Hadoop本読書会 - 12章 HBase
最終更新:ID:iINjiAJ1kg 2011年01月30日(日) 04:52:16履歴
Hadoop本 12章 HBase の疑問点や気になる点について記述してください。
※記入者、該当ページ・該当行は忘れずに書いて下さい。
Hadoop本以外の参考資料
HBaseとは?
HBaseの特徴
正当な?HBaseの利用例
なぜHBase(分散DB)が必要なのか?
HBase以外の分散DBは何があるの?
HBaseのデータモデル
データモデルの論理的なイメージ
物理的なデータモデルとファイル構造
Region
HBaseのサーバ構成
HBaseの書き込みフロー
コンパクション
HBaseの簡易的な動作環境
HBaseクラスタの構築
HBaseクライアント
HBaseでのスキーマ設計のポイント
※記入者、該当ページ・該当行は忘れずに書いて下さい。
Hadoop本以外の参考資料 
- [記入者] terurou
- Hadoop本12章はざっくりしすぎな感じがするので、以下の資料も見たほうが良いかと思います。
- 1/30の読書会でもHadoop本は多少無視気味に話をしようかと思っています。
HBaseとは?
- [記入者] terurou
- [該当箇所] 371〜372ページ(12.1 HBaseの基礎)
- GoogleのBigtableのオープンソースクローン
- Hadoopのサブプロジェクト、HBaseだけで独立して配布されている
- 当然、MapReduceなどの他のHadoopのプロダクトとの親和性は高い
HBaseの特徴
- [記入者] terurou
- [該当箇所] 371ページ(12.1 HBaseの基礎)
- 列指向データベース(カラムファミリー指向データベース)
- OracleやMySQLなどのRDBMSは行指向データベース
- 分散データベース
- ノードを追加すると直線的にスケール(性能が向上)する
- ランダムアクセス、リアルタイムな読み書き
- Write性能をRead性能より優先している
- シーケンシャルRead、ランダムWriteに強い(MapReduceに必要な要素)
- 逆にランダムRead、シーケンシャルWriteは弱い
- トランザクションがサポートされている
- ただし行に限定
- SQLはサポートしていない
正当な?HBaseの利用例
- [記入者] terurou
- [該当箇所] 371ページ(12.1 HBaseの基礎)
- webtableが代表的な例
- 要はGoogleのようなWeb検索エンジンのためのストレージ
- URLをキー、Webページや言語・MIMEなどの属性を値として保存
- 数十億件!
なぜHBase(分散DB)が必要なのか?
- [記入者] terurou
- [該当箇所] 391〜395ページ(12.6 HBase対RDBMS)
- Apache HBase 入門 (第1回)の5〜10ページを参照
- RDBMS自体が元々スケールさせるような設計になっていない
- レプリケーション構成ではReadの負荷分散ができてもWriteの負荷分散がしづらい
- レプリケーション構成を組んだりMemcachedを導入していった時点で、RDBMSの機能を捨てることになる
- JOINとか、外部キー制約とか、データの一貫性・トランザクションとか
HBase以外の分散DBは何があるの?
- [記入者] terurou
- [該当箇所] 391〜395ページ(12.6 HBase対RDBMS)
- 以下のものが有名かと思います。
- Cassandra
- HBaseと同じ列指向DB。なのでHBaseと比較されることが多い。
- HBaseよりも要求されるハードウェアスペックが低い。
- いちおうHadoop MapReduce連携が用意されているが、HBaseを使う場合と比較して効率が良くない。
- DiggやTwitter(の一部)などで採用されている。国内ではPARTAKEが採用している。
- MongoDB
- ドキュメント指向DB、JSONライクなフォーマット。
- JavaScriptでMapReduce。
- アーキテクチャの制約上、ストレージを浪費しがち。
- foursquareなどで採用されている。
- CouchDB
- APサーバ+ドキュメント指向DBサーバ。「モダンでスケールアウトもするMS Accessみたいなもの」だと思うといいかも。
- データはJSON。MapReduceやアプリケーションはJavaScriptで書く。
- クライアントサイドにCouchDBをインストールし、マスタサーバから必要なデータだけをクライアントと同期させる…、といった使い方ができる。
- 処理性能・ストレージ容量の効率はそれほど高くない。
- 採用事例は知らない。
- Cassandra
HBaseのデータモデル
- [記入者] terurou
- [該当箇所] 372ページ(12.2.1 データモデルに関する弾丸ツアー)
- はっきり言って、この節は読んでも理解出来ないんじゃないかと思う。。。
データモデルの論理的なイメージ
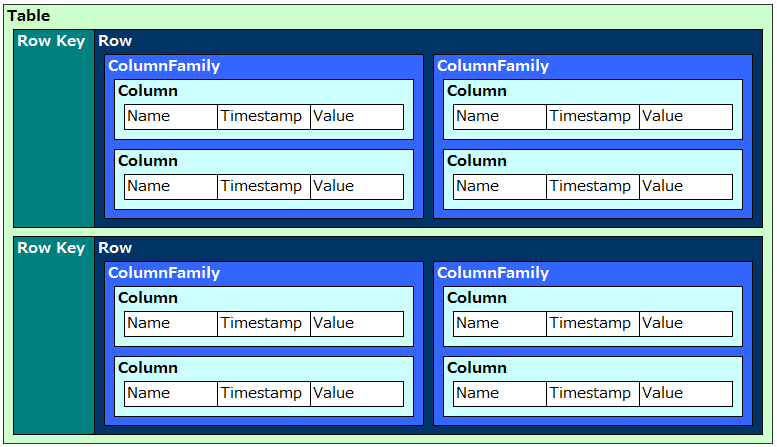
物理的なデータモデルとファイル構造
HBaseの構造 - LunaBiblosの"3 概念図と実ファイル図"を参照
