OpenCL編02_2
最終更新:
![]() mikk_ni3_92 2010年05月22日(土) 23:15:16履歴
mikk_ni3_92 2010年05月22日(土) 23:15:16履歴
現在地 >> メニュー >> OpenCL >> OpenCL編02 >> OpenCL編02_2
INDEX:OpenCL編01 <<OpenCL編02、OpenCL編02_2、OpenCL編02_3 >> OpenCL編03?
次:OpenCL編02_3
目次
【5】:プログラムのセットアップ
次は、「.clファイル」を読み込んでプログラムの作成、ビルドを行う。
(i).ファイル読み込み
(ii).プログラムオブジェクトの作成
(iii).プログラムのビルド
【6】:カーネル作成
【7】:各種セットアップ
GPUに処理を行わせるには、
(i):GPU上にメモリ確保する
(ii):バッファオブジェクトにデータの読み書き、コピー
【8】:カーネルの実行
カーネル(GPU側の関数)の実行には、「clEnqueueNDRangeKernel関数」を使う。
CUDAとの対応について
というような感じになっている(たぶん)。
【参考:CUDAのメモリアクセス概念】
◆ここまでのまとめ
【9】:後片付け
サンプルコード
INDEX:OpenCL編01 <<OpenCL編02、OpenCL編02_2、OpenCL編02_3 >> OpenCL編03?
次:OpenCL編02_3
目次 
【5】:プログラムのセットアップ
次は、「.clファイル」を読み込んでプログラムの作成、ビルドを行う。
(i).ファイル読み込み
GLSLと同じような感じだが、まずはファイルを読み込む。
※ここではC++の「std::ifstream」と「std::string」を使っている。
【例】:gpuMain.clを読み込む
※ここではC++の「std::ifstream」と「std::string」を使っている。
【例】:gpuMain.clを読み込む
//GPUのソースコードを読み込む
std::ifstream myclSource("gpuMain.cl");
std::istreambuf_iterator<char> vdataBegin(myclSource);
std::istreambuf_iterator<char> vdataEnd;
std::string myclStr(vdataBegin,vdataEnd);
▲これでソースコードが「string型のmyclStr」に格納される。(ii).プログラムオブジェクトの作成
次に作成したコンテキストに対してのプログラムオブジェクトを作成する。
【例】:プログラムの作成
■clCreateProgramWithSource関数
【例】:プログラムの作成
cl_context cxGPUContext;//OpenCLコンテキスト用
//ソースコードの読み込み
… …
std::string myclStr(vdataBegin,vdataEnd);
const char *bfile = myclStr.c_str(); //const char * 型に変換
const size_t program_length = myclStr.size(); //サイズ取得
//プログラムを作成する
cl_program cpProgram
= clCreateProgramWithSource(cxGPUContext, 1, &bfile,
&program_length, &ciErrNum);
if (ciErrNum != CL_SUCCESS)
{
std::cerr << "Error: Failed to create program\n";
return -1;
}
■clCreateProgramWithSource関数
cl_program clCreateProgramWithSource(cl_context context, //コンテキスト cl_uint count, //今回は0(null終端の文字列の数) const char **strings,//ソースコードの内容 const size_t *lengths,//長さ cl_int *errcode_ret)//エラーコードを拾う時に使用する
(iii).プログラムのビルド
読み込んだプログラムのビルド(コンパイルとリンク)は「clBuildProgram関数」を使う。
【例】:プログラムのビルド
ログをとってくれる
■clBuildProgram関数
【例】:プログラムのビルド
ciErrNum = clBuildProgram(cpProgram, 0, NULL, NULL, NULL, NULL);
if (ciErrNum != CL_SUCCESS)
{
shrLogEx(LOGBOTH | ERRORMSG, ciErrNum, STDERROR);//ログの出力
shrEXIT(argc, argv);
}
▲なおこの時に「shrUtils」の「shrLogEx関数」をつかうとエラーを出力し、ログをとってくれる
