GNU R には標準で以下のような形式でタイタニック号乗員の Class, Sex, Age, Survived といった属性に関する 2201 件のデータが付属している。
これは table 形式でクロス集計された度数分布表である。
> Titanic
, , Age = Child, Survived = No
Sex
Class Male Female
1st 0 0
2nd 0 0
3rd 35 17
Crew 0 0
, , Age = Adult, Survived = No
Sex
Class Male Female
1st 118 4
2nd 154 13
3rd 387 89
Crew 670 3
, , Age = Child, Survived = Yes
Sex
Class Male Female
1st 5 1
2nd 11 13
3rd 13 14
Crew 0 0
, , Age = Adult, Survived = Yes
Sex
Class Male Female
1st 57 140
2nd 14 80
3rd 75 76
Crew 192 20
> is.table(Titanic) [1] TRUE
決定木(CART)による分析 
rpart パッケージを用いると CART(Classification And Regression Tree) アルゴリズムによる決定木分析が出来る。
ただし rpart で決定木分析を行うには、度数分布表ではなく乗客毎の属性値をデータフレームとして用意する必要がある。
table() 関数でクロス集計した度数分布表は、as.data.frame() 関数でデータフレームに戻せる模様。
ただし as.data.frame() 関数でデータフレームに戻した場合、重複行は行として復元されず度数として Freq 列に集計されてしまう。
このため、rpart の決定木で分析するには、Freq 列のカウントを元に、重複行として復元することで、乗客毎のデータフレームを得なければならない。
ただし rpart で決定木分析を行うには、度数分布表ではなく乗客毎の属性値をデータフレームとして用意する必要がある。
table() 関数でクロス集計した度数分布表は、as.data.frame() 関数でデータフレームに戻せる模様。
ただし as.data.frame() 関数でデータフレームに戻した場合、重複行は行として復元されず度数として Freq 列に集計されてしまう。
このため、rpart の決定木で分析するには、Freq 列のカウントを元に、重複行として復元することで、乗客毎のデータフレームを得なければならない。
乗員毎のデータフレームを復元
GNU R は不慣れなので rep() 関数を使って無理やり戻すと以下のような感じ。
大量にフィールド数がある場合、手書きすると死ねるので、もう少し簡単に書けんものかと思うが、とりあえず今回はこれでお茶を濁しておく。
2019-01-25: 追記
Map() と無名関数を使うと以下のように書けた。
1:4 と 5 はデータのフィールド数に依存するので、差集合を求める setdiff(x,y) 関数を用いて以下のように書いた方が良いだろう。
ただ、これでは、ぱっと見、何やってるかがよくわからない。
"Freq" フィールドを落とした上で、各行を "Freq" フィールドの回数重複させる、関数 deFreq(x) を作ったほうが分かり易いだろう。
大量にフィールド数がある場合、手書きすると死ねるので、もう少し簡単に書けんものかと思うが、とりあえず今回はこれでお茶を濁しておく。
Titanic.dffreq=as.data.frame(Titanic) Titanic.df=data.frame( Class =rep(Titanic.dffreq[,"Class" ],Titanic.dffreq[,"Freq"]), Sex =rep(Titanic.dffreq[,"Sex" ],Titanic.dffreq[,"Freq"]), Age =rep(Titanic.dffreq[,"Age" ],Titanic.dffreq[,"Freq"]), Survived=rep(Titanic.dffreq[,"Survived"],Titanic.dffreq[,"Freq"]) )
> Titanic.dffreq Class Sex Age Survived Freq 1 1st Male Child No 0 2 2nd Male Child No 0 ... 32 Crew Female Adult Yes 20
> Titanic.df
Class Sex Age Survived
1 3rd Male Child No
2 3rd Male Child No
...
