定できるし、年平均はアンサンブル平均を使って、
ga-> d ave(hgt, e=1, e=10)とすればcalender dayにおける10年気候値を作成できる。

最新コメント