
サンプルデータ 
ここでは y = x^2 についてノイズ入りのデータを生成してみる。
set.seed(0) d = list() d$x = 1:10 ; d$x = d$x + rnorm(length(d$x)) d$y = (1:10)^2; d$y = d$y + rnorm(length(d$y))
> d $x [1] 2.262954 1.673767 4.329799 5.272429 5.414641 4.460050 6.071433 7.705280 8.994233 12.404653 $y [1] 1.763593 3.200991 7.852343 15.710538 24.700785 35.588489 49.252223 63.108079 81.435683 98.762462
曲線の描画
近似式の左辺値を推定するために必要な右辺値を適当な密度で生成して predict() に与えることで近似式に当てはめた左辺値を生成し、それらを lines() 等に与えると良いらしい。
詳細は、以後のサンプルを参照。
詳細は、以後のサンプルを参照。
lm() を使う方法
lm() は Fitting Linear Models つまり線形モデルによる近似を行うらしい。
formula に近似式、data にデータを与える。
近似式の与え方は ~ の仕組みが良く分かってないのだが、与えられた data の項目を ~ で左辺と右辺に分けて与えると、右辺の N 次式に対して左辺の値を求めるために適当な係数が得られる。
lm() の場合、近似式には係数を与える必要はないようだが、高次の項は I(x^2) のようにラップしておかないとなぜかすべて一次の項として扱われ一次の項の係数しか得られない。
また、ゼロ次の項が必ず入ってしまうようで、これをネグる方法が分からない。
この辺りの話は、どこかに解説があるはずなので要捜索。
あとは lm() の結果と右辺で用いたパラメータに割り当てる値を predict() に与えると、それらを近似式に当てはめた際の左辺値が得られる。
以下の例では、d$x の最小値から最大値までの間に 100 点生成して lm() の結果と共に predict() へ与えることで、近似曲線を描くのに十分な数の点列を得て lines() で描画している。
data に与えるのは data.frame() の方が良い気もするのだが、回帰分析の結果も一緒に放り込んでおきたいので、list() にしてパラメータ名を揃えて放り込むことで手間を省いている。
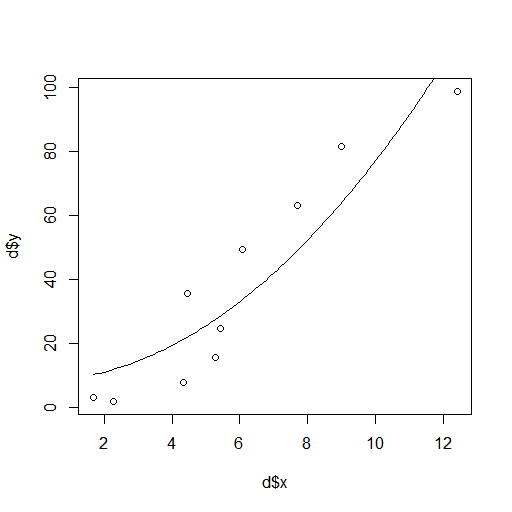
formula に近似式、data にデータを与える。
近似式の与え方は ~ の仕組みが良く分かってないのだが、与えられた data の項目を ~ で左辺と右辺に分けて与えると、右辺の N 次式に対して左辺の値を求めるために適当な係数が得られる。
lm() の場合、近似式には係数を与える必要はないようだが、高次の項は I(x^2) のようにラップしておかないとなぜかすべて一次の項として扱われ一次の項の係数しか得られない。
また、ゼロ次の項が必ず入ってしまうようで、これをネグる方法が分からない。
この辺りの話は、どこかに解説があるはずなので要捜索。
あとは lm() の結果と右辺で用いたパラメータに割り当てる値を predict() に与えると、それらを近似式に当てはめた際の左辺値が得られる。
以下の例では、d$x の最小値から最大値までの間に 100 点生成して lm() の結果と共に predict() へ与えることで、近似曲線を描くのに十分な数の点列を得て lines() で描画している。
data に与えるのは data.frame() の方が良い気もするのだが、回帰分析の結果も一緒に放り込んでおきたいので、list() にしてパラメータ名を揃えて放り込むことで手間を省いている。
d.lm = list() d.lm$obj = lm(formula = y ~ I(x^2), data = d) d.lm$x = seq(min(d$x), max(d$x), length=100) d.lm$y = predict(d.lm$obj, d.lm)
> d.lm
$obj
Call:
lm(formula = y ~ I(x^2), data = d)
Coefficients:
(Intercept) I(x^2)
8.2542 0.6875
$x
[1] 1.673767 1.782159 1.890552 1.998945 2.107338 2.215731 2.324123 2.432516 2.540909 2.649302 2.757695 2.866087 2.974480 3.082873
[15] 3.191266 3.299659 3.408051 3.516444 3.624837 3.733230 3.841623 3.950015 4.058408 4.166801 4.275194 4.383587 4.491979 4.600372
[29] 4.708765 4.817158 4.925551 5.033943 5.142336 5.250729 5.359122 5.467514 5.575907 5.684300 5.792693 5.901086 6.009478 6.117871
[43] 6.226264 6.334657 6.443050 6.551442 6.659835 6.768228 6.876621 6.985014 7.093406 7.201799 7.310192 7.418585 7.526978 7.635370
