
統計関係ならR最強なのだがPythonでもけっこうできるみたい。NumPyのindexingが便利なのでなれると結構使えるかも。r2pyを使ってPythonからRを使う手もある。
ライブラリ一覧
NumPyのメソッド(初等統計)
連続分布
離散分布
統計関数
平均・分散
検定
主な検定
一群のt検定
Contingency table functions
General linear model
Plot-tests
Masked statistics functions
カーネル密度推定
PDFの計算とプロット
ライブラリ一覧 
NumPyのメソッド(初等統計)
連続分布
t分布、ベータ分布など84種類が用意されている。主な使い方は2つある。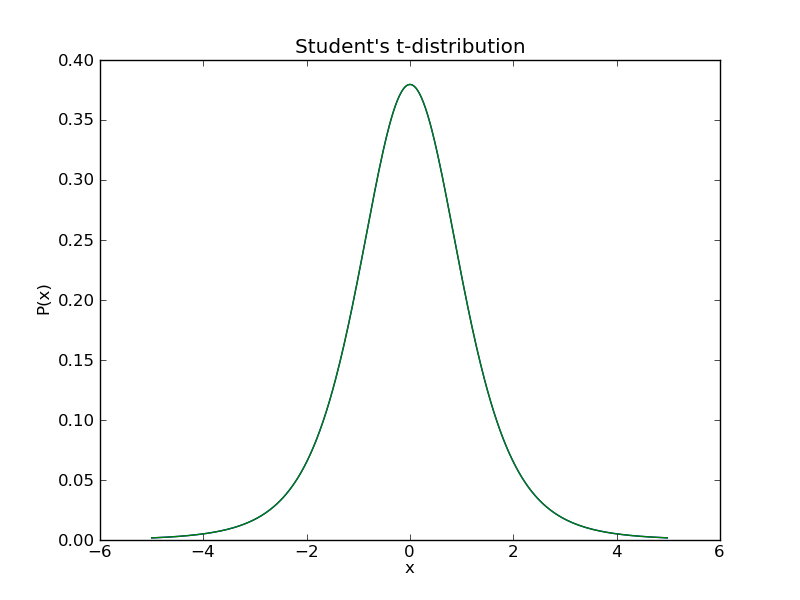
主なメソッド。分布関数はパラメータloc、scaleで正規化される。自由度などパラメータを引数またはインスタンス生成時の引数に必要とする関数もある。
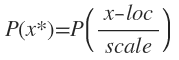
- メソッドを直接関数として使う。
- 分布関数のインスタンスを作ってメソッドを呼び出す。
import scipy.stats as stats x = np.arange(-5,5,0.02) #t分布の確率密度関数をプロット。pdf(値,自由度) plt.plot(x, stats.t.pdf(x,5)) #先に自由度5のt分布のインスタンスを作る場合 t_distr = stats.t(5) plt.plot(x, t_distr.pdf(x))
主なメソッド。分布関数はパラメータloc、scaleで正規化される。自由度などパラメータを引数またはインスタンス生成時の引数に必要とする関数もある。
| rvs(loc=0,scale=1,size=1) | 乱数の生成 |
|---|---|
| pdf(x,loc=0,scale=1) | 確率密度関数 |
| cdf(x,loc=0,scale=1) | 累積密度関数 |
| sf(x,loc=0,scale=1) | 生存時間関数(累積生存率)。1-cdfに等しい |
| ppf(x,loc=0,scale=1) | パーセント点関数。cdfの逆関数。 |
| iisf(x,loc=0,scale=1) | 生存時間関数の逆関数 |
| stats(x,loc=0,scale=1,moments='mv') | モーメント統計量。平均(m)、分散(v)、歪度(s)、尖度(k)が指定できる。リストで返る。 |
離散分布
ベルヌーイ分布、ポアソン分布など13種類がある。基本は連続分布の関数と一緒。ただしpdfメソッドがpmfメソッドに置き換わっている。
| pmf(x,loc=0) | 確率質量関数 |
|---|
統計関数
numpyにある初等統計関数に加え豊富な統計関数が用意されている。
平均・分散
| gmean | 相乗平均 |
|---|---|
| hmean | 調和平均 |
| cmedian | 中央値 |
| tmean/tvar/tmin/tmax/tstd/tsem | トリム平均など |
検定
主な検定
| メソッド | 説明 | Rとの対応 |
|---|---|---|
| ttest_1samp(x, m) | xの平均に対する1群のt検定 | t.test(x,mu=m) |
| ttest_ind(x,y) | 対応のない2群の平均の差に対するt検定(Welchのt検定?) | t.test(x,y,var.equal=TRUE) |
| ttest_rel | 対応のある(等分散)2群の平均の差に対するt検定 | |
| kstest(rvs, cdf) | コルモゴロフ-スミノフ検定。rvsとcdfのずれを検定。cdfは分布関数を指定? 't':t分布。'norm':正規分布など | |
| ks_2samp(data1,data2) | 2群のコルモゴロフ-スミノフ検定 |
