HyperNetwork
�ǽ�������ID:QNrw4jY8gQ 2024ǯ03��29��(��) 15:13:46����
HyperNetwork 
����
HyperNetwork�Ȥϡ�Stable Diffusion�Υե�������塼�˥������ΰ�ġ�NovelAI�������ˤʤäƤ���餷����
�ؽ����٤�����������礷�����̤�̵�����ᤫ�����ߤ�����������������ʤ��ۤɤ��Ѥ줿�������ˤ��γ����οʲ���®����
LoRA�Τۤ�����ƹ���ǽ�ʤ��ᡢ��ľ���äƻȤ����ͤʤ���
�ؽ����٤�����������礷�����̤�̵�����ᤫ�����ߤ�����������������ʤ��ۤɤ��Ѥ줿�������ˤ��γ����οʲ���®����
LoRA�Τۤ�����ƹ���ǽ�ʤ��ᡢ��ľ���äƻȤ����ͤʤ���
��ĥ��ǽ
- ʣ����hypernetwork��ޡ������������Ȥ��������������뵡ǽ���ɲ�
����������ǥ�Υޡ����Ȱ㤤������������������˻��ꤷ��hypernetwork������ɤ��ʤ��������Ԥ�������˲���1������������֤��������Ĺ���ʤꤢ�ޤ����Ū�ǤϤʤ���
- �ؽ������Υ��������ѹ��䥯���åפʤ��Ƥ�ؽ�����뵡ǽ
- Optimizer������ɤ��ƥ��������顼��ȯ�������ǽ������ (VRAM8GB�Ǥ�ؽ���ǽ�ˤʤ�äݤ�)
Beta hypernetwork
����Dropout rate���ɲ�
�����Ǥ�2���ܤ��ؤˤ���dropout�����ꤵ��Ƥ��ʤ��ä����ᡢ�������ؤ�hypernetwork����������3���ܰʹߤ��ؤ�Ŭ������ʤ����꤬���ä���
�ޤ���dropout���ͤ�0.3�˸��ꤵ��Ƥ��ꡢ���줬�礭������ΤǤϤʤ����Ȥ����ä����ä���
����Dropout rate�Ϥ�����������褹���Ρ�
��Use dropout. Might improve training when dataset is small / limited.���Υ����å���On�ˤ������β���text�������dropout�ι�¤�ܤ��롣
�����hypernetwork layer structure�ι�¤�Ȱ��פ��Ƥ��ʤ���Фʤ�ʤ���
�㤨��layer structure�� ��1, 2, 2, 1���Ǻ���������硢����dropout�ώ�0, 0.3, 0.3, 0���Τ褦�ˤ��롣
�侩�ͤ�0��0.35�Ǻǽ��0���ꡢ���������ؤǤϤ��ޤ��礭��������Ȥ�ʤ��褦�ˤ���Ȱ��ꤷ�䤹����
�ޤ���dropout���ͤ�0.3�˸��ꤵ��Ƥ��ꡢ���줬�礭������ΤǤϤʤ����Ȥ����ä����ä���
����Dropout rate�Ϥ�����������褹���Ρ�
��Use dropout. Might improve training when dataset is small / limited.���Υ����å���On�ˤ������β���text�������dropout�ι�¤�ܤ��롣
�����hypernetwork layer structure�ι�¤�Ȱ��פ��Ƥ��ʤ���Фʤ�ʤ���
�㤨��layer structure�� ��1, 2, 2, 1���Ǻ���������硢����dropout�ώ�0, 0.3, 0.3, 0���Τ褦�ˤ��롣
�侩�ͤ�0��0.35�Ǻǽ��0���ꡢ���������ؤǤϤ��ޤ��礭��������Ȥ�ʤ��褦�ˤ���Ȱ��ꤷ�䤹����
Show advanced options�����Weight initialization seed�θ��ꡢ�쥤�䡼�������Ȥν������Normal��������ݤν���������Ȥ�0.01�ʳ��˻������뵡ǽ���ɲ�
�̾�Ͽ���ɬ�פϤʤ���
hypernetwork�ϳؽ�����ݤ˥�����ʥ����ɤ��Ȥ��뤳�Ȥ�����Ʊ�����ꡦ�ؽ��Ǻ��ȤäƤ�Ʊ����̤ˤʤ�ʤ����������경���뵡ǽ��
hypernetwork�ϳؽ�����ݤ˥�����ʥ����ɤ��Ȥ��뤳�Ȥ�����Ʊ�����ꡦ�ؽ��Ǻ��ȤäƤ�Ʊ����̤ˤʤ�ʤ����������경���뵡ǽ��
�ʤ������ε�ǽ�Ǻ��줿hypernetwork�ե������extension̵���Ǥ�ư���Ϥ������嵭�ε�ǽ��Ŭ������Ƥʤ���ΤȤ��ư�����(�Ϥ���̤���ڡ�)
Train Gamma
Gradient accumulation
��ȺǶᡢ���Τ�Hypernetwork�ˤ���ܤ��줿��ǽ��
��ñ�ˤ����Ȏ�����®�٤��ʼ��ؤαƶ����ޤ��Ĥľʥ����ư���������Ȥߡ�
4��8�����꤬�侩�͡�
�����ͤ��ѹ������1step�ǽ�����������Ѥ�뤿�ᡢ�ؽ�step�λ��꤬�Ѥ�뤳�Ȥ����ա�
��ñ�ˤ����Ȏ�����®�٤��ʼ��ؤαƶ����ޤ��Ĥľʥ����ư���������Ȥߡ�
4��8�����꤬�侩�͡�
�����ͤ��ѹ������1step�ǽ�����������Ѥ�뤿�ᡢ�ؽ�step�λ��꤬�Ѥ�뤳�Ȥ����ա�
1step�ǽ������������ = batch size �� gradient accumulation�� �ؽ��Ǻब64�硢batch size = 1�� gradient accmulation = 8�ʤ� 1step��8��ν������Ԥ��1epoch��8step�Ȥʤ�(ü���ڤ�Τ�)
Cosine annealing learning rate scheduler