[57] 7.743763 7.852156 7.960549 8.068942 8.177334 8.285727 8.394120 8.502513 8.610906 8.719298 8.827691 8.936084 9.044477 9.152870
[71] 9.261262 9.369655 9.478048 9.586441 9.694834 9.803226 9.911619 10.020012 10.128405 10.236797 10.345190 10.453583 10.561976 10.670369
[85] 10.778761 10.887154 10.995547 11.103940 11.212333 11.320725 11.429118 11.537511 11.645904 11.754297 11.862689 11.971082 12.079475 12.187868
[99] 12.296261 12.404653
$y
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
10.18016 10.43768 10.71136 11.00120 11.30718 11.62933 11.96762 12.32207 12.69268 13.07944 13.48235 13.90142 14.33664 14.78802 15.25555
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
15.73923 16.23907 16.75506 17.28721 17.83551 18.39997 18.98058 19.57734 20.19026 20.81933 21.46456 22.12594 22.80348 23.49717 24.20701
31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
24.93301 25.67516 26.43347 27.20793 27.99854 28.80531 29.62823 30.46731 31.32254 32.19393 33.08147 33.98516 34.90501 35.84102 36.79317
46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
37.76148 38.74595 39.74657 40.76334 41.79627 42.84535 43.91059 44.99198 46.08953 47.20323 48.33308 49.47909 50.64125 51.81957 53.01404
61 62 63 64 65 66 67 68 69 70 71 72 73 74 75
54.22466 55.45144 56.69437 57.95346 59.22870 60.52010 61.82765 63.15135 64.49121 65.84722 67.21939 68.60771 70.01219 71.43282 72.86960
76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
74.32254 75.79163 77.27688 78.77828 80.29583 81.82954 83.37940 84.94542 86.52759 88.12592 89.74040 91.37103 93.01782 94.68077 96.35986
91 92 93 94 95 96 97 98 99 100
98.05512 99.76652 101.49408 103.23779 104.99766 106.77369 108.56586 110.37419 112.19868 114.03932
plot(d) lines(d.lm)
glm() を使う方法
glm() は Fitting Generalized Linear Modesls つまり、一般化線形モデルによる近似を行うらしい。
基本的には lm() と同じだが、start=c(1,1) みたいにして、係数の初期値を与えることが出来たり、他にも一般化とついてるだけあっていろいろと設定ができるようだ。
このくらい単純な例だとあまり有難味はなさそう。

基本的には lm() と同じだが、start=c(1,1) みたいにして、係数の初期値を与えることが出来たり、他にも一般化とついてるだけあっていろいろと設定ができるようだ。
このくらい単純な例だとあまり有難味はなさそう。
d.glm = list() d.glm$obj = glm(formula = y ~ I(x^2), data = d) d.glm$x = seq(min(d$x), max(d$x), length=100) d.glm$y = predict(d.glm$obj, d.glm)
> d.glm
$obj
Call: glm(formula = y ~ I(x^2), data = d)
Coefficients:
(Intercept) I(x^2)
8.2542 0.6875
Degrees of Freedom: 9 Total (i.e. Null); 8 Residual
Null Deviance: 10450
Residual Deviance: 1646 AIC: 85.41
$x
