ControlNet
最終更新:ID:6OXzkG2juw 2024年06月23日(日) 11:18:47履歴
ControlNetについて 
ポーズや構図等を指定して画像生成できるようにする拡張機能。
従来のプロンプトでの画像制御に加えて、輪郭線・奥行き・人のポーズなどの「画像情報」を追加で入力することで、より思い通りに画像を制御できる。
その制御方法(Model)は複数ある(詳しくはcannyやhedやsegなど、下記参照)。
従来のプロンプトでの画像制御に加えて、輪郭線・奥行き・人のポーズなどの「画像情報」を追加で入力することで、より思い通りに画像を制御できる。
その制御方法(Model)は複数ある(詳しくはcannyやhedやsegなど、下記参照)。
詳細
i2iとの違い
インストール
- Stable Diffusion Web UI の「拡張機能 (Extensions)」タブ > 「URLからインストール (Install from URL)」に、以下のURLを入れてインストールします。
https://github.com/Mikubill/sd-webui-controlnet - 以下からモデルファイル(.safetensorsファイルもしくは.pth)をダウンロードして「stable-diffusion-webui\extensions\sd-webui-controlnet\models」に置きます。
- 標準的な軽量モデル:https://huggingface.co/webui/ControlNet-modules-sa...
- kohya氏によるモデル改良版(何か応答がよくなるらしい?):https://huggingface.co/kohya-ss/ControlNet-diff-mo...
- 有志の人が作った顔の向きや目や口の状態がわかるControlNetMediaPipeFace: https://huggingface.co/CrucibleAI/ControlNetMediaP...
- 2023年4月中旬ごろに発表されたControlNet 1.1: https://huggingface.co/lllyasviel/ControlNet-v1-1/...
使い方
txt2img・img2imgタブの下にControlNetができてるので▼をクリック
詳しい例は上のやつ読んで
- Enableを押して
- Preprocessor を選んで
- Preprocessor と同じ名前のモデルを選ぶ
詳しい例は上のやつ読んで
Preprocessorの種類と特徴
| 名前 | 説明 | 元画像 | プリプロセッサ処理後画像 | 出力画像 |
| canny | 輪郭線を検出して取り出す |  |  |  |
| depth | 深度情報を引き継ぐ 立体的な位置関係を処理できる |  |  |  |
| hed | いわゆる「描き込み」的な部分を取り出す タッチを引き継ぎやすい | 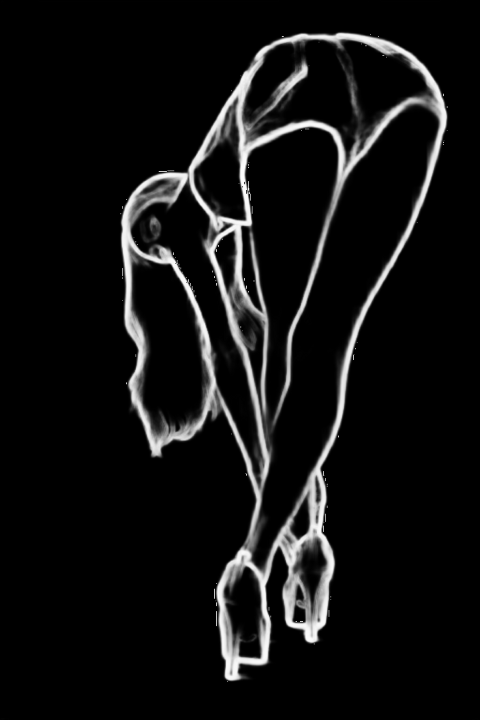 |  | |
