O/R Mapper。これがメジャーらしい。http://www.sqlalchemy.org
ほかにElixirというのもあった
環境設定
DB
table定義
field
import
接続
使い方1
select
field指定
where
label
order by
left join
bind param
subquery
limit offset
and
not
or
between
like
exists
group by
もうひとつ踏み込んで
group byの集計結果からさらに絞って表示する場合のhavingを使う場合は
text
func
current_timestamp
count
insert
一行登録
複数行登録
delete
update
bindparam
sqlalchemy O/R版
DB/テーブル定義
mapping
mapper
declarative_base
基本的な使い方
select
select * from table
filter
order by
limit offset
bindparam
alias
subquery
from_statement
left join
selectの取得方法
all
one
get
行数取得
insert
一行
複数行
update
delete
一行
複数行
relation
前提条件
1:N
1:1
N:N
mapperの場合の設定例
最後の手段
ほかにElixirというのもあった
環境設定 
DB
psycopg2と同じ。ちなみにmysqlで使う場合は自分の環境では以下でセットアップした
sudo yum -y install mysql mysql-devel # python virtualenv activate. yumでインストールでもいい pip install MySQL-python
table定義
こんな感じでテーブルごとのしておくみたい
from sqlalchemy import Table, Column, Integer, Sequence, String, MetaData, ForeignKey
metadata = MetaData()
section = Table("section", metadata,
Column("section_id", Integer, Sequence("section_section_id_seq"), primary_key=True),
Column("section_name", String(128), nullable=False),
)
member = Table("member", metadata,
Column("member_id", Integer, Sequence("member_member_id_seq"), primary_key=True),
Column("first_name", String(128), nullable=False),
Column("last_name", String(128), nullable=False),
Column("age", Integer, nullable=False),
Column("section_id", Integer, ForeignKey("section.section_id"), nullable=False),
)
field
import
とりあえずこんだけimportしとけばほとんど使用できると思う
from sqlalchemy import create_engine, Integer, String from sqlalchemy.sql import select, text, bindparam, exists, func, and_, or_, not_ from metatables import member, section
接続
sqlalchemy.create_engine. デバッグするのならechoをTrueにしとくとよい
# dbtype://user:pass@server:port/dbname
#engine = create_engine("postgresql://postgres:@localhost:5432/testdb", echo=True)
conn = create_engine("postgresql://postgres:@localhost:5432/testdb")
# こんなんでもよい
conn.echo = True
使い方1
perlでいうSQL::Abstract的な記述方法
select
基本の参照系
# select * from member
s = select([member])
for row in conn.execute(s):
print(row)
field指定
# select member_id, age from member s = select([member.c.member_id, member.c.age])
where
どっちでもいい
# select member_id, age from member where member_id = 4 #s = select([member.c.member_id, member.c.age], member.c.member_id == 4) s = select([member.c.member_id, member.c.age]).where(member.c.member_id == 4)
label
別名でフィールドを定義したいとき
# select member_id, (first_name || last_name) as name, age from member where member_id = 4
s = select([member.c.member_id, (member.c.first_name + " " + member.c.last_name).label("name"), member.c.age], member.c.member_id == 4)
order by
普通のorder by
# select member.member_id, (member.first_name || member.last_name) as name, section.section_name from member, section where member.section_id = section.section_id order by member_id
s = select([member.c.member_id, (member.c.first_name + " " + member.c.last_name).label("name"), section.c.section_name], member.c.section_id == section.c.section_id).order_by(member.c.member_id)
order by fieldname desc
# select member.member_id, (member.first_name || member.last_name) as name, section.section_name from member, section where member.section_id = section.section_id order by member_id desc
s = select([member.c.member_id, (member.c.first_name + " " + member.c.last_name).label("name"), section.c.section_name], member.c.section_id == section.c.section_id).order_by(member.c.member_id.desc())
left join