■clBuildProgram関数
cl_int clBuildProgram ( cl_program program,//プログラムオブジェクト cl_uint num_devices,//とりあえず0でいい(次の引数がNULLの場合は0) const cl_device_id *device_list,//とりあえずNULLでいい(デバイスリストを指定) const char *options,//ビルドオプション void (*pfn_notify)(cl_program, void *user_data),//コールバック関数(不要ならNULL) void *user_data//コールバック関数に与えるデータ(不要ならNULL) )
【6】:カーネル作成
カーネルの作成する。つまりカーネルオブジェクトを作成し、
プログラムオブジェクトと関連付けをし、「.clファイル」内のmain関数に該当する
カーネル関数名を指定する。
【例】
■clCreateKernel関数
プログラムオブジェクトと関連付けをし、「.clファイル」内のmain関数に該当する
カーネル関数名を指定する。
【例】
/********** ○○.cppファイル *************/
cl_kernel myclKernel; //OpenCLのカーネル用
… …
//プログラムオブジェクトの作成
cl_program cpProgram = clCreateProgramWithSource(… …)
//カーネルの作成
myclKernel = clCreateKernel(cpProgram, "gpuMain", &ciErrNum);
if (ciErrNum != CL_SUCCESS)
{
return -1;
}
/********** ○○.clファイル ************/
__kernel void gpuMain(… …) //関数名が「gpuMain」
{
… …
}
■clCreateKernel関数
cl_kernel clCreateKernel(cl_program program,//プログラムオブジェクト const char *kernel_name,//カーネル名 cl_int *errcode_ret)//エラーを拾う場合に使用
【7】:各種セットアップ
GPUに処理を行わせるには、
- GPU上に作業用メモリを確保、コピーする
- カーネル(GPUの関数)に引数を与える
- …など
(i):GPU上にメモリ確保する
OpenCLでは
※ここでは「バッファオブジェクト」について書いていきます。
■バッファオブジェクト
OpenCLではバッファオブジェクトを経由して、GPUへデータを転送する。
そのため、まずはバッファオブジェクトを作成する。
使用する関数は「clCreateBuffer関数」である。
【第2引数:flagsについて】
確保するメモリオブジェクトの性質を設定する。
可能なのは以下の通り
※「CL_MEM_USE_HOST_PTR」と「CL_MEM_COPY_HOST_PTR」について
どちらも、第4引数:host_ptrを使ってメモリ内容が初期化する。
ここで、CL_MEM_USE_HOST_PTR使って次のように書いた場合を考える。
sampleData[99]=900;
の記述があってもGPU側のメモリ内容には反映されない。
- buffer objects(バッファオブジェクト)
- image objects(イメージオブジェクト) → 2次元や3次元データを使う時に使用
※ここでは「バッファオブジェクト」について書いていきます。
■バッファオブジェクト
OpenCLではバッファオブジェクトを経由して、GPUへデータを転送する。
そのため、まずはバッファオブジェクトを作成する。
使用する関数は「clCreateBuffer関数」である。
cl_mem clCreateBuffer(cl_context context,//OpenCLのコンテキストを指定 cl_mem_flags flags,//フラグ size_t size, //確保するメモリのバイトサイズ void *host_ptr,//CPU側のデータへのポインタ cl_int *errcode_ret)//エラーコードを拾う時に使用
【第2引数:flagsについて】
確保するメモリオブジェクトの性質を設定する。
可能なのは以下の通り
| フラグ | 内容 |
| CL_MEM_READ_WRITE | 読み書き可能。(デフォルト) |
| CL_MEM_WRITE_ONLY | カーネルによって書き込みは可能だが、読み込みができない |
| CL_MEM_READ_ONLY | 読み込み専用。 |
| CL_MEM_USE_HOST_PTR | 第4引数:host_ptrが必要。CPU側とGPU側でデータが同期する |
| CL_MEM_ALLOC_HOST_PTR | CPU側からアクセス可能な場所にメモリ確保 |
| CL_MEM_COPY_HOST_PTR | 第4引数:host_ptrが必要。メモリ確保+データコピーの操作 |