2201 Crew Female Adult Yes
2019-01-25: 追記
Map() と無名関数を使うと以下のように書けた。
Titanic.dffreq=as.data.frame(Titanic) Titanic.df=data.frame(Map(function(x) rep(x, Titanic.dffreq[,5]), Titanic.dffreq[,1:4]))データフレームに対して Map() を用いると、行列が転置したリストになるので、改めてデータフレームに直してやる必要がある。
1:4 と 5 はデータのフィールド数に依存するので、差集合を求める setdiff(x,y) 関数を用いて以下のように書いた方が良いだろう。
Titanic.dffreq=as.data.frame(Titanic) Titanic.df=data.frame(Map(function(x) rep(x, Titanic.dffreq[,"Freq"]), Titanic.dffreq[,setdiff(names(Titanic.dffreq),"Freq")]))ここで、names() はフィールド名を得る関数、setdiff() は差集合を得る関数。
ただ、これでは、ぱっと見、何やってるかがよくわからない。
"Freq" フィールドを落とした上で、各行を "Freq" フィールドの回数重複させる、関数 deFreq(x) を作ったほうが分かり易いだろう。
deFreq = function(x) as.data.frame(Map(function(y) rep(y,x[,"Freq"]), x[,setdiff(names(x),"Freq")])) Titanic.df = deFreq(as.data.frame(Titanic))
rpart による決定木分析
上で復元した乗員毎のデータフレーム Titanic.df を用いて、以下のようにすれば良い。
決定木の描画には rpart.plot を使うのが良いようだ。
library("rpart")
library("rpart.plot")
model=rpart(Survived~., Titanic.df)
svg("titanic.svg")
rpart.plot(model,type=4,extra=1)
dev.off()
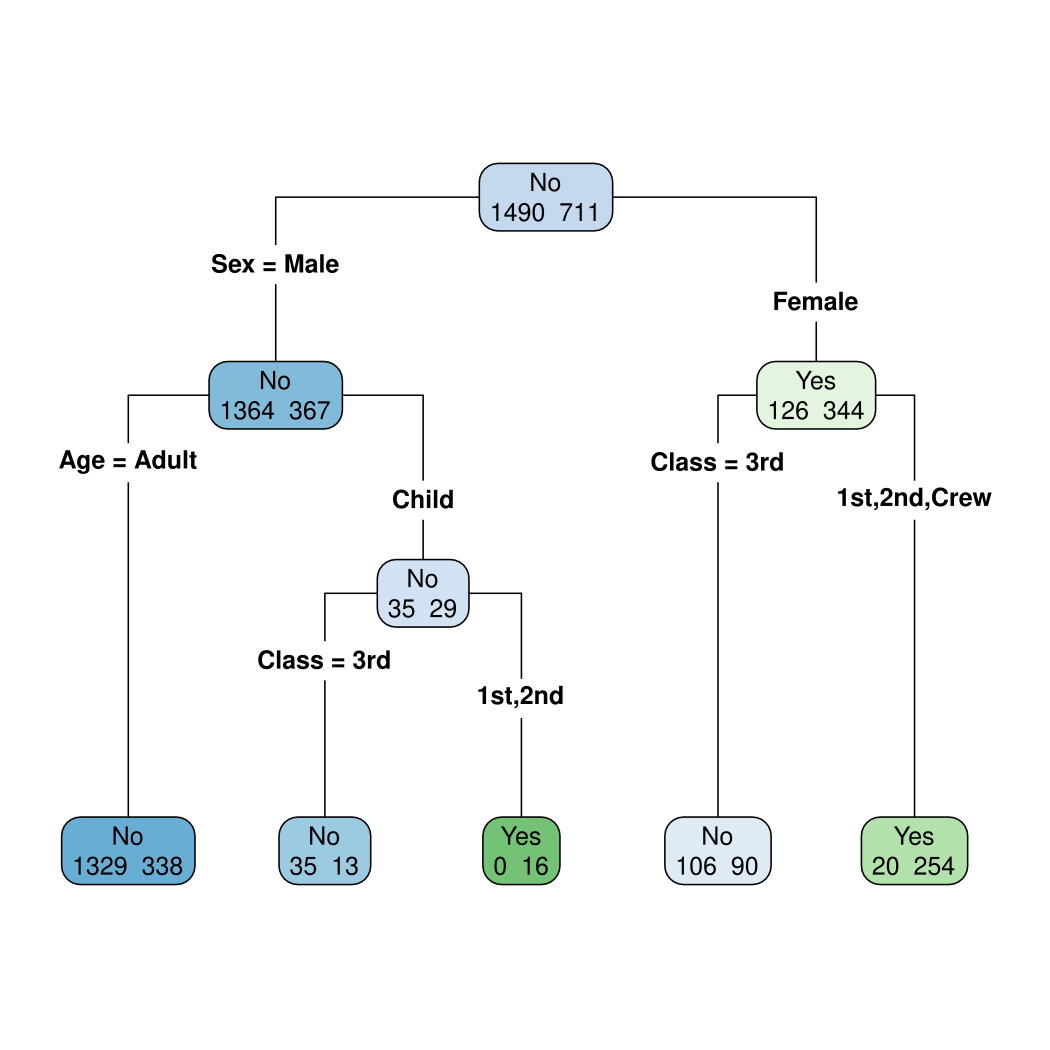
> model
n= 2201
node), split, n, loss, yval, (yprob)
* denotes terminal node
1) root 2201 711 No (0.6769650 0.3230350)
2) Sex=Male 1731 367 No (0.7879838 0.2120162)
4) Age=Adult 1667 338 No (0.7972406 0.2027594) *
5) Age=Child 64 29 No (0.5468750 0.4531250)
10) Class=3rd 48 13 No (0.7291667 0.2708333) *
11) Class=1st,2nd 16 0 Yes (0.0000000 1.0000000) *
3) Sex=Female 470 126 Yes (0.2680851 0.7319149)
6) Class=3rd 196 90 No (0.5408163 0.4591837) *
7) Class=1st,2nd,Crew 274 20 Yes (0.0729927 0.9270073) *
参考
- marketechlabo / Rで決定木分析(rpartによるCARTとrangerによるランダムフォレスト)
- 世界一やさしいデータ分析教室 / 2017-10-30: 【Rでランダムフォレスト 】スピワゴ小沢さんと井戸田さんのTweetを分類!
- 同志社大学 / 文化情報学部 / データサイエンス研究室 / [連載] フリーソフトによるデータ解析・マイニング 第19回 ツリーモデル(木)
関連
- GNU R
- 奥村 晴彦 / 2019-01-14: タイタニック号沈没事故,(Cochran-)Mantel-Haenszel検定,Simpsonのパラドックス