# SELECT member.member_id, member.first_name || ' ' || member.last_name AS name, section.section_name FROM member LEFT OUTER JOIN section ON section.section_id = member.section_id
s = select([member.c.member_id, (member.c.first_name + " " + member.c.last_name).label("name"), section.c.section_name], from_obj=[member.outerjoin(section)])
s = select([member.c.member_id, (member.c.first_name + " " + member.c.last_name).label("name"), section.c.section_name]).select_from(member.outerjoin(section)).apply_labels()
bind param
s = select([member.c.member_id, (member.c.first_name + " " + member.c.last_name).label("name"), member.c.age], member.c.member_id == bindparam("member_id", type_=Integer))
for row in conn.execute(s, {"member_id": 3}):
print(row)
subquery
# select * from member where member_id = (select max(member_id) from member) s = select([member], member.c.member_id == select([func.max(member.c.member_id)]))
limit offset
# select * from member order by member_id limit 5 offset 0 s = select([member]).limit(5).offset(0).order_by(member.c.member_id)
and
# select * from member where section_id = 1 and member_id > 3 s = select([member], and_(member.c.section_id == 1, member.c.member_id > 3))
not
# select * from member where section_id != 1 s = select([member], not_(member.c.section_id == 1))こっちのがわかりやすいかも
s = select([member], member.c.section_id != 1)
or
# select * from member where section_id = 1 or section_id = 2 or section_id = 3 s = select([member], or_(member.c.section_id == 1, member.c.section_id == 2, member.c.section_id == 3))INってないかな。あるかもしれないけど
between
アクセサリ的なSQLだなんて昔は言われてたから使わないようにしてたけど、今はどうなんだろ
# select * from member where section_id between 1 and 3 s = select([member], member.c.section_id.between(1, 3))
like
# select * from member where firstname like 'foo%'
s = select([member], member.c.first_name.like('foo%'))
exists
# select * from member where exists (select section_id from section where section_name = 'operation') s = select([member], exists([section.c.section_id], section.c.section_name == "operation"))
group by
# SELECT member.section_id, count(member.section_id) AS syukei
# FROM member GROUP BY member.section_id ORDER BY count(member.section_id) DESC
#s = select([member.c.section_id, func.count(member.c.section_id).label("syukei")]).group_by(member.c.section_id).order_by(func.count(member.c.section_id).label("syukei").desc())
s = select([member.c.section_id, func.count(member.c.section_id).label("syukei")], group_by=[member.c.section_id], order_by=[func.count(member.c.section_id).label("syukei").desc()])
もうひとつ踏み込んで
section_id | section_name | syukei
------------+--------------+--------
4 | management | 13
2 | operation | 6
1 | developer | 2
3 | marketing | 1
こういう結果を得たい場合は
# SELECT member.section_id, section.section_name, count(member.section_id) AS syukei
# FROM member LEFT OUTER JOIN section ON section.section_id = member.section_id GROUP BY member.section_id, section.section_name ORDER BY count(member.section_id) DESC
s = select(
[member.c.section_id, section.c.section_name, func.count(member.c.section_id).label("syukei")],
from_obj=[member.outerjoin(section)],
group_by=[member.c.section_id, section.c.section_name],
order_by=[func.count(member.c.section_id).label("syukei").desc()]
)
group byの集計結果からさらに絞って表示する場合のhavingを使う場合は
# SELECT member.section_id, section.section_name, count(member.section_id) AS syukei
# FROM member LEFT OUTER JOIN section ON section.section_id = member.section_id GROUP BY member.section_id, section.section_name
# HAVING count(member.section_id) > 5 ORDER BY count(member.section_id) DESC
s = select(