※「CL_MEM_USE_HOST_PTR」と「CL_MEM_COPY_HOST_PTR」について
どちらも、第4引数:host_ptrを使ってメモリ内容が初期化する。
ここで、CL_MEM_USE_HOST_PTR使って次のように書いた場合を考える。
int sampleData[100]; cl_mem dviceAry = clCreateBuffer(cxGPUContext, CL_MEM_READ_WRITE | CL_MEM_USE_HOST_PTR, sizeof(sampleData), &sampleData, NULL); sampleData[99]=900;//GPU側のメモリ内容にも反映される▲もし、「CL_MEM_USE_HOST_PTR」ではなく「CL_MEM_COPY_HOST_PTR」を使った場合は
sampleData[99]=900;
の記述があってもGPU側のメモリ内容には反映されない。
(ii):バッファオブジェクトにデータの読み書き、コピー
CPU側からは次の3つの関数をつかって、
バッファオブジェクトの読み、書き、コピーを行う。
【clEnqueueReadBuffer】
【第2引数:blocking_read】
この引数は、読み込み操作を「blocking(ブロッキング)」か「non-blocking(ノンブロッキング)」
のどちらで行うかを指定する。CL_TRUEでブロッキングとなる。
◆ブロッキング
clEnqueueReadBuffer関数はバッファデータが読み込まれ、メモリーにコピーされるまでリターンしない。
◆ノンブロッキング
clEnqueueReadBuffer関数は読み込みコマンドを実行し、すぐさまリターンする。
ただし、読み込みコマンドが完了するまではバッファの内容は使用できない。
※「clEnqueueWriteBuffer関数」の引数も同様。
「clEnqueueCopyBuffer関数」は、「blocking_read」がないだけで、ほぼ同じ。
リファレンス
バッファオブジェクトの読み、書き、コピーを行う。
| clEnqueueReadBuffer | GPU ⇒ CPU のデータ転送 |
| clEnqueueWriteBuffer | CPU ⇒ GPU のデータ転送 |
| clEnqueueCopyBuffer | バッファオブジェクト間のデータ転送 |
【clEnqueueReadBuffer】
cl_int clEnqueueReadBuffer(cl_command_queue command_queue,//コマンドキュー cl_mem buffer,//バッファオブジェクト cl_bool blocking_read,//ブロッキングモードを指定(CL_TRUE or CL_FALSE) size_t offset,//データの開始位置のオフセット size_t cb,//データのバイトサイズ void *ptr,//読み出し先。CPU側の格納用配列データのアドレス cl_uint num_events_in_wait_list,//イベントのリスト。とりあえず「0」でいい const cl_event *event_wait_list,//イベントリストの数。とりあえず「NULL」でいい cl_event *event)//とりあえずNULLでいい
【第2引数:blocking_read】
この引数は、読み込み操作を「blocking(ブロッキング)」か「non-blocking(ノンブロッキング)」
のどちらで行うかを指定する。CL_TRUEでブロッキングとなる。
◆ブロッキング
clEnqueueReadBuffer関数はバッファデータが読み込まれ、メモリーにコピーされるまでリターンしない。
◆ノンブロッキング
clEnqueueReadBuffer関数は読み込みコマンドを実行し、すぐさまリターンする。
ただし、読み込みコマンドが完了するまではバッファの内容は使用できない。
※「clEnqueueWriteBuffer関数」の引数も同様。
「clEnqueueCopyBuffer関数」は、「blocking_read」がないだけで、ほぼ同じ。
リファレンス
【8】:カーネルの実行
カーネル(GPU側の関数)の実行には、「clEnqueueNDRangeKernel関数」を使う。
cl_int clEnqueueNDRangeKernel (cl_command_queue command_queue,//コマンドキュー cl_kernel kernel,//カーネル cl_uint work_dim,//次元 const size_t *global_work_offset,//オフセット const size_t *global_work_size,//ワークサイズ const size_t *local_work_size,//ローカルワークサイズ cl_uint num_events_in_wait_list,//とりあえず0でいい const cl_event *event_wait_list,//とりあえずNULLでいい cl_event *event)//とりあえずNULLでいい