一群のt検定
- 例 母集団の平均値が0であるという帰無仮説を両側t検定
>>> y = np.array([1.9, 0.8, 1.1, 0.1, -0.1, 4.4, 5.5, 1.6, 4.6, 3.4]) >>> stats.ttest_1samp(y, 0.0) (3.6799158947951889, 0.0050761326497724005) #データのt値:3.6799158947951889 #p値:0.0050761326497724005 #すなわちデータの平均が0となる確率は0.5%以下。
Contingency table functions
General linear model
Plot-tests
Masked statistics functions
カーネル密度推定
scipy.stats.gaussian_kdeクラスを使う。
PDFの計算とプロット
ガウス型のカーネル密度関数によるPDFを計算する。ver0.10ではバンド幅の推定はScottの経験則による推定のみのようだが、ver0.11からはSilvermanの経験則による推定や値の指定が可能になるようである。
(追記)ドキュメントの例の通りにするとなんか結果がおかしい。以下のとおりやるのがいいと思われる。
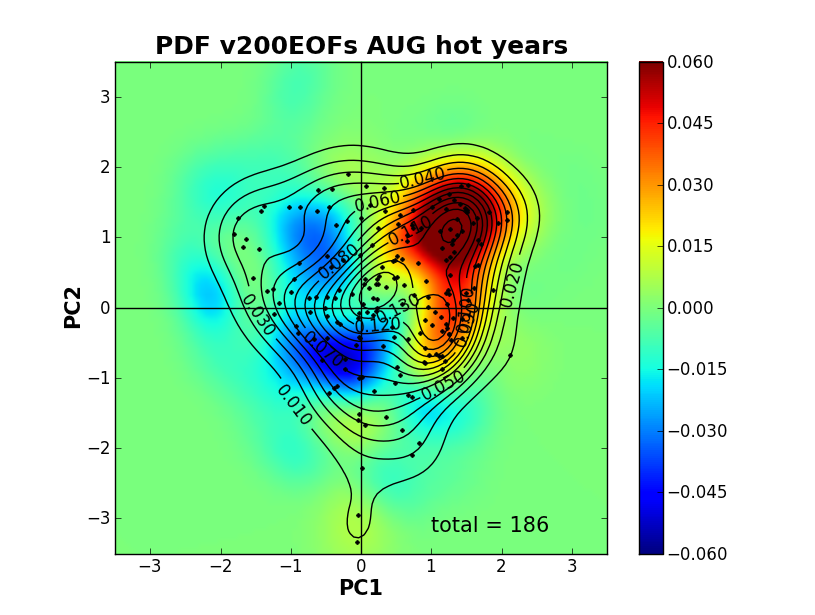
(追記)ドキュメントの例の通りにするとなんか結果がおかしい。以下のとおりやるのがいいと思われる。
import numpy as np
import scipy.stats as stats
import matplotlib.pyplot as plt
#最大最小値
xmin = x.min()
xmax = x.max()
ymin = y.min()
ymax = y.max()
#グリッド,100分割
X, Y = np.mgrid[xmin:xmax:100j, ymin:ymax:100j]
#1次元にする
positions = np.vstack([X.ravel(), Y.ravel()])
#データ
values = np.vstack([x,y])
#カーネルを計算。stats.gaussian_kdeクラスのオブジェクトが返される。
kernel = stats.gaussian_kde(values)
#stats.gaussian_kde(配列)与えられた点でのカーネル密度を返す
Z = np.reshape(kernel(positions), X.shape)
fig = plt.figure()
ax = fig.add_subplot(111)
ax.axhline(linewidth=1,color='black')
ax.axvline(linewidth=1,color='black')
#コンターを引く
cs=ax.contour(np.rot90(Z),np.arange(0,1,0.01),colors='black',extent=[xmin,xmax,ymin,ymax])
plt.clabel(cs,fontsize=12,inline=1)
#カラーをつける。デフォルトのoriginがcontourと異なるので指定する。
imgplot=plt.imshow(Z,extent=[xmin, xmax, ymin, ymax],origin='lower',vmin=-0.06,vmax=0.06)
imgplot.set_cmap(cm.jet)
plt.colorbar()
#点をプロットする
ax.plot(x,y,'k.',markersize=2)
ax.axis([xmin,xmax,ymin,ymax])
plt.xlabel("PC1")
plt.ylabel("PC2")
plt.title("PDF v200EOFs AUG hot years")
plt.show()

最新コメント