[member.c.section_id, section.c.section_name, func.count(member.c.section_id).label("syukei")],
from_obj=[member.outerjoin(section)],
group_by=[member.c.section_id, section.c.section_name],
order_by=[func.count(member.c.section_id).label("syukei").desc()]
).having(func.count(member.c.section_id) > 5)
とするtext
最後の手段。直接SQL書きたい場合
s = text("select * from member")
func
関数使う。だいたいそのまま
current_timestamp
現在日付時間
# select current_timestamp as datetime
s = select([func.current_timestamp().label("datetime")])
d = conn.execute(s).fetchone()["datetime"]
# datetime objectで返ってくるのでこういうことが可能
print(d.strftime("%Y-%m-%d %H:%M:%S"))
count
#SELECT count(member.member_id) AS count FROM member
s = select([func.count(member.c.member_id).label("count")])
print(conn.execute(s).fetchone()["count"])
insert
登録。基本はbegin/commit/rollback。登録後の新しいprimary keyの値はresult.inserted_primary_keyで取得
一行登録
conn = engine.connect()
trans = conn.begin()
try:
ins = member.insert({ 'first_name': 'やまだ', 'last_name': 'たろう', 'age': 31, 'section_id': 1})
result = conn.execute(ins)
print(result.inserted_primary_key)
trans.commit()
except Exception, e:
trans.rollback()
print(e)
複数行登録
engine = create_engine("postgresql://postgres:@localhost:5432/testdb", echo=True)
conn = engine.connect()
trans = conn.begin()
try:
# ins = member.insert({ 'first_name': 'ほりもと', 'last_name': 'あきら', 'age': 31, 'section_id': 1})
# result = conn.execute(ins)
ins = member.insert()
result = conn.execute(
member.insert(), [
{ 'first_name': 'hoge', 'last_name': 'ahe', 'age': 7, 'section_id': 1 },
{ 'first_name': 'hoge2', 'last_name': 'ahe2', 'age': 8, 'section_id': 2 },
{ 'first_name': 'hoge3', 'last_name': 'ahe3', 'age': 9, 'section_id': 3 }
]
)
trans.commit()
except Exception, e:
trans.rollback()
print(e)
delete
whereを指定しなければ全削除。rowcountで削除された行数を取得できる
conn = engine.connect()
trans = conn.begin()
try:
result = conn.execute(member.delete().where(member.c.section_id == 4))
print(result.rowcount)
trans.commit()
except Exception, e:
trans.rollback()
print(e)
update
deleteとあんまり変わらない
engine = create_engine("postgresql://postgres:@localhost:5432/testdb", echo=True)
conn = engine.connect()
trans = conn.begin()
try:
result = conn.execute(member.update().values(age = 99).where(member.c.section_id == 3))
print(result.rowcount)
trans.commit()
except Exception, e:
trans.rollback()
print(e)
bindparam
実は勝手にbindparamになっているようだが、updateの例を明示的にbindparamを使うと以下のようになる
engine = create_engine("postgresql://postgres:@localhost:5432/testdb", echo=True)
conn = engine.connect()
trans = conn.begin()
try:
u = member.update().values(age = bindparam("age")).where(member.c.section_id == bindparam("b_section_id"))
result = conn.execute(u, age=100, b_section_id=3)
print(result.rowcount)
trans.commit()
except Exception, e:
trans.rollback()
print(e)
sqlalchemy O/R版
perlでいうDBIx-Classみたいな使い方。もう忘れたけど。ちなみに
に詳しく載っている
DB/テーブル定義
psycopg2, sqlalchemyその1と同じ
mapping
model.py
mapper
mapperを使う方法
# vim: fileencoding=utf-8
from sqlalchemy import Table, Column, Integer, Sequence, String, MetaData, ForeignKey, create_engine
from sqlalchemy.orm import mapper, sessionmaker
class Section(object):
def __init__(self, section_id, section_name):
self.section_id = section_id
self.section_name = section_name
def __repr__(self):
return "<Section('%s')>" % (self.section_name)
class Member(object):
def __init__(self, first_name, last_name, age, section_id):
self.first_name = first_name
self.last_name = last_name
self.age = age
self.section_id = section_id
def __repr__(self):