- Column Key = ColumnFamily:Column名
- Column名は省略することが可能
- データはTimestampによってバージョニングされる
- データはColumnFamilyごとにまとめられ、Row Key昇順・Timestamp降順にソートされた状態で実ファイルに保存される
- 同じRowのデータでも別のファイルに分割される(これが行指向データベースと異なる点)
Region
- HBaseには実ファイル(Region)が巨大になりすぎないよう自動的に水平分散する仕組みがある
- Regionのサイズが一定値を超えると、自動的に2つのRegionに分割する
- 分割する際、Region1にはRow Keyが○〜△・Region2にはRow Keyが△〜☓のデータを保存するという感じの振り分けルールを追加される
HBaseのサーバ構成
- [記入者] terurou
- [該当箇所] 373〜376ページ(12.2.2 実装)
- 4.3 RegionファイルとJava Classより下を参照
- HBaseMaster
- マスタノード
- HBaseクラスタの管理
- Regionの割り当て
- HRegionServer
- スレーブノード
- Regionファイルの読み書き
- MemtStore(メモリキャッシュ)
- ZooKeeper
- マスタノードリストの管理
- ZooKeeperについては13章で解説あり
- HDFS
- HRegionServerのデータのレプリカを保存
- HDFSに単一障害点が存在することに注意
HBaseの書き込みフロー
- [記入者] terurou
- [該当箇所] 373〜376ページ(12.2.2 実装)
- HRegionServerへ書き込み要求が発生
- HRegionServer:HDFSへコミットログを書き込み
- HRegionServer:Memstoreへ書き込み
- MemStoreの容量が一定サイズを超えた際にファイルへフラッシュする
- フラッシュする度に新しいファイルを作成
コンパクション
- ファイルフラッシュの度にファイルが増えてしまうことを解決する
- マイナーコンパクション
- 最近フラッシュされたデータファイルをひとつに纏められる
- メジャーコンパクション
- すべてのデータファイルをひとつに纏める
HBaseの簡易的な動作環境
- [記入者] terurou
- [該当箇所] 376〜379ページ(12.3 インストール)
- 開発環境などで利用する場合が該当
- 特に複雑な設定は不要。バイナリをダウンロードしてきて、少し設定するだけで動作する
HBaseクラスタの構築
- [記入者] terurou
- [該当箇所] 395〜398ページ(12.7 実践)
- ハードウェア構成
- 安定稼働させるには、HBaseMasterサーバ2台・HRegionServer5台・ZooKeeper3台の計10台は必要。HDFSが含まれていないことに注意。
- 最小構成でも3台以上が推奨されている
- チューニングポイント
- ファイルディスクリプタの枯渇
- データノードのスレッド枯渇
- 不良ブロックの扱い
- クラスタ監視
- Web UIが60010ポートで稼働
- メトリクス(10.2.2)にログ出力可能
HBaseクライアント
- [記入者] terurou
- [該当箇所] 379〜383ページ(12.4 クライアント)
- HBaseにはJava API, MapReduce, Thrift API, REST APIでアクセス可能
- Thrift API, REST APIは通常のJava APIと比べ、プロキシ処理のオーバーヘッドの分だけ遅い
HBaseでのスキーマ設計のポイント
- [記入者] terurou
- [該当箇所] 398〜399ページ(12.7.5 スキーマの設計)
- Hadoop本には大したことが書かれていない。。。が、Hadoop徹底入門の11.1.7にポイントとなる点が2つ挙げられている
- Row Key
- HBaseはKeyによってRegionが確定する
- そのため、Row Keyの設計を誤ると、1台のサーバに処理が集中してしまう
- Keyにtimestampを付与するなどして、単一Key・単一Regionにアクセスが集中しないようにする
- Column Family
- 扱い方・アクセス方法の異なる値を1つのColumnFamilyに入れることを避ける
- HBaseはColumnFamilyごとにファイルを作成するため、1つのColumnFamilyにデータを固めてしまうと、ファイルが肥大化しキャッシュも効きづらくなってしまうため、パフォーマンスが劣化する

このページへのコメント
odE6Vq Appreciate you sharing, great post.Really looking forward to read more. Cool.
3Ch3ou <a href="http://okfdqioeyxgz.com/">okfdqioeyxgz</a>, [url=http://tjujfeyjqqln.com/]tjujfeyjqqln[/url], [link=http://nkijetqmqwnz.com/]nkijetqmqwnz[/link], http://dsuwohpyvweu.com/