| mlsd | 直線の輪郭だけ取り出す 曲線のない人工的な構図をノイズ無く取り出せる | |||
| normal_map | 法線情報を引き継ぐ 深度情報よりも細部の立体感に沿いやすい |  | ||
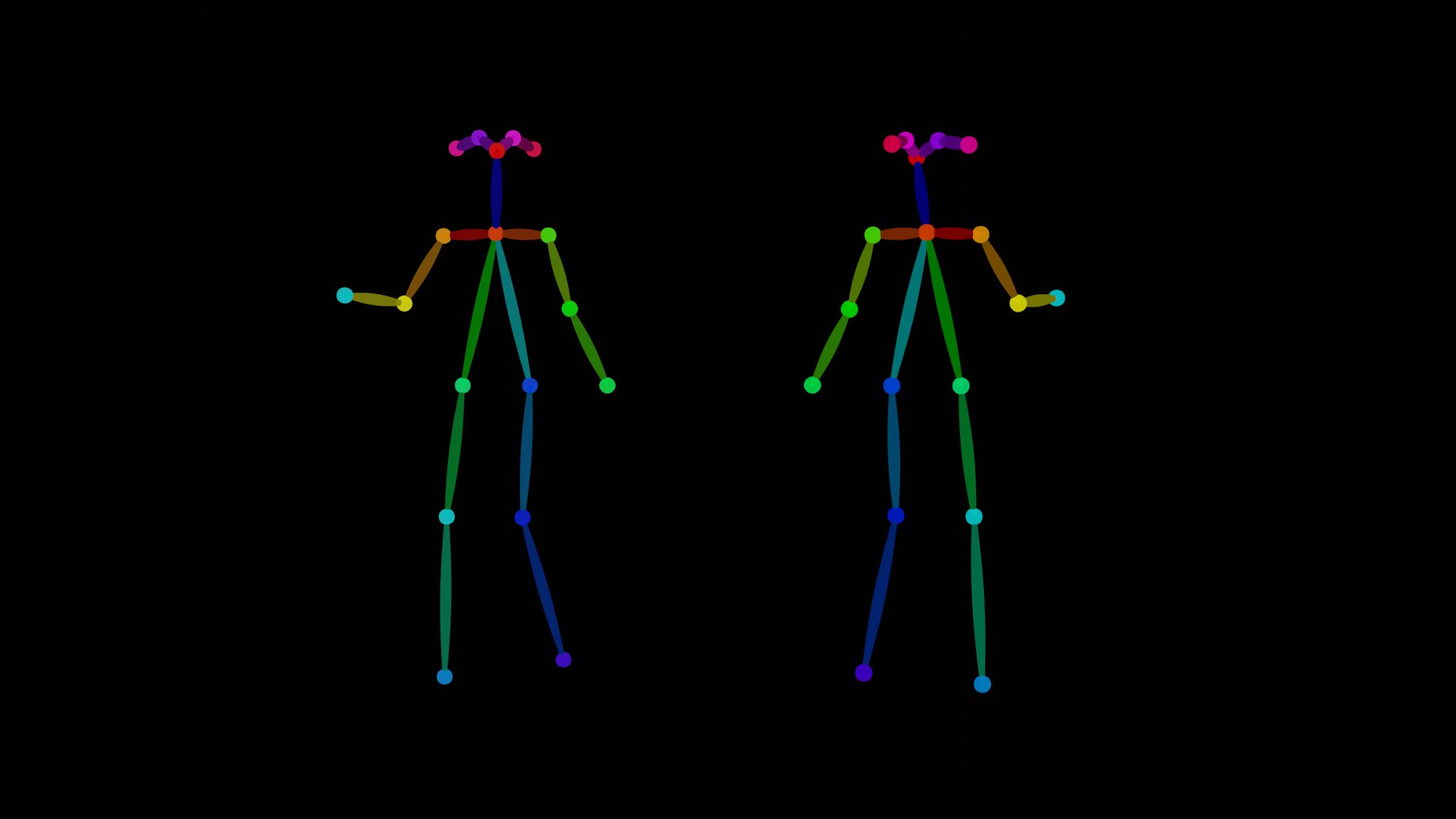
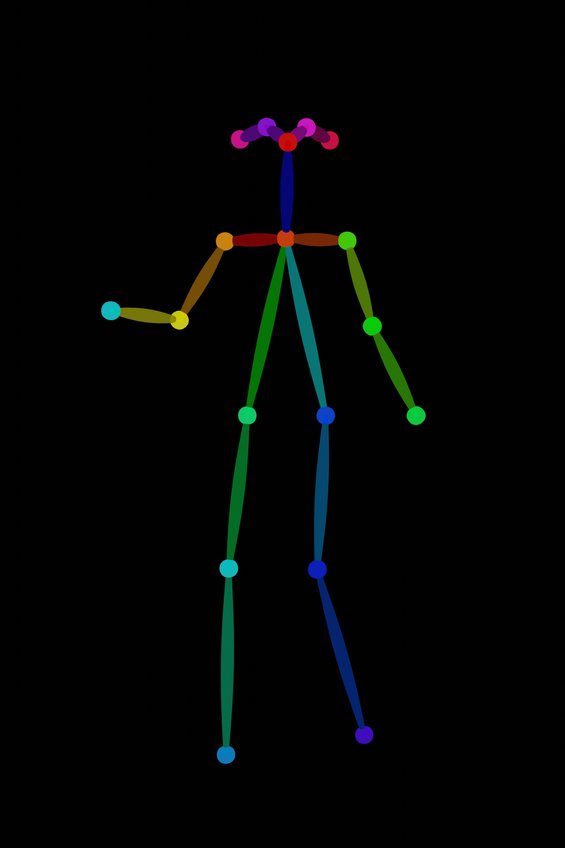
| openpose | おなじみの棒人間 |  |  |  |
| openpose_hand | 棒人間に手が追加されたやつ.現状あまり認識精度が良くない印象. |  | 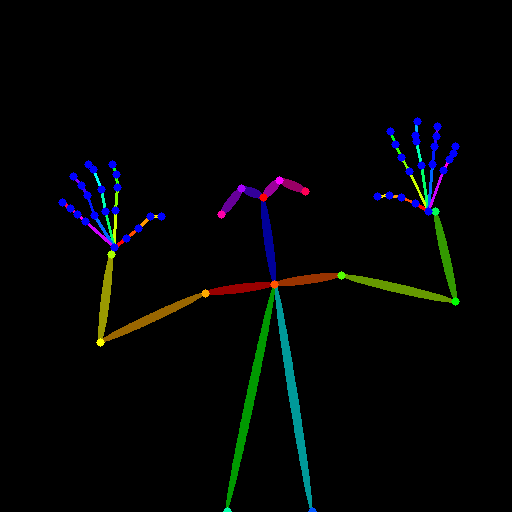 | |
| openpose_face | 棒人間に顔の特徴点(face landmarks)が追加されたもの(v1.1追加).棒人間では表現しきれなかった目や口の状態や顔の大きさなどが表現できるようになった |  | 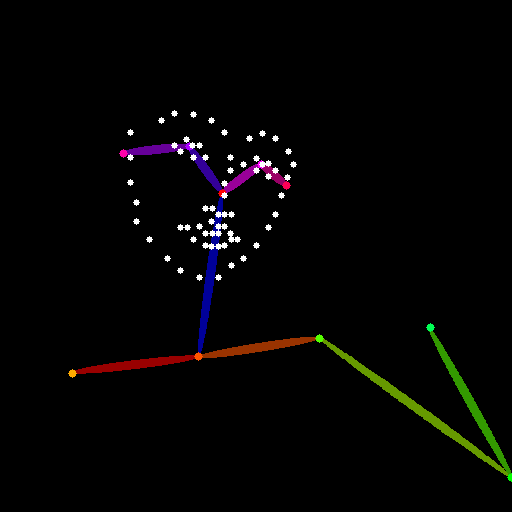 | |
| openpose_full | openpose+openpose_hand+openpose_faceの処理すべてを行う(v1.1追加). | |  | |
| mediapipe_face | ControlNetの発案者とは異なる人が作ったControlNetMediaPipeFaceというモデル用の前処理.目・口・顔の形や向きがわかる画像が生成される. |  |  |  |
| scribble | マウス入力の落書き 線を絶対的なものとしては扱わず、いい感じに仕上げる |  |  |  |
| fake_scribble | 画像を一回落書き風に変換してscribbleに投入する |  |  |  |
| segmentation | 'ADE20K'という規格で塗り絵 領域に分類を持たせる |  |  | |
| lineart_realistic | 写真を線画に変換するやつ(v1.1追加).cannyだとしきい値(threshold)をうまくやらないとボケている箇所の輪郭が抽出されないことがあったが,この処理ではその辺をいい感じの塩梅にして線を引いてくれる印象がある. | |  |  |
| lineart_coarse | 写真を線画に変換するものだが,lineart_realisticよりも粗い(雑な)線画になる(v1.1追加) | |  |  |
元画像から加工されたcannyやdepthなどの画像はデフォルトでは
stable-diffusion-webui\extensions\sd-webui-controlnet\detected_mapsに保存されているのでいいやつができたら取っておこう
得意不得意
ちょっと試した感じこんな感じでした
-
OpenPose: 奥行き苦手 - NomalMap: 奥行き得意 ただし背景が消失する(?)
