Solr/Tokenizer評価201105/JapaneseTokenizer&EdgeN
最終更新:
 haruyama_seigo 2011年05月16日(月) 08:05:29履歴
haruyama_seigo 2011年05月16日(月) 08:05:29履歴
- lucene-gosen - Japanese analysis for Apache Lucene/Solr 3.1 and 4.0 - Google Project Hosting
- 2011/05/06 10:20 JSTごろのものを利用
- solr.EdgeNGramFilterFactory - AnalyzersTokenizersTokenFilters - Solr Wiki
- 第3回solr勉強会(アメーバにおけるsolrの利用) のように asciiはngramの対象としないほうが望ましい場合が多そうだが, 今回は solr付属のまま.
測定結果 
| 回数 | 時間(QTime, ms) | インデックスサイズ(byte) |
| 1 | 2844457 | 9334880728 |
| 2 | 2746278 | 9334880728 |
| 3 | 2831094 | 9334880728 |
設定
schema.xml
<fieldType name="text_ja" class="solr.TextField" positionIncrementGap="100">
<analyzer>
<tokenizer class="solr.JapaneseTokenizerFactory"/>
<filter class="solr.EdgeNGramFilterFactory" minGramSize="1" maxGramSize="15" side="front"/>
</analyzer>
</fieldType>
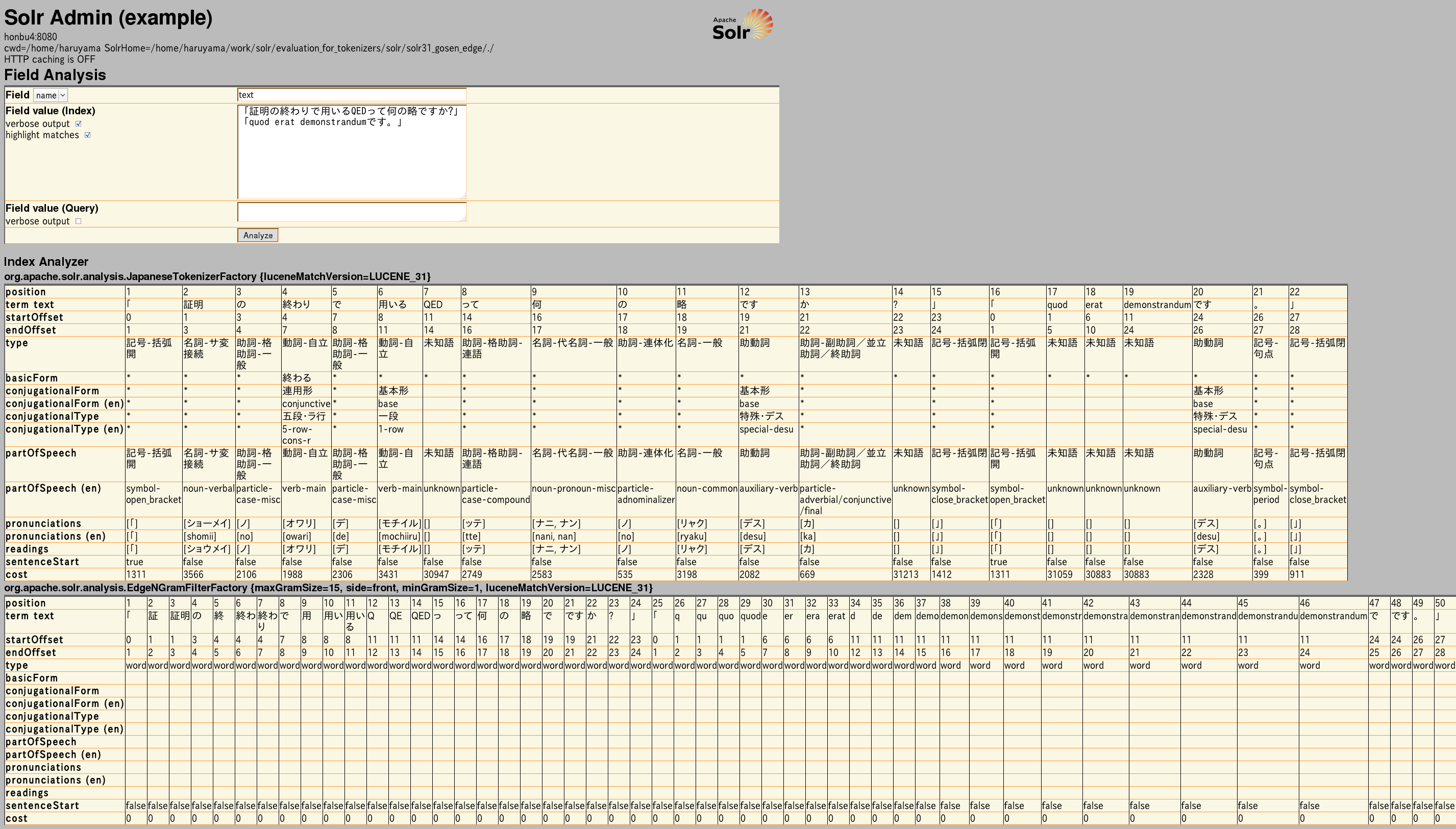
Tokenizeサンプル
「証明の終わりで用いるQEDって何の略ですか?」「quod erat demonstrandumです。」のTokenize
- カテゴリ:
- インターネット
- インターネットセキュリティ
最新コメント