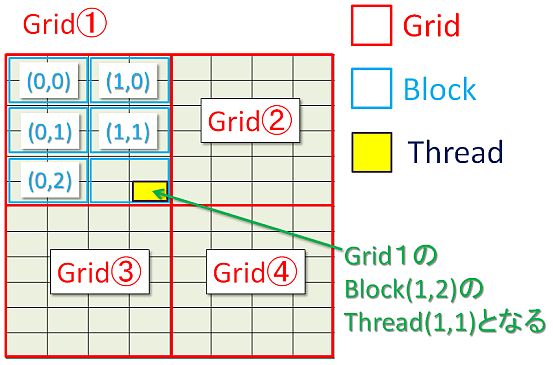
CUDAとの対応について
| OpenCL | CUDA |
| NDRange | grid |
| work-group | block |
| work-item | thread |
【参考:CUDAのメモリアクセス概念】
◆ここまでのまとめ
【7】、【8】の内容:
メモリオブジェクトの作成
データをコピー
カーネルの呼び出し
計算結果の取り出し
のプログラム例は以下の通り
メモリオブジェクトの作成
データをコピー
カーネルの呼び出し
計算結果の取り出し
のプログラム例は以下の通り
const int aryNUM = 100;
int sampleData[aryNUM];
… …
//デバイス上にメモリ確保
cl_mem dviceAry = clCreateBuffer(cxGPUContext, CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR,
sizeof(sampleData), &sampleData, NULL);
sampleData[99] = 900;//CL_MEM_COPY_HOST_PTRなのでGPU側には反映されない
//データをコピー
clEnqueueWriteBuffer(commandQueue,dviceAry,CL_TRUE,0,sizeof(sampleData),sampleData,0,NULL,NULL);
//カーネルに引数を設定する
clSetKernelArg(myclKernel,0,sizeof(cl_mem), (void *) &dviceAry);
//実行
//CUDAとOpenCLの用語の対応
//Thread == work-item
//block == workgroup
size_t WorkSize[1] = {aryNUM};//ワークサイズ
clEnqueueNDRangeKernel(commandQueue, myclKernel, 1, NULL, WorkSize, NULL,0, NULL, NULL);
//データを取り出し
clEnqueueReadBuffer(commandQueue, dviceAry, CL_TRUE, 0,sizeof(sampleData), &sampleData, 0, NULL, NULL);
【9】:後片付け
作成した
【例】:作成したオブジェクトの破棄
次:OpenCL編02_3
- コンテキスト
- カーネル
- プログラム
- コマンドキュー
- メモリオブジェクト
- …
- clReleaseContext関数
- clReleaseKernel関数
- clReleaseProgram関数
- clReleaseCommandQueue関数
- clReleaseMemObject関数
- …
【例】:作成したオブジェクトの破棄
cl_context cxGPUContext;//OpenCLコンテキスト用 cl_kernel myclKernel; //OpenCLのカーネル用 cl_command_queue commandQueue;//コマンドキュー … … //コンテキストの作成 cxGPUContext = clCreateContext(0, ciDeviceCount, cdDevices, NULL, NULL, &ciErrNum); … … //コマンドキューの作成 commandQueue = clCreateCommandQueue(cxGPUContext, (*cdDevices), 0, &ciErrNum); … … //プログラムを作成する cl_program cpProgram = clCreateProgramWithSource(cxGPUContext, 1, &bfile, &program_length, &ciErrNum); … … //カーネルの作成 myclKernel = clCreateKernel(cpProgram, "gpuMain", &ciErrNum); … … //デバイス上にメモリ確保 cl_mem dviceAry = clCreateBuffer(cxGPUContext, CL_MEM_READ_WRITE | CL_MEM_COPY_HOST_PTR, sizeof(sampleData), &sampleData, NULL); … … clReleaseContext(cxGPUContext);//コンテキスト clReleaseCommandQueue(commandQueue);//コマンドキュー clReleaseProgram(cpProgram);//プログラム clReleaseKernel(myclKernel);//カーネル clReleaseMemObject(dviceAry);//メモリオブジェクト
次:OpenCL編02_3
サンプルコード