- DepthMap: 奥行き得意 背景も死なない
Normal & Depth

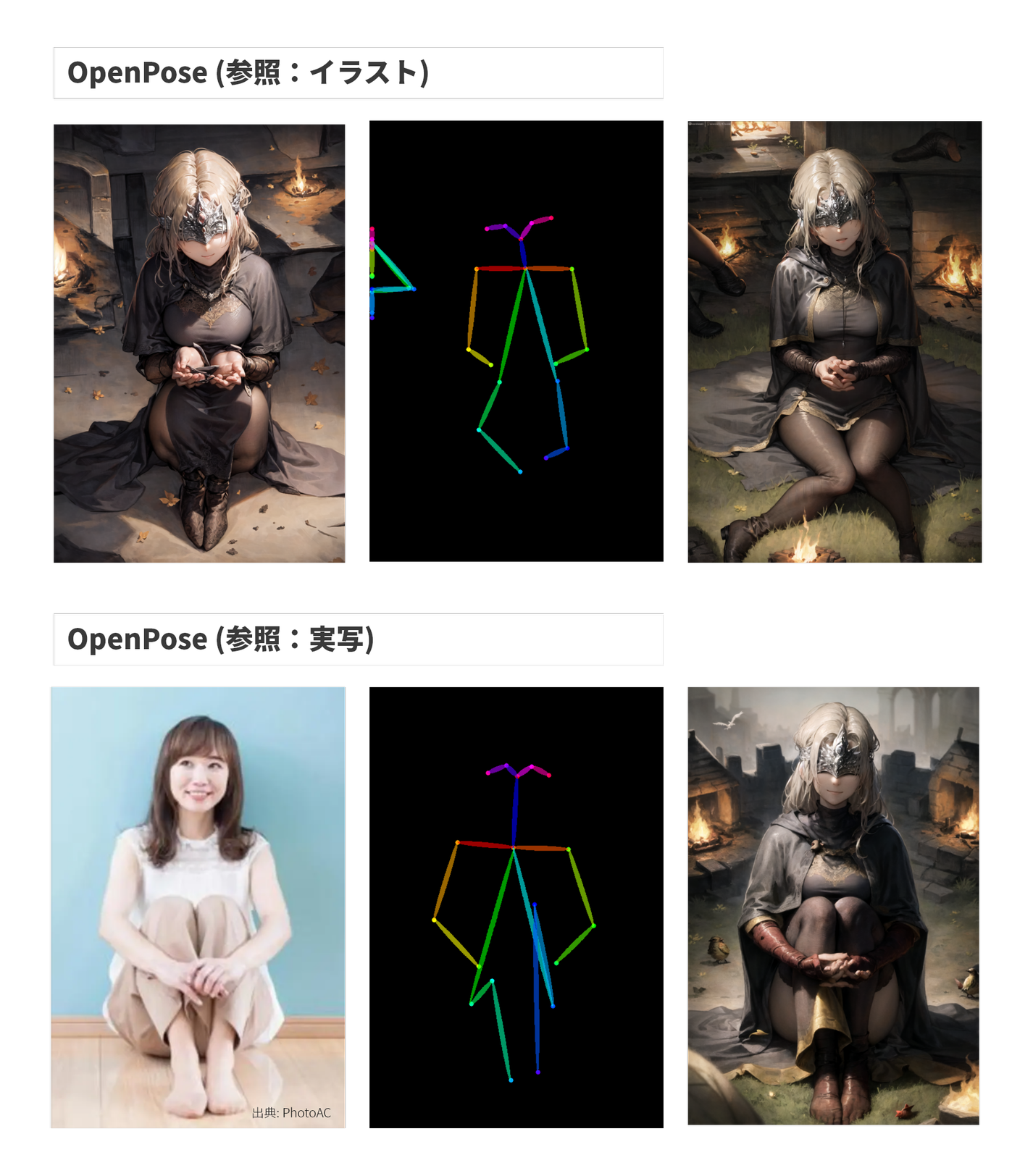
OpenPoseは実写/イラストで検出精度が変わるみたいです
segmentation
塗り絵から構図と描くもの(人や道や木など150種類の概念から選べる)をコントロール・・・できそうなやつや。
ADE20Kって規格で塗り絵するで
物と事で色分けが違うらしい。雑に言うと「人間」は数えられるので「物」、「空」は数えられないので「事」
色分けの決まりは下参照
こんなん人力では無理やという場合は元画像(実写が望ましい)を用意してWebで
https://huggingface.co/spaces/shi-labs/OneFormer
the task is semantic, ADE20K, DiNAT-L(最後はSwin-Lでも可、たぶん変換のモデルの違い?)
にチェック入れて送信すると右下に塗り分けられて出力される。
あとは適当なペイントツールで好きなように修正する。
ADE20Kって規格で塗り絵するで
物と事で色分けが違うらしい。雑に言うと「人間」は数えられるので「物」、「空」は数えられないので「事」
色分けの決まりは下参照
- https://github.com/CSAILVision/sceneparsing/tree/m...
- ADE20Kのオブジェクト-RGB対応表スプレッドシート https://docs.google.com/spreadsheets/d/1se8YEtb2de...
こんなん人力では無理やという場合は元画像(実写が望ましい)を用意してWebで
https://huggingface.co/spaces/shi-labs/OneFormer
the task is semantic, ADE20K, DiNAT-L(最後はSwin-Lでも可、たぶん変換のモデルの違い?)
にチェック入れて送信すると右下に塗り分けられて出力される。
あとは適当なペイントツールで好きなように修正する。
めんどくさい!ようわからん!
