Solr/Tokenizer評価201105/NGramTokenizer(bi-gram)
最終更新:
 haruyama_seigo 2011年05月17日(火) 12:46:16履歴
haruyama_seigo 2011年05月17日(火) 12:46:16履歴
Lucene/Solr のNGramTokenizer (minGramSize="2" maxGramSize="2")
測定結果
Solr 3.1.0
Solr 1.4.1
設定
Tokenizeサンプル
Solr 3.1.0

Solr 1.4.1
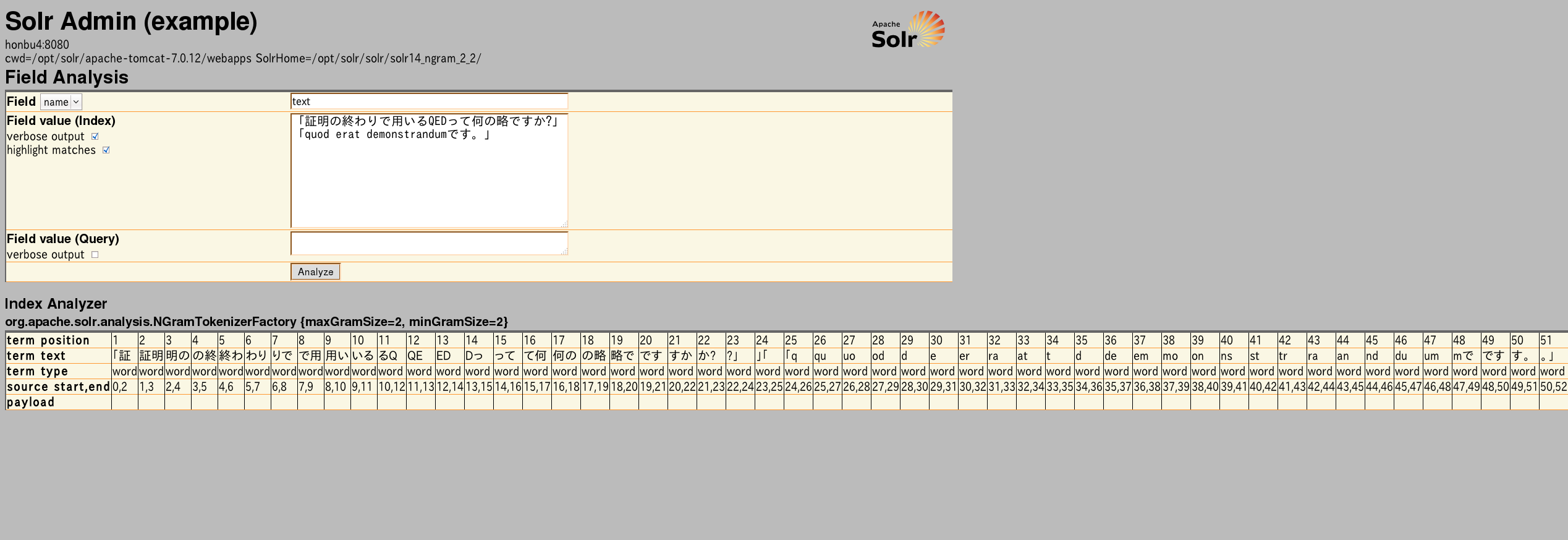
- いわゆるbi-gram
- SolrのWikiには記述がない
- NGramTokenizerは1024文字までしか処理しない. 利用したデータには1024文字以上の項目が多数あるのですべてがインデックスされていない.
測定結果 
Solr 3.1.0
| 回数 | 時間(QTime,ms) | インデックスサイズ(byte) |
| 1 | 557705 | 7249587986 |
| 2 | 557403 | 7249587986 |
| 3 | 549028 | 7249587986 |
Solr 1.4.1
| 回数 | 時間(QTime,ms) | インデックスサイズ(byte) |
| 1 | 563992 | 7251645357 |
| 2 | 583273 | 7251645357 |
| 3 | 554795 | 7251645357 |
設定
schema.xml
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.NGramTokenizerFactory" minGramSize="2" maxGramSize="2"/>
</analyzer>
</fieldType>
Tokenizeサンプル
「証明の終わりで用いるQEDって何の略ですか?」「quod erat demonstrandumです。」のTokenize
Solr 3.1.0
Solr 1.4.1
- カテゴリ:
- インターネット
- インターネットセキュリティ
最新コメント