INDEX: CUDA編01 << CUDA編02 >> CUDA編03
目次 
CUDAの概念
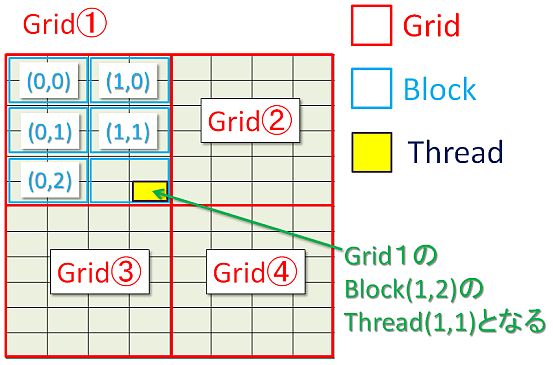
Grid、Block、Thread
CUDAには「Grid」、「Block」、「Thread」という単位がある。
「Thread」→いわゆる処理1つ分のこと。(例えばブラウザを起動しながらメールを起動するのは2つのスレッドとなるような感じ)
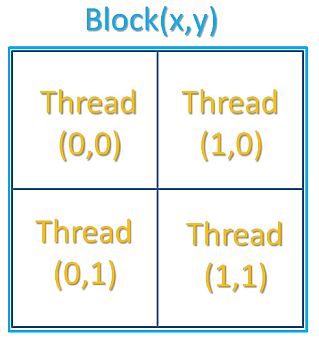
「Block」→複数個の「Thread」が集まったもの。
「Grid」→複数個の「Block」が集まったもの。
「Thread」→いわゆる処理1つ分のこと。(例えばブラウザを起動しながらメールを起動するのは2つのスレッドとなるような感じ)
「Block」→複数個の「Thread」が集まったもの。
「Grid」→複数個の「Block」が集まったもの。
 |  |
ローカルメモリ、共有メモリ、グローバルメモリ
「ローカルメモリ」は「Thread」が使うメモリ。
「共有メモリ」は「Block」内で使うメモリ。つまりそのブロック内の「Thread」で共有される。
「グローバルメモリ」はGPU全体で使用できるメモリ。
処理の概念
CUDAではデータ配列を各々のスレッドが担当し、それぞれが並列に実行されるイメージ。
つまり、上の図の1スレッドに配列データの1要素分を割り当てる感じ。
基本操作
CUDAの基本的な操作は次の通り。
- GPUのメモリ確保
- CPU→GPUへデータを転送
- GPUで処理(__global__関数へ)
- GPU→CPUでデータを取り出す
GPUのメモリ確保
GPUにデータを転送するためには、まずGPU上にメモリを確保する必要がある。
【例】:GPU上にメモリ確保
cudaError_t cudaMalloc (void **devPtr, size_t size)
GPU上にメモリを確保する。
※CUDA_SAFE_CALL()でエラーを拾う。(自分でチェックしてもよい)
不要になったら
cudaError_t cudaFree (void *devPtr)
でメモリを破棄する。
【例】:GPU上にメモリ確保
const int AryNum = 20000; … … //GPUのメモリ確保 int DataSize = sizeof(float)*AryNum; float *gpuAry; CUDA_SAFE_CALL(cudaMalloc( reinterpret_cast<void**>( &gpuAry), DataSize) ); … … cudaFree(gpuAry);//メモリ破棄【解説】
cudaError_t cudaMalloc (void **devPtr, size_t size)
GPU上にメモリを確保する。
※CUDA_SAFE_CALL()でエラーを拾う。(自分でチェックしてもよい)
不要になったら
cudaError_t cudaFree (void *devPtr)
でメモリを破棄する。
GPUへのデータの転送
GPUへのデータ転送はcudaMemcpy関数を使う
【例】:GPUへのデータ転送
//CPUでメモリ確保 float *ary = new float[AryNum]; … 値の設定 … //GPUのメモリ確保 int DataSize = sizeof(float)*AryNum; float *gpuAry; … GPUのメモリ確保 … CUDA_SAFE_CALL( cudaMemcpy( gpuAry, ary, DataSize , cudaMemcpyHostToDevice));【解説】
cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, enum cudaMemcpyKind kind)
「count」バイト分だけ「src」の内容を「dst」へコピー
「kind」には
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
GPUで処理(カーネルの呼び出し)
CPUでGPUが実行する関数をコールすることでGPUでの処理がはじまる。
※GPUでの関数の事をカーネルともよぶそうだ
【例】:カーネルの呼び出し
//------------- CUDAでの処理 ---------------//
__global__ void cuAddValue(float *gpuAryData)
{
const int threadId = blockIdx.x * blockDim.x + threadIdx.x; //スレッドIdを取得
gpuAryData[threadId] += 20000;//すべての要素を+20000する
__syncthreads(); //同期をとる
}
… …