とりあえず参考にしたい画像をドロップして
Preprocessor:segmentation, model:~_segにして出力してみる
出てきた塗り絵を適当なペイントツールで修正する。
ちなみに元画像はアニメ塗りより実写がいいらしい(って4chanで見た)→openposeの話やったすまん
Preprocessor:segmentation, model:~_segにして出力してみる
出てきた塗り絵を適当なペイントツールで修正する。
ちなみに元画像はアニメ塗りより実写がいいらしい(って4chanで見た)→openposeの話やったすまん
複数人を塗り分けるには
https://huggingface.co/spaces/shi-labs/OneFormer
the task is panoptic, ADE20K, DiNAT-L
にチェック入れて送信すると
判定がゆるくなる代わりに人数分だけpersonの色が増えるので
適当なペイントツールで色分けして塗る。(人間が重なっていなければ塗り分けなくていい)

the task is panoptic, ADE20K, DiNAT-L
にチェック入れて送信すると
判定がゆるくなる代わりに人数分だけpersonの色が増えるので
適当なペイントツールで色分けして塗る。(人間が重なっていなければ塗り分けなくていい)
輪郭線を白で描くことで、腕組の表現の打率を上げる
701今、天王星のwiki見てきたら軌道傾斜角(i) が0.774°だった (ワッチョイ cb28-BTrK)2023/02/20(月) 01:04:22.35ID:WCL0iJ9f0 >>690 なるほど、人物とかくっきり輪郭線付いてるね 試しに腕組seg作ってみたら重なる表現は相変わらず苦手だけどなかなか良さそうだった 色分けと上手く使い分けたいね https://i.imgur.com/DUfpcSL.png https://i.imgur.com/N9pdqX1.png https://i.imgur.com/2H4eWAU.png https://i.imgur.com/nPccccl.png
Guess Mode (実験的機能)
WebUIの設定 > Enable CFG-Based guidance をオン
ControlNet使用時に Guess Mode を有効にすると
cannyやdepthを使ってプロンプト無しでもいい感じにでっち上げる柔軟に推論する機能
サンプリング回数 50, CFGスケール 3 〜 5 を推奨


例)NSFW, 1girl, NC: (worst quality:1.4), (low quality:1.4) , (monochrome:1.1), のみ
ControlNet使用時に Guess Mode を有効にすると
cannyやdepthを使ってプロンプト無しでも
サンプリング回数 50, CFGスケール 3 〜 5 を推奨


例)NSFW, 1girl, NC: (worst quality:1.4), (low quality:1.4) , (monochrome:1.1), のみ
Controlnetモデル
ここではControlNetで使用する追加のモデルについて紹介。
cnlllite-anystyle
https://huggingface.co/2vXpSwA7/iroiro-lora/tree/m...
画像の構図を維持したまま衣装やキャラなど他の要素を変更できるControlnetモデル。
作者曰く
従来のモデルであるDepthに近いが、それと違い構図は維持したまま髪型を変更することができる。
また、Scribbleのように線画を元絵として改善された絵を出す使い方も可能。
使い方(1111/forge)
うまく動かないときは
https://fate.5ch.net/test/read.cgi/liveuranus/1714... によると「latentをいじったりするような拡張が入っていると、干渉してエラーを吐くっぽい」とのこと。
このニキはKohya HRFixの拡張機能をオフにすると動作したという。
設定でHyperTileがオンになっていてエラーが発生したという報告もあった。
または、出力解像度をモデルの推奨解像度か32の倍数にする。詳しくはAnimagine 3.1tipsやPony Diffusion V6XLtipsのページを参照。
ほかにもfp8で動かない可能性があるが環境によるかも。fp8を有効にした1111WebUI 1.9.0、CN1.1.445で動作した。
画像の構図を維持したまま衣装やキャラなど他の要素を変更できるControlnetモデル。
作者曰く
入力した画像から大雑把に構図と明暗を維持できるように作ったCN(ControlNet)※注意 cnlllite(ControlNet-LLLite)はCNの軽量版でSDXL専用
従来のモデルであるDepthに近いが、それと違い構図は維持したまま髪型を変更することができる。
また、Scribbleのように線画を元絵として改善された絵を出す使い方も可能。
使い方(1111/forge)
- cnlllite-anystyle_v3-step00004000.safetensorsを落としてくる(作者推奨が4000stepだから)
- これをmodels\ControlNet配下に置く
- WebUIを起動する
- ControlNetのEnableをチェック(forgeはControlNetのチェックボックスも有効にする)
- Control TypeはAllのままでPreprocessorもnoneのままでいい
- Preprocessorの横のModelの横の🔄️を押してモデル一覧を再読み込み
- Modelの中の多分一番上にcnlllite-anystyle_v3-step00004000.safetensorsが出てくるからそれを選択
- あとは元にしたい画像をSingle Imageに投げ込んで画像生成
うまく動かないときは
https://fate.5ch.net/test/read.cgi/liveuranus/1714... によると「latentをいじったりするような拡張が入っていると、干渉してエラーを吐くっぽい」とのこと。
このニキはKohya HRFixの拡張機能をオフにすると動作したという。
設定でHyperTileがオンになっていてエラーが発生したという報告もあった。
または、出力解像度をモデルの推奨解像度か32の倍数にする。詳しくはAnimagine 3.1tipsやPony Diffusion V6XLtipsのページを参照。
ほかにもfp8で動かない可能性があるが環境によるかも。fp8を有効にした1111WebUI 1.9.0、CN1.1.445で動作した。
anytest
https://huggingface.co/2vXpSwA7/iroiro-lora/tree/m...