���ꤷ��Step�δ֤�learning rate��岼�����뵡ǽ��Hypernetwork Learning rate�ǻ��ꤷ���ͤ�����͡�Minimum learning rate for beta scheduler�ǻ��ꤷ���ͤ�Ǿ��ͤȤ��ƾ岼����褦�ˤʤ롣
- Step for cycle: 1cycle��Ĺ����step�ǻ��ꤹ�롣�ܰ¤Ȥ��Ƥ�10epoch���餤��(�ؽ��Ǻ�� �� batch size �� Gradient accumulation �� 10epoch ���ڤ�ΤƤ�����)
- Step multiplier per cycle: 1�Τޤޤ�OK
- Warmup step per cycle: Step for cycle���ͤ˹�碌�岼�����롣�ɤΰ̤��ɤ��Τ���Ĵ���档�ǥե�����ͤΤޤޤǤȤꤢ��������̵����
- Decays learning rate every cycle: cycle���ʤऴ�Ȥ˺����ͤ餹�褦�ˤ��롣1�ʤ��������ͤˤʤ롣1�ΤޤޤǤ�����ʤ������ؽ����ƥå���¿������ͽ��ʤ�0.998�ʤɾ������餹���ɤ���
- Saves when every cycle finisher, Generates image when every cycle finishes: ���줾�졢�ؽ�Ψ���Ǿ��ͤ�ã�������ˤ��λ����Υϥ��ѡ��ͥåȥ������¸���롢�ץ�ӥ塼��������¸�������ꡣ
HN��Ŭ����ˡ
��������pt��ե����/Models/hypernetworks���֤���Settings��Hypernetwork�������
Hypernetwork strength�DZƶ��ζ�����Ѥ����롣��ؽ����Ƥ��ޤä�pt�Ǥ���ͤ��㤯���������������뤫�⡣
Hypernetwork strength�DZƶ��ζ�����Ѥ����롣��ؽ����Ƥ��ޤä�pt�Ǥ���ͤ��㤯���������������뤫�⡣
HN+DB
������ؽ�������HN�ȥ�����ؽ�������DB�ʤɤ��Ǹ��Ƹ��٤����Ȥ�����ˡ��
���ޤ�Ƹ��٤��⤯�ʤ������DB�Ǥ⥭���HN���Ȥ߹�碌��������ɤ��ʤä��ꤹ�롣
���ޤ�Ƹ��٤��⤯�ʤ������DB�Ǥ⥭���HN���Ȥ߹�碌��������ɤ��ʤä��ꤹ�롣
�ؽ��ˤĤ���
�����Ǥϡ�Hypernetwork�ˤ��ؽ���Ϥ�Ƥߤ������Ȥ����������ܰ¤Ȥʤ�褦��ñ���������ޤ���
����饯������Ƹ��٤������ˡ���͡����ꡢ����ѥ�����¿�����Ꭲ�����̤�ˤ��Фޤ��Ϥ���äݤ�����뎣�Ȥ������Ȥ���ˤ��ޤ���
����饯������Ƹ��٤������ˡ���͡����ꡢ����ѥ�����¿�����Ꭲ�����̤�ˤ��Фޤ��Ϥ���äݤ�����뎣�Ȥ������Ȥ���ˤ��ޤ���
����Extension
�ǽ�˽��̤�
wd14�Υ�ǥ�����Τ���˺��줿tagger��deepdanbooru����Ѥ������⤤���٤ǥ����դ�������뤿��ڤ����ʤ�ɬ�ܡ�
�ؽ��Ǻ�ʤ��饿�������γ�ǧ������롣Ƴ��ɬ�ܤǤϤʤ��������������
���դ��٤�����
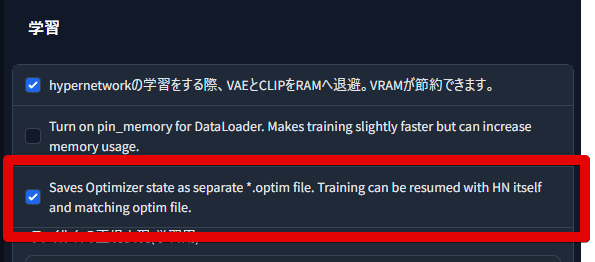
�ޤ���WEB UI���Τ�����γؽ��ˤ��뎢Saves Optimizer state as...���˥����å������������Ŭ�����Ƥ���������
�������������ʤ���硢�ؽ������Ǥ��Ƴ���������Hypernetwork���˲�������ǽ��������ޤ���(����̵���Ƴ��������⤢��ޤ�)
�����hypernetwork�Υե��������optimizer�ξ��֤���¸���Ƥ��ʤ�����ȯ����������Ǥ���
Saves Optimizer...�������ͭ���ˤ��뤳�Ȥ� .optim �ե������Optimizer�ξ��֤���¸���������˺Ƴ��Ǥ���褦�ˤʤ�ޤ���
�ʤ�����Ȥ����̤�Ƥ��뤫�Ȥ����ȡ�Optimizer����¸�����ե���������̤�hypernetwork���Τ����̤�2�ܤǤ��ꡢ���ȥ졼���ΰ����θ����ˤʤꤦ�뤫��Ǥ��� �ʤ�.optim�ե�����ϳؽ��Ƴ����䤵����ɲädzؽ���Ԥ����ˤΤȤ����ΤʤΤǡ�hypernetwork�����������ʤ������Ƥ⤫�ޤ��ޤ���
�ؽ��Ǻ�ν���
�ؽ��Ǻ���Ѱդ��ޤ���
����饯�����ʤɿ�������ǰ��ؽ�������������ؽ������������������η��������Ƥ����Τ����Ӥޤ���
�Ǻ�������ɮ�Ԥ�24��80�����٤ǹԤ�����¿���Ǥ�(ɮ�Ԥϲ����γؽ���ᥤ��˹ԤäƤ��ޤ�)
MonkeyPatch��Ȥ��¤ꡢ�ȥ�ߥ�����ν̾���1:1�β����ˤ���ɬ�פ�����ޤ���
��������������ü�����˥��������äƤ���ʤɴ�ñ���Խ��dzؽ��μ���ˤʤ��Τ��ӽ��Ǥ���ʤ�ڤ��ȥ�ߥ��餤�Ϥ����ۤ���������Ψ���夬��ޤ���
(���饹�ȤΥᥤ��Ȥʤ���ʬ�˥��������äƤ���褦�ʾ��⼫ʬ�ǽ��������ۤ����ɤ����⤷��ޤ����ɤ��餬���ƶ���Ф����Ȥ⤢�ꤽ�μ�֤ȸ���äƤ��뤫�Ȥ��������ȹͤ��Ƥ��ޤ���
�ޤ���HN��Ȥ�����Ȥ��ơ������Ǥ�̵�Խ��Τޤʤळ�Ȥ�����Ȥ��ޤ�)
�ؽ��Ǻ��Ŭ����1�ե�����ˤޤȤ����¸���Ƥ��������� /path/to/images/ ����¸���Ƥ��롢�Ȳ��ꤷ���ä�ʤ�ޤ���
����饯�����ʤɿ�������ǰ��ؽ�������������ؽ������������������η��������Ƥ����Τ����Ӥޤ���
�Ǻ�������ɮ�Ԥ�24��80�����٤ǹԤ�����¿���Ǥ�(ɮ�Ԥϲ����γؽ���ᥤ��˹ԤäƤ��ޤ�)
MonkeyPatch��Ȥ��¤ꡢ�ȥ�ߥ�����ν̾���1:1�β����ˤ���ɬ�פ�����ޤ���
��������������ü�����˥��������äƤ���ʤɴ�ñ���Խ��dzؽ��μ���ˤʤ��Τ��ӽ��Ǥ���ʤ�ڤ��ȥ�ߥ��餤�Ϥ����ۤ���������Ψ���夬��ޤ���
(���饹�ȤΥᥤ��Ȥʤ���ʬ�˥��������äƤ���褦�ʾ��⼫ʬ�ǽ��������ۤ����ɤ����⤷��ޤ����ɤ��餬���ƶ���Ф����Ȥ⤢�ꤽ�μ�֤ȸ���äƤ��뤫�Ȥ��������ȹͤ��Ƥ��ޤ���
�ޤ���HN��Ȥ�����Ȥ��ơ������Ǥ�̵�Խ��Τޤʤळ�Ȥ�����Ȥ��ޤ�)
�ؽ��Ǻ��Ŭ����1�ե�����ˤޤȤ����¸���Ƥ��������� /path/to/images/ ����¸���Ƥ��롢�Ȳ��ꤷ���ä�ʤ�ޤ���
�ؽ����륤�饹�ȤΥ����ե�����κ���
�ؽ����볨�˥�����Ĥ��ޤ���
�����դ��ˤ�wd14 tagger����Ѥ��ޤ���
������Extension��������Ƴ������Ƥ���Ў�Tagger�����֤������Ƥ���Ϥ��Ǥ���
Tagger���֤β��Ύ�Batch from directory�����֤�����ꤷ���ե������β������Ƥ˥������դ��뤳�Ȥ���ǽ�ʤΤǡ���������Ѥ��ޤ���
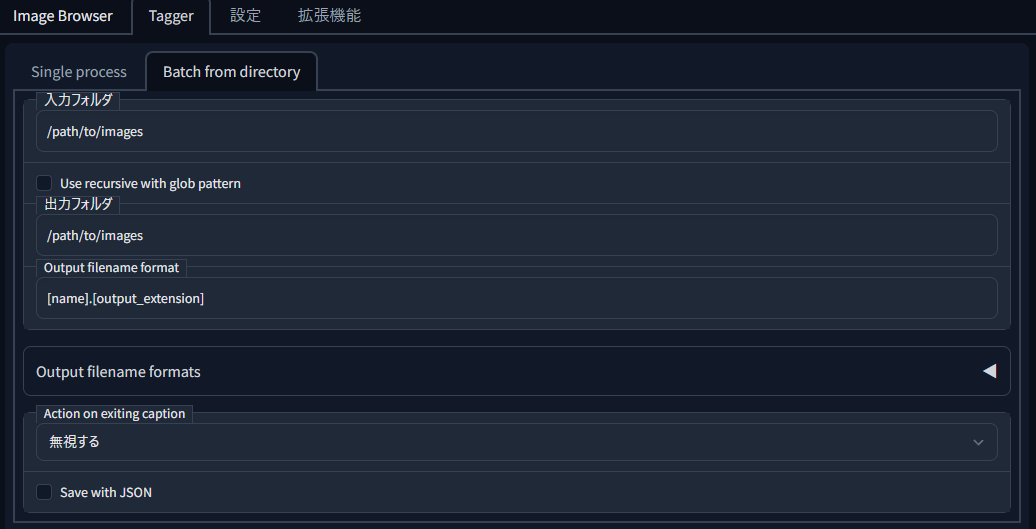
�ޤ��������Ǥ������ϥե���������ϥե�����˳ؽ��Ǻब���äƤ���ե��������ꤷ�Ƥ���������
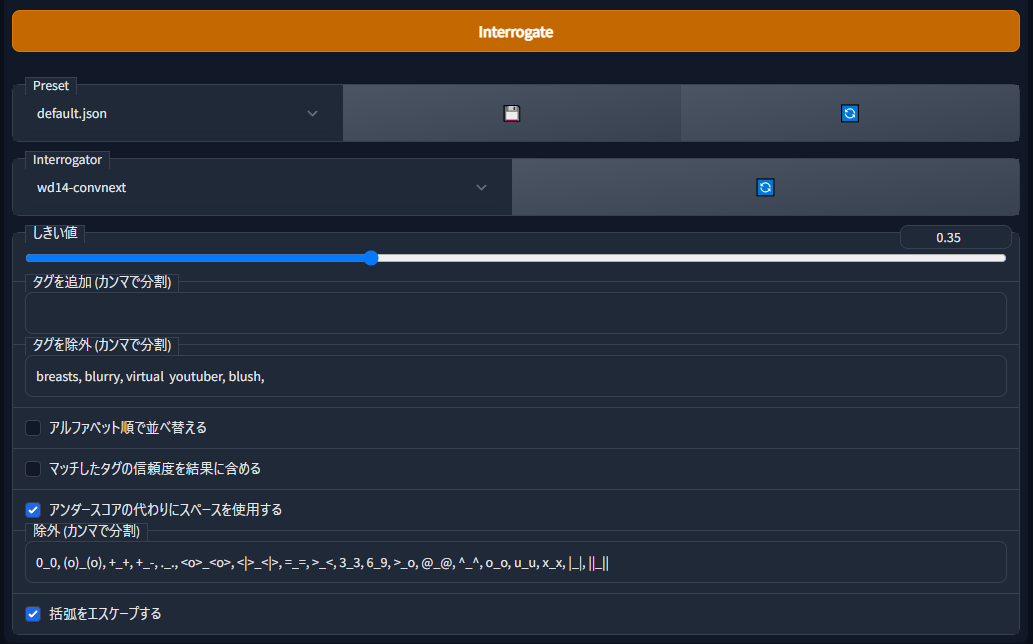
³���Ʋ��ʤǤ�����Interrogator�� wd14-convnext ����ꤷ�ޤ�����������褬̵������Extension���Ť���ǽ��������Τǹ������ޤ��礦��
�����Τ�� (���ߤ� wd14-vit �Ȥ���̾���ˤʤäƤ���) ���⤤���٤ǥ����դ����ʤäƤ���ޤ���
�������ͤ�0.35�Τޤޤ�����פǤ���
�������륿���Ǥ�������ʬ�� breasts, blurry ���˽�������褦�ˤ��Ƥ��ޤ���
danbooru��Ф狼��ޤ��������������ξ��ώ�breasts, small breasts�����礭�ʶ��ξ��ώ�breasts, large breasts���ȶ������ä���Ȥꤢ����breasts�����äƤ��뤳�Ȥ�¿�����ؽ��ˤ�ä�breasts�ΰ�̣����ư���Ƥ��ޤ����Ȥ����뤿��Ǥ���
blurry��