[1] 1.673767 1.782159 1.890552 1.998945 2.107338 2.215731 2.324123 2.432516 2.540909 2.649302 2.757695 2.866087 2.974480 3.082873
[15] 3.191266 3.299659 3.408051 3.516444 3.624837 3.733230 3.841623 3.950015 4.058408 4.166801 4.275194 4.383587 4.491979 4.600372
[29] 4.708765 4.817158 4.925551 5.033943 5.142336 5.250729 5.359122 5.467514 5.575907 5.684300 5.792693 5.901086 6.009478 6.117871
[43] 6.226264 6.334657 6.443050 6.551442 6.659835 6.768228 6.876621 6.985014 7.093406 7.201799 7.310192 7.418585 7.526978 7.635370
[57] 7.743763 7.852156 7.960549 8.068942 8.177334 8.285727 8.394120 8.502513 8.610906 8.719298 8.827691 8.936084 9.044477 9.152870
[71] 9.261262 9.369655 9.478048 9.586441 9.694834 9.803226 9.911619 10.020012 10.128405 10.236797 10.345190 10.453583 10.561976 10.670369
[85] 10.778761 10.887154 10.995547 11.103940 11.212333 11.320725 11.429118 11.537511 11.645904 11.754297 11.862689 11.971082 12.079475 12.187868
[99] 12.296261 12.404653
$y
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
10.18016 10.43768 10.71136 11.00120 11.30718 11.62933 11.96762 12.32207 12.69268 13.07944 13.48235 13.90142 14.33664 14.78802 15.25555
16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
15.73923 16.23907 16.75506 17.28721 17.83551 18.39997 18.98058 19.57734 20.19026 20.81933 21.46456 22.12594 22.80348 23.49717 24.20701
31 32 33 34 35 36 37 38 39 40 41 42 43 44 45
24.93301 25.67516 26.43347 27.20793 27.99854 28.80531 29.62823 30.46731 31.32254 32.19393 33.08147 33.98516 34.90501 35.84102 36.79317
46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
37.76148 38.74595 39.74657 40.76334 41.79627 42.84535 43.91059 44.99198 46.08953 47.20323 48.33308 49.47909 50.64125 51.81957 53.01404
61 62 63 64 65 66 67 68 69 70 71 72 73 74 75
54.22466 55.45144 56.69437 57.95346 59.22870 60.52010 61.82765 63.15135 64.49121 65.84722 67.21939 68.60771 70.01219 71.43282 72.86960
76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
74.32254 75.79163 77.27688 78.77828 80.29583 81.82954 83.37940 84.94542 86.52759 88.12592 89.74040 91.37103 93.01782 94.68077 96.35986
91 92 93 94 95 96 97 98 99 100
98.05512 99.76652 101.49408 103.23779 104.99766 106.77369 108.56586 110.37419 112.19868 114.03932
plot(d) lines(d.glm)
nls() を使う方法
nls() は Nonelinear Least Square つまり非線形最小二乗法を行うらしい。
これは、lm() や glm() と違って formula には近似式を係数込みで与え、start で係数の初期値を与える必要があるが、そのおかげでゼロ次の項をネグることが出来る。
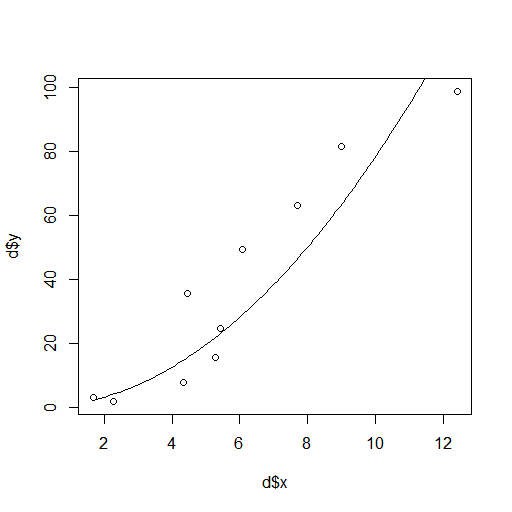
これは、lm() や glm() と違って formula には近似式を係数込みで与え、start で係数の初期値を与える必要があるが、そのおかげでゼロ次の項をネグることが出来る。