cnlllite-anystyleと同じ月須和・那々氏(https://x.com/nana_tsukisuwa)によるControlNetモデル。SDXL専用。使い方も共通で仕上がりの向上を目指したもの。
そのほか「amがanimagine用、pnがpony用」もある。「それぞれdim8〜dim256まで用意しました、dimが小さいと制御力が下がりますが、用途によってはその方が逆に丁度良くなるかもしれません」(v3に関して)とのこと。
anytest_v4は「step数で性質が変わってて、どれが出来が良いstepか分かんなかったので、試しにそれぞれのstepのCNをマージして平均化した版を上げた」。「入力に対する正確さよりスタイル変換と入力画像の幅広さを重視した/基本v3と同じような使い方が出来るけど、v3に比べると割とガバい、scribble寄りのCNかな/まぁそのガバさ故に、入力がノイズまみれだろうがモザイクかかっていようがぼやけてようが出力が壊れないっていう」。
cnlllite-anystyleと同じ月須和・那々氏(https://x.com/nana_tsukisuwa)によるControlNetモデル。SDXL専用。使い方も共通で仕上がりの向上を目指したもの。
そのほか「amがanimagine用、pnがpony用」もある。「それぞれdim8〜dim256まで用意しました、dimが小さいと制御力が下がりますが、用途によってはその方が逆に丁度良くなるかもしれません」(v3に関して)とのこと。
anytest_v4は「step数で性質が変わってて、どれが出来が良いstepか分かんなかったので、試しにそれぞれのstepのCNをマージして平均化した版を上げた」。「入力に対する正確さよりスタイル変換と入力画像の幅広さを重視した/基本v3と同じような使い方が出来るけど、v3に比べると割とガバい、scribble寄りのCNかな/まぁそのガバさ故に、入力がノイズまみれだろうがモザイクかかっていようがぼやけてようが出力が壊れないっていう」。
ツール
WebUIの拡張機能
Openpose Editor

Posex - Estimated Image Generator for Pose2Image
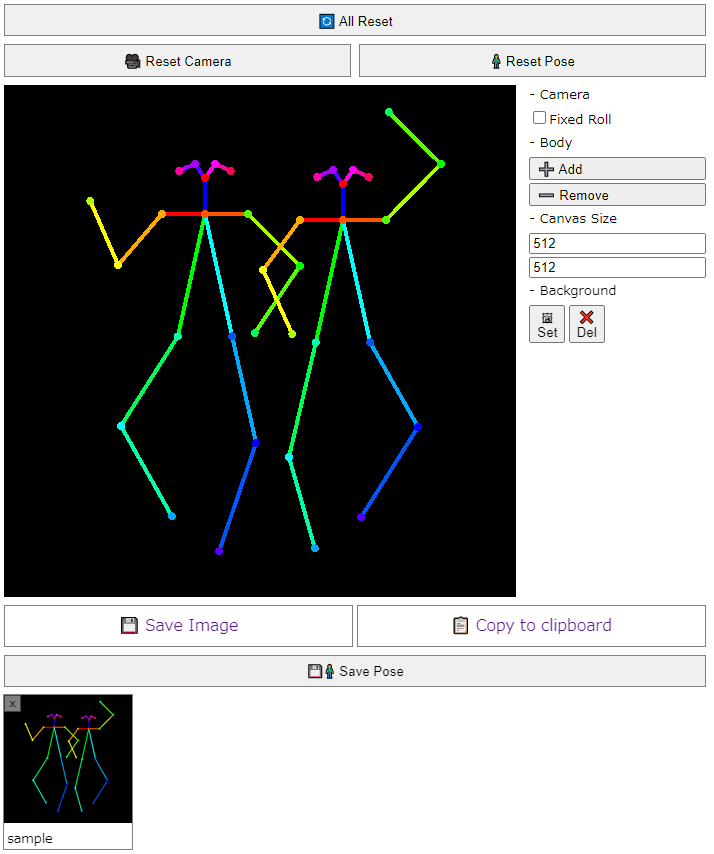
3D Openpose Editor
https://github.com/nonnonstop/sd-webui-3d-open-pos...
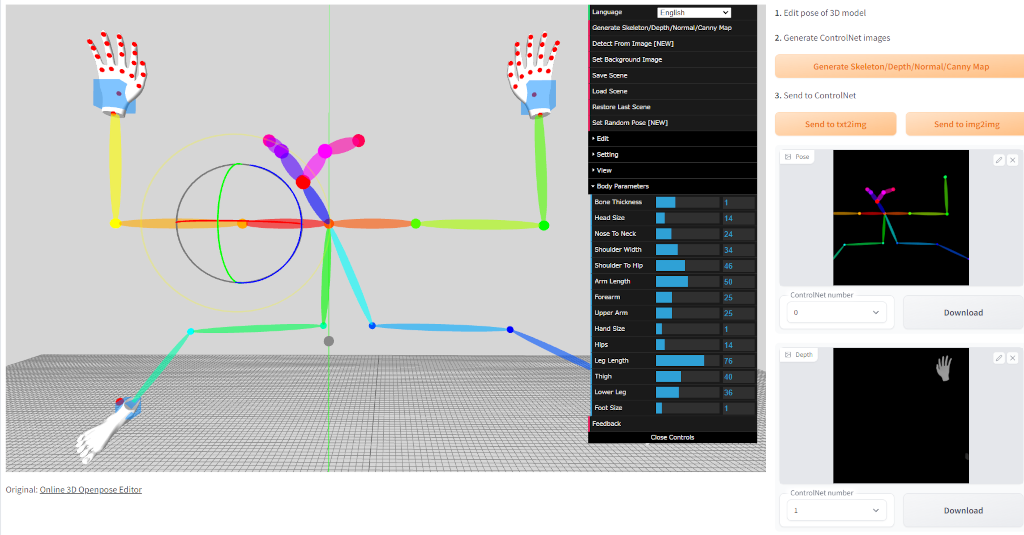
- 棒人間の3Dモデルを操作してOpenposeの画像を作成します。
- Openposeだけでなく、手足のDepth/Normal/Cannyマップの出力にも対応しています。
Webブラウザで動くアプリケーション
PoseMaker - a Hugging Face Space by jonigata
https://huggingface.co/spaces/jonigata/PoseMaker2
- 棒人間の2Dモデルを操作してOpenposeの画像を作成します。
Magic Poser
https://webapp.magicposer.com/
- 人体の3Dモデルを操作してOpenposeやDepth用の画像を作成できます。
Online 3D Openpose Editor
https://zhuyu1997.github.io/open-pose-editor/
- 人体の3Dモデルを操作してOpenposeやDepth用の画像を作成できます。
ローカルで動くアプリケーション
デザインドール
https://terawell.net/ja/
- 人体の3Dモデルを操作してOpenposeやDepth用の画像を作成できます。
- 体験版ではポースをセーブできません。
Blender
Character bones that look like Openpose for blender
ILLUSION製ゲーム(エロゲ)のプラグイン
ハニーセレクト2
- Illusion HoneySelect2 OpenPose Plugin
https://lap0705.gumroad.com/l/ellqe
- ※有料(1$)です。
- openpose_handにも対応しています。
コイカツ
- ControlNet tools for Koikatsu
https://civitai.com/models/17390/controlnet-tools-...