//GPU用にブロックとスレッドを用意
dim3 grid(100,1,1);//100×1サイズのグリッド(1グリッドあたり100ブロック)
dim3 block(200,1,1);//200×1のブロックサイズ(1ブロックあたり200スレッド)
//グリッド100個、ブロック200
cuAddValue<<<grid,block>>>(gpuAry);
詳細については
GPU→CPUでデータを取り出す
「cudaMemcpy関数」の第4引数「にcudaMemcpyDeviceToHost」を指定すればよい。
【例】:GPUからデータを取り出す
【例】:GPUからデータを取り出す
//CPUでメモリ確保 float *ary = new float[AryNum]; … 値の設定 … //GPUのメモリ確保 int DataSize = sizeof(float)*AryNum; float *gpuAry; … GPUのメモリ確保 … … … //GPUから戻す(GPU -> Host) CUDA_SAFE_CALL( cudaMemcpy( ary,gpuAry ,DataSize, cudaMemcpyDeviceToHost) );
ここまでまとめ
ここまでをまとめると次のようになる
const int AryNum = 20000;
//------------- CUDAでの処理 ---------------//
__global__ void cuAddValue(float *gpuAryData)
{
… …
}
//------------- メイン関数 --------------------//
int main(int argc, char **argv)
{
CUT_DEVICE_INIT(argc,argv);
//CPUでメモリ確保+値設定
float *ary = new float[AryNum];
for(int loop = 0;loop < AryNum; ++loop)
{
ary[loop] = loop;
}
//GPUのメモリ確保
int DataSize = sizeof(float)*AryNum;
float *gpuAry;
CUDA_SAFE_CALL(cudaMalloc( reinterpret_cast<void**>( &gpuAry), DataSize) );
//GPUへデータをコピー(Host -> GPU)
CUDA_SAFE_CALL( cudaMemcpy( gpuAry, ary, DataSize , cudaMemcpyHostToDevice));
//GPU用にブロックとスレッドを用意
dim3 grid(100,1,1);//100×1サイズのグリッド(1グリッドあたり100ブロック)
dim3 block(200,1,1);//200×1のブロックサイズ(1ブロックあたり200スレッド)
cuAddValue<<<grid,block>>>(gpuAry);
//GPUから戻す(GPU -> Host)
CUDA_SAFE_CALL( cudaMemcpy( ary,gpuAry ,DataSize, cudaMemcpyDeviceToHost) );
cudaFree(gpuAry);//メモリ破棄
//出力テスト
for(int loop = 0;loop < AryNum; ++loop)
{
std::cout << ary[loop] << "\n";
}
delete [] ary;//メモリクリア
CUT_EXIT(argc, argv);//終了
return 0;
}
CUDA側の書き方
GPUへ渡した配列データを処理するにはなんとかして、アクセスするための添え字を取得する必要がある。
CUDAでは組み込み変数として、threadIdxやblockDimなどがある。
これらを使って、配列データにアクセスする。
詳細は
【例】
//------------- CUDAでの処理 ---------------//
__global__ void cuAddValue(float *gpuAryData)
{
const int threadId = blockIdx.x * blockDim.x + threadIdx.x; //スレッドIdを取得
gpuAryData[threadId] += 20000;//すべての要素を+20000する
__syncthreads(); //同期をとる
}
… …
cuAddValue<<<grid,block>>>(gpuAry);
【解説】まず、現在のスレッド番号、ブロック番号から配列データのどこに対応するかを計算。
処理すべき配列番号を取得したらそこにアクセスして、何らかの処理をおこなう。
void __syncthreads()
ブロック内のスレッドがすべてその関数がかかれた所にくるまで待つ。
ブロック内で同期処理をする時に使う。