d.nls = list() d.nls$obj = nls(formula = y ~ a*x^2, data = d, start = c(a=1)) d.nls$x = seq(min(d$x), max(d$x), length=100) d.nls$y = predict(d.nls$obj, d.nls)
> d.nls
$obj
Nonlinear regression model
model: y ~ a * x^2
data: d
a
0.7831
residual sum-of-squares: 1984
Number of iterations to convergence: 1
Achieved convergence tolerance: 3.25e-09
$x
[1] 1.673767 1.782159 1.890552 1.998945 2.107338 2.215731 2.324123 2.432516 2.540909 2.649302 2.757695 2.866087 2.974480 3.082873
[15] 3.191266 3.299659 3.408051 3.516444 3.624837 3.733230 3.841623 3.950015 4.058408 4.166801 4.275194 4.383587 4.491979 4.600372
[29] 4.708765 4.817158 4.925551 5.033943 5.142336 5.250729 5.359122 5.467514 5.575907 5.684300 5.792693 5.901086 6.009478 6.117871
[43] 6.226264 6.334657 6.443050 6.551442 6.659835 6.768228 6.876621 6.985014 7.093406 7.201799 7.310192 7.418585 7.526978 7.635370
[57] 7.743763 7.852156 7.960549 8.068942 8.177334 8.285727 8.394120 8.502513 8.610906 8.719298 8.827691 8.936084 9.044477 9.152870
[71] 9.261262 9.369655 9.478048 9.586441 9.694834 9.803226 9.911619 10.020012 10.128405 10.236797 10.345190 10.453583 10.561976 10.670369
[85] 10.778761 10.887154 10.995547 11.103940 11.212333 11.320725 11.429118 11.537511 11.645904 11.754297 11.862689 11.971082 12.079475 12.187868
[99] 12.296261 12.404653
$y
[1] 2.193858 2.487206 2.798956 3.129107 3.477659 3.844613 4.229968 4.633725 5.055882 5.496441 5.955402 6.432764 6.928527
[14] 7.442691 7.975257 8.526224 9.095593 9.683362 10.289533 10.914106 11.557080 12.218455 12.898232 13.596410 14.312989 15.047969
[27] 15.801351 16.573135 17.363319 18.171905 18.998892 19.844281 20.708071 21.590262 22.490855 23.409849 24.347245 25.303041 26.277239
[40] 27.269839 28.280839 29.310242 30.358045 31.424250 32.508856 33.611863 34.733272 35.873082 37.031294 38.207907 39.402921 40.616337
[53] 41.848153 43.098372 44.366991 45.654012 46.959434 48.283258 49.625483 50.986109 52.365137 53.762566 55.178396 56.612628 58.065261
[66] 59.536295 61.025731 62.533568 64.059807 65.604446 67.167487 68.748930 70.348774 71.967019 73.603665 75.258713 76.932162 78.624013
[79] 80.334265 82.062918 83.809972 85.575428 87.359285 89.161544 90.982204 92.821265 94.678728 96.554592 98.448857 100.361524 102.292592
[92] 104.242061 106.209932 108.196204 110.200877 112.223952 114.265428 116.325305 118.403584 120.500264
plot(d) lines(d.nls)
参考
- R-Tips
- biostatistics / R / グラフィックス / 近似曲線
関連

タグ
コメントをかく