アセット
Openpose
Openposeリグの画像をシェアすることで、手軽にポーズアセットとして配布できるようです。
使用時はプリプロセッサ:None、Model:Openposeにしてポーズ画像をImageにドラッグ&ドロップします。
使用時はプリプロセッサ:None、Model:Openposeにしてポーズ画像をImageにドラッグ&ドロップします。
キャラクター設計図
いわゆるキャラデザ:Turnaround資料を生成できるやつ
とりあえずRTX3060 12GBでHires. fix resize: from 1024x512 to 2201x1100ぐらいまで生成できました。
BlenderのOpenposeRigで作成。
キャラデザ用

生成例

とりあえずRTX3060 12GBでHires. fix resize: from 1024x512 to 2201x1100ぐらいまで生成できました。
BlenderのOpenposeRigで作成。
キャラデザ用
生成例
サンプル
活用例
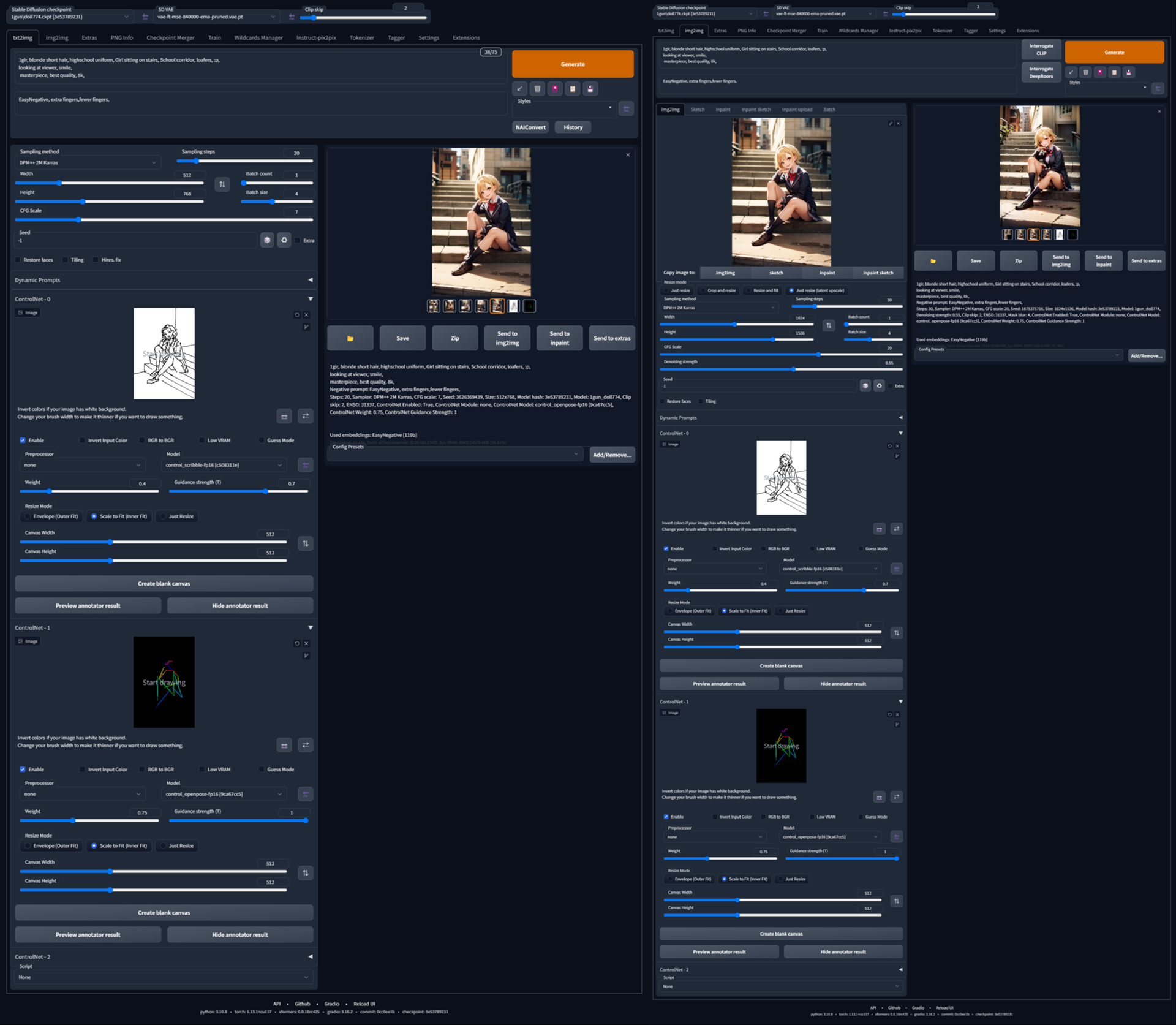
Scribble と Openpose 同時使用
Scribble と Openpose を Multi CN で適用すると、ワイのクソヘボ落書きでも姿勢の打率爆上がりするな Openpose のみやとなんか姿勢固くなっちゃうし、Scribble でサポートするのもいいかもしれん 棒人間はとしあきさんとこのツールを使わせてもろてるで 半透明モードがあるのでキャンバスの上から関節位置を調整してる CN 設定はこんな感じ 一回 t2i で構図決めてから i2i で Step と CFG を上げて高画質化しとる


ずらしハメパンツ修正メソッド(t2i簡単超高打率)
t2iのプロンプトpanties asideで出したずらしハメ…しかし結果はそうじゃない違うんだよ…それが許されるのはブルマとパンツだけなんだ…そんな時に有効な方法 1.画像をControlnetのCannyを通して出力された線画をドラッグ&ドロップでローカルに保存 2.パンツの不要部分をペイントアプリで除去(白で塗りつぶす) 3.修正した線画をControlnetにドラッグ&ドロップ 4.Preprosessor:Canny、Model:Canny、Weight:0.7±0.2程度 5.プロンプトpanties asideの強度を0にする(panties aside:1.5) → (panties aside:0) メリット:超高打率でガチャほぼ不要 デメリット:色が少し薄くなる、細部がちょっと変わる なお、hedでも同様のことが可能。hedの場合は4のPreprosessorをnoneにする。こちらは出力が濃くなる。お好みでどうぞ。



depth と hed 併用
Scribble + Normal, Depth