return "<Member('%s', '%s', '%s', '%s')>" % (self.first_name, self.last_name, self.age, self.section_id)
metadata = MetaData()
section = Table("section", metadata,
Column("section_id", Integer, Sequence("section_section_id_seq"), primary_key=True),
Column("section_name", String(128), nullable=False),
)
member = Table("member", metadata,
Column("member_id", Integer, Sequence("member_member_id_seq"), primary_key=True),
Column("first_name", String(128), nullable=False),
Column("last_name", String(128), nullable=False),
Column("age", Integer, nullable=False),
Column("section_id", Integer, ForeignKey("section.section_id"), nullable=False),
)
mapper(Section, section)
mapper(Member, member)
Session = sessionmaker(bind=create_engine("postgresql://postgres:@localhost:5432/testdb", echo=True), autocommit=True)
declarative_base
この方法もあり。mapperしたことと同じになる。どちらかを理解しておけばいい
# vim: fileencoding=utf-8
from sqlalchemy import Table, Column, Integer, String, Text, ForeignKey, create_engine
from sqlalchemy.orm import sessionmaker, relation, backref
from sqlalchemy.sql import func
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy.dialects import mysql
Base = declarative_base()
class Accounts(Base):
__tablename__ = "accounts"
__table_args__ = {"mysql_charset": "utf8"}
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(64))
password = Column(String(64))
salt = Column(String(8))
created =Column(mysql.TIMESTAMP, default=func.current_timestamp())
updated = Column(mysql.TIMESTAMP, default=func.current_timestamp())
# posts:accounts 1:n
# この設定でaccounts, posts双方向にリレーションが設定されたことになる
# classではなく、文字列でも指定可能(まだ定義されていないことがあるため)
#posts = relation("Posts", order_by="Posts.id", backref="account", cascade="all, delete, delete-orphan")
def __init__(self, id, name, password, salt, created, updated):
self.id = id
self.name = name
self.password = password
self.salt = salt
self.created = created
self.updated = updated
def __repr__(self):
return "<Accounts>('%s', '%s', '%s', '%s', '%s', '%s')" % (self.id, self.name, self.password, self.salt, self.created, self.updated)
基本的な使い方
実行する側の基本的な形は以下
#!/usr/bin/python
# vim: fileencoding=utf-8 expandtab
import sys
import os
from sqlalchemy import and_, or_
from model import Session, Section, Member
session = Session()
try:
session.begin()
# anything to do...
session.commit()
except Exception, e:
session.rollback()
print e
session.close()
select
queryで行う
select * from table
全部
s = session.query(Section.section_id, Section.section_name).all()1件
s = session.query(Section).first()
filter
where
s = session.query(Section.section_id, Section.section_name).filter(Section.section_id >= 3)filterを連結するごとにandになる
s = session.query(Section.section_id, Section.section_name).filter(Section.section_id >= 1).filter(Section.section_id <= 4) # and_でもいい。事前にimport必要 s = session.query(Section.section_id, Section.section_name).filter(and_(Section.section_id >= 1, filter(Section.section_id <= 4))or
s = session.query(Section.section_id, Section.section_name).filter(or_(Section.section_id == 1, Section.section_id == 4))in
s = session.query(Section.section_id, Section.section_name).filter(Section.section_id.in_([1, 3]))
order by
s = session.query(Section.section_id, Section.section_name).order_by(Section.section_id)降順の場合はdesc
s = session.query(Section.section_id, Section.section_name).order_by(Section.section_id.desc())
limit offset
配列スライスで
# offset 0から1レコード s = session.query(Section.section_id, Section.section_name)[0:1]
bindparam
いまさらながらfilter構文はsqlっぽく書くことができる
s = session.query(Section.section_id, Section.section_name).filter("section_name = :section_name").params(section_name="operation")
alias
s = session.query(Section.section_id, Section.section_name.label("sname"))
subquery
例えば
select * from member where member_id = (select max(member_id) from member);というようなSQLを発行したい場合
stmt = session.query(func.max(Member.member_id).label("member_id")).subquery()
s = session.query(Member.member_id, (Member.first_name + Member.last_name).label("member_name"), Section.section_name).outerjoin(Section).filter(Member.member_id == stmt.c.member_id).order_by(Member.member_id)
subqueryメソッドでstatementオブジェクトをsubqueryとして発行するSQLを事前に生成しておくfrom_statement
最後の手段。SQL直書き
s = session.query("member_id", "member_name").from_statement("select member_id, (first_name || last_name) as member_name from member")
left join
outerjoin. これがないとね
s = session.query(Member.member_id, (Member.first_name + Member.last_name).label("member_name"), Section.section_name).outerjoin(Section).order_by(Member.member_id)
for row in s.all():
print("member_id: %s member_name: %s section_name: %s" % (row.member_id, row.member_name, row.section_name))
selectの取得方法
all
sqlで取得したレコードすべて
s = session.query(Member)
for row in s.all():
print("member_id:%s first_name:%s last_name:%s" % (row.member_id, row.first_name, row.last_name))
one
一行だけ。そもそも1行だけしか帰ってこないようなやつに使えばいいんだと思うがよくわからない。firstと同じか
s = session.query(Member).filter(Member.first_name == "kurt").filter(Member.last_name == "cobain") row = s.one()
get
primary keyで取得。primary keyの無いテーブルはどうなるかわからない。findByIdと考えるとよさそうだ
s = session.query(Section).get(1)
行数取得
co*unt
count = session.query(Section).count()
insert
一行
add
member = Member("kurt", "cobain", 27, 2)
session.add(member)
session.flush()
session.commit()
複数行
add_allを使う
session.add_all([
Member("そこの", "おっさん", 89, 3),
Member("king", "buzzo", 47, 4),
])
update
selectしたレコードに対して行う
row = session.query(Member).get(8) row.age = 28 session.flush()
delete
updateと同じ。取得して削除
row = session.query(Member).get(8) session.delete(row) session.flush()
一行
row = session.query(Member).get(8) session.delete(row)
複数行
s = session.query(Member).filter(Member.first_name.like("%match%"))
for row in s.all():
session.delete(row)
relation
前提条件
ここだけこうしてみた
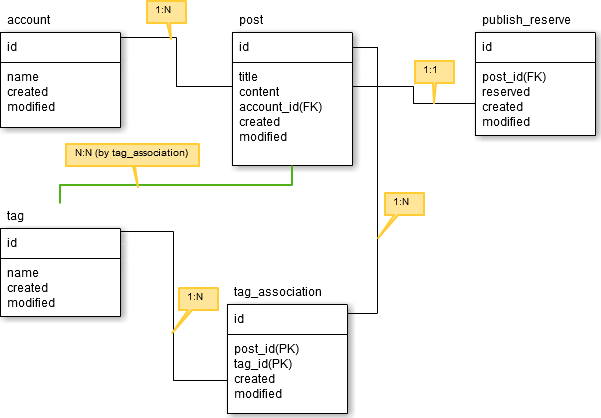
ちなみに全てのmodelは
ちなみに全てのmodelは
from sqlalchemy import Table, Column, Integer, String, Text, ForeignKey, create_engine from sqlalchemy.orm import sessionmaker, relation, backref from sqlalchemy.sql import func from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.dialects import mysql Base = declarative_base()が共通処理(作ったやつがこれだけmysql)
1:N
一番多いケース。account:post = 1:Nとなっている場合。だいたい見てのとおり。
account
post
account
class Account(Base):
__tablename__ = "account"
__table_args__ = {"mysql_charset": "utf8"}
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(64))
created =Column(mysql.TIMESTAMP, default=func.current_timestamp())
updated = Column(mysql.TIMESTAMP, default=func.current_timestamp())
# posts propertyで投稿した記事一覧を取得などができる。
posts = relation("Post", order_by="Post.id", backref="account", cascade="all, delete, delete-orphan")
def __init__(self, id, name, created, updated):
self.id = id
self.name = name
self.created = created
self.updated = updated
def __repr__(self):
return "<Account>('%s', '%s', '%s', '%s')" % (self.id, self.name, self.password, self.salt, self.created, self.updated)
post
class Posts(Base):
__tablename__ = "posts"
__table_args__ = {"mysql_charset": "utf8"}
id = Column(Integer, primary_key=True, autoincrement=True)
account_id = Column(Integer, ForeignKey("account.id"))
content = Column(String(255))
content = Column(Text)
created = Column(mysql.TIMESTAMP, default=func.current_timestamp())
updated = Column(mysql.TIMESTAMP, default=func.current_timestamp())
# account propertyで投稿者情報を取得できる。
account = relation(Account, backref=backref("post", order_by=id, cascade="all, delete, delete-orphan"))
def __init__(self, id, accounts_id, content, created, updated):
self.id = id
self.accounts_id = accounts_id
self.name = name
self.created = created
self.updated = updated
def __repr__(self):
return "<Posts>('%s', '%s', '%s', '%s', '%s')" % (self.id, self.accounts_id, self.content, self.created, self.updated)
ForeignKeyさえちゃんと指定した状態でrelationを設定すれば、それで紐付けはしてくれるっぽい。backrefは双方向に設定することを意味するので、関係するテーブルのどちらかにbackrefありでrelationを設定しているのであれば、どちらかはrelationの設定は不要1:1
post:publish_receive = 1:1。1:Nの場合とほとんど変わらない。uselistというdictがポイント
post
publish_receive
post
publish_reserve = relation(PublishReserve, backref="post", uselist=False, order_by=id, cascade="all, delete, delete-orphan")
publish_receive
class PublishReceive(Base):
__tablename__ = "publish_receive"
__table_args__ = {"mysql_charset": "utf8"}
id = Column(Integer, primary_key=True, autoincrement=True)
post_id = Column(Integer, ForeignKey("post.id"))
reserved =Column(mysql.TIMESTAMP)
created =Column(mysql.TIMESTAMP, default=func.current_timestamp())
updated =Column(mysql.TIMESTAMP, default=func.current_timestamp())
post = relation(Post, backref=backref("publish_reserve", uselist=False, order_by=id, cascade="all, delete, delete-orphan"))
def __init__(self, id, post_id, recerved, created, updated):
self.id = id
self.post_id = post_id
self.reserved = created
self.created = created
self.updated = updated
def __repr__(self):
return "<PublishReserve>('%s', '%s', '%s', '%s', '%s')" % (self.id, self.post_id, self.reserved, self.created, self.updated)
N:N
post:tagをtag_associateテーブルを介してN:Nの関係にしている
post
tag
post
tags = relation("Tag", secondary="tag_associate")
tag
class Tag(Base):
__tablename__ = "tag"
__table_args__ = {"mysql_charset": "utf8"}
id = Column(Integer, primary_key=True, autoincrement=True)
name = Column(String(255))
created =Column(mysql.TIMESTAMP, default=func.current_timestamp())
updated = Column(mysql.TIMESTAMP, default=func.current_timestamp())
posts = relation("Post", secondary="tag_associate")
def __init__(self, id, name, created, updated):
self.id = id
self.name = name
self.created = created
self.updated = updated
def __repr__(self):
return "<Tags>('%s', '%s', '%s', '%s')" % (self.id, self.name, self.created, self.updated)
この場合のbackrefの使い方がわからなかったため、両方のテーブルにsecondaryの設定を追加した(エラーになってしまったため)。primaryjoin/secondaryjoinというものがあるので、おそらくそれを使えばいけるのだろうけど、わからなかったのでそこまでは調査していない。mapperの場合の設定例
section:member は 1:nな関係なので
mapper(Section, section)
mapper(Member, member, properties={"section": relation(Section, backref="member")})
としてみる。あとは
s = session.query(Member)
for row in s.all():
print("member_id: %s section_name: %s" % (row.member_id, row.section.section_name))
joinしたかのように取得可能だが、その都度SQL発行しているようなので、自分でjoinなりをしたほうがいいような気がする。使い方がわかればそんなこと無いかもしれないけど最後の手段
SQL直書き。from_statementよりもっと直感的に。簡易的な使い方のほうとかわらない
session = Session()
try:
session.begin()
# 自分でjoinするsqlを書く
s = session.execute("""
select
p.id,
p.content,
p.created,
p.updated,
a.name
from
posts as p
left outer join
accounts as a on (p.accounts_id = a.id)""")
#print(s)
for row in s:
print("posts_id %s: author %s" % (row.id, row.name))
session.commit()
except Exception, e:
session.rollback()
print(e)
session.close()

タグ
最新コメント