1. Scribble でゴミのような線画をいい感じのリファレンスにしてもらう 2. Daz で用意したなんとなくそれっぽいモデルを Blender に持ち込んで髪の毛だけ別に配置する 3. Normal, Depth を出力してそれぞれ ControlNet で使用してみる。Prompt はある程度具体的に指定しておいた方がよさそう Normal はちゃんと背景まで作りこんでおかないといけなそう Depth は背景は勝手にいい感じにしてくれるけど後ろ髪をあんまり髪として認識してくれなかった ちな Blender から Normal 出力するときは Viewport Shading から Matcap Normal を適用して、Viewport Render Image で書き出す Outline は無効にしておいた方がエイリアスがなくてよさそう ControlNet での使用時は RGB to BGR にチェック Depth は Depth Pass を Normalize + Invert して書き出す マテリアルに半透明があると Depth にノイズが乗っちゃうので、不透明なマテリアルで Override しておく



inpaint
inpaintのcontrolnetでもできるで 一つの方法としては 元画像をt2iのcanyに通して線画を出力する。線画はドラックアンドドロップで適当なフォルダに落とせば保存できる 胸のところの線画を加工して雑でもいいからおっぱいにする それをcontrolnetに置いて、Preprocessorをnoneにしてmodelをcanyにする 元絵は上半身をインペイントで黒くする プロンプトはshirt lift, breasts, underwearとか描きたい要素を入れる 加工が面倒ならdepth画像無加工でWeight落とすだけでもいけるかも

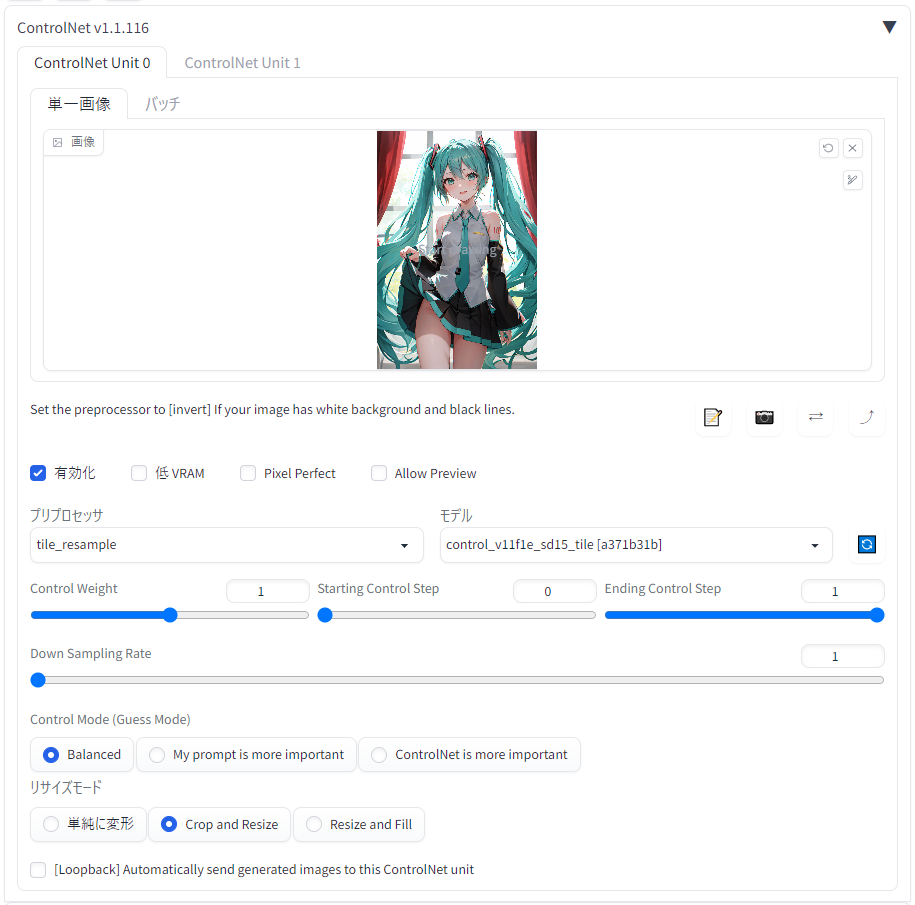
同じ構図で別のモデルに書かせる
同じ構図で別のモデルに書いてほしい場合はControlNet 1.1のTile使うとええな img2imgに比べてCN Tileは全モデルでスカートちゃんとたくし上げてくれとる img2img(ノイズ除去=0.7) (画像1枚目) ControlNet Tile (画像2枚目) 設定 (画像3枚目)


3Dモデルの動画から作成
<3Dモデルの元動画準備> VRoid+Unity/BlenderなりMMDなりコイカツなりで動画撮る→なんかのソフトで連番画像に変換 <基本設定> ・Control Netは2つ使えるようにSettingsで設定しておく →i2iで、CNのlineart anime+tileでシード適当に固定 →好きなプロンプト入れて、index(WebUIの○○/75とか右上に出ている奴)をメモ →MasaのForeground Indexesにその数字を入力、「LOGGING」をクリック <メイン処理> ・連番画像の最初の1枚目を処理、問題なさそうならLOGGINGをRECONに変え全部画像処理
https://fate.5ch.net/test/read.cgi/liveuranus/1684...
lineart_anime+tileで大量bukkake(通称カムカム法)
冗談みたいな量のbukkakeをどんな構図でも安定して出すことに成功したんやで png info https://files.catbox.moe/kw9t5u.png https://files.catbox.moe/9a4wxk.jpg https://files.catbox.moe/cnau87.jpg https://files.catbox.moe/ml99vm.jpg ControlNetを2つ用意して、1つ目をlineart_anime, weight0.3くらい, Start0.1, Ending0.7くらいに設定してこのテクスチャを指定 https://files.catbox.moe/87gvo4.png 2つ目をtileにしてWeight1.0, Start0.0, Ending0.1くらいに設定してこっちのテクスチャを指定(↑のテクスチャでもいい)でOKや https://files.catbox.moe/teinah.png プロンプトでcumを意識させて、lineartとかで精液の輪郭を誘導して、tileとかで精液の色を埋め込んで、3重に指定するのがこだわりポイントや weightやstrengthを弄ればimg2imgやinpaintでも使えるから応用してみてや。テクスチャ変えれば血まみれとかも作れるかもしれへんしhttps://fate.5ch.net/test/read.cgi/liveuranus/1687...
テクスチャ法
0140今、天王星のwiki見てきたら軌道傾斜角(i) が0.774°だった (ワッチョイ 93a6-aBQB) テクスチャ法成功や!画面が派手派手で楽しい! https://i.imgur.com/pmQAaTN.jpg https://i.imgur.com/qswgWhC.jpg https://i.imgur.com/xmWIyuG.jpg https://i.imgur.com/Zk8RbTg.jpg https://i.imgur.com/ZyzOwU3.jpg 0142今、天王星のwiki見てきたら軌道傾斜角(i) が0.774°だった (ワッチョイ ff88-ATpV) >>140 すげぇ綺麗 元のテクスチャってどうやって作ってる? ただのノイズなら生成すぐ止めれば出てくるけど好きな配色のノイズを作る方法がわからない 0151今、天王星のwiki見てきたら軌道傾斜角(i) が0.774°だった (ワッチョイ 93a6-aBQB) 2023/09/02(土) 01:36:35.10ID:1kfWqEzD0 >>142 サンガツ!photoshopのブラシツールで作ったで。カンバスカラーは白。ランダム性もたせるために「散布」「間隔」の項目は要設定や。イメージさえあれば10秒くらいで作れるで。photoshop無くてもフリーソフトでいけそうやな 目的の色・形状でテクスチャつくることが重要やと思うわ ワイの場合は「某英雄王をコンセプトに画面内に沢山のマジックサークルが欲しい→黄色の円一杯あったらいいんじゃね」ってとこからスタートした。背景ノイズはよくわからんから試しに白紙にしたら狙い通りにいった形や ただcontrolnetのtileのweight次第で結構変わるんで要検証や weight 0.7 https://files.catbox.moe/xaw8mm.webp weight 0.3 https://files.catbox.moe/z16wrb.webp 実際に使ったテクスチャ https://files.catbox.moe/s3fpb7.png 知っとるかもしれんが御月氏のnoteを参考に生成したで https://note.com/mitsukinozomi/n/ne735cc59afd1
下記は>>140の最初3つの画像



https://fate.5ch.net/test/read.cgi/liveuranus/1693...
https://note.com/mitsukinozomi/n/ne735cc59afd1
プリプロセッサ Shuffle、モデル Inpaintで構図に一捻り
0414今、天王星のwiki見てきたら軌道傾斜角(i) が0.774°だった (ワッチョイ 7f17-ATpV) 2023/09/03(日) 10:06:34.14ID:cid4WzhP0 プリプロセッサ Shuffle、モデル Inpaintで構図に一捻り加えられるやつの実例を作ってみた プロンプトは両方とも全く同じ 気の利いた構図をお手軽に錬成できて便利やね https://i.imgur.com/DIj2Nbk.jpg https://i.imgur.com/aYTaeFN.jpg 0416今、天王星のwiki見てきたら軌道傾斜角(i) が0.774°だった (ワッチョイ 7f17-ATpV) 設定はこんな感じや、CNに読ませる画像はなんでもええと思う Control Modeは必ずMy prompt is more importantにしすること(これ以外は元画像が浮き出てくる) Preprocessor Resolutionの最適値は画像とモデル、生成したイラストの方向性によるんで微調節必須やな https://i.imgur.com/WHvdiEq.jpg 0458 これって捻り具合はどこで調整するんや とりあえずcontrolnetのweightをいじってみたんやが 0466今、天王星のwiki見てきたら軌道傾斜角(i) が0.774°だった (ワッチョイ 7f17-ATpV) 2023/09/03(日) 16:15:13.11ID:cid4WzhP0 >>458 Preprocessor Resolutionで調節やね >>463 ワイもまだ原理をちゃんと理解してないんやが、t2iでの画像生成にモデルinpaintを用いると 「読ませた画像の色味の境界に沿った構図を生成する」っぽいんや たとえばshuffleで歪ませずに>>416 のなんJで生成するとこういう感じになる https://i.imgur.com/nsBS18Y.png https://i.imgur.com/0wlvurf.png https://i.imgur.com/uo97wer.png https://i.imgur.com/kXFgB0P.png これはこれで構図を誘導したりだまし絵を作るのに有用っぽいんやけど さらにshuffleで曲線的・円的に歪ませて、いわゆるアクションラインを示してやるのが狙いや
下記は>>414の画像


動画
外人ニキやけど早送りでもだいたい分かる https://www.youtube.com/watch?v=ci7NfTsifd0
このページへのコメント
Inpaintで画像修正入れるときに
同じ画像をControlnetに入れて
CannyでWeight控えめ+End段数浅めにしてやると
元の画像からそれほど離れないちょうどいい感じに修正できるから
差分作るときにかなり安定してできるようになったわ
twitter等にある、MMDモデルのダンスをMulti ControllNetで、キャラクターに躍らせるといったものはどうやってやるのでしょうか?
なんか4/15にControlnet機能拡張されてない?以前の数倍ぐらい選択肢があるんだが・・・
まだWebUIで使えないですが、顔を制御するためのControlNetがでました。
ttps://www.sdcompendium.com/doku.php?id=face_landmark_controlnet_0103
Guess Mode (実験的機能)の元画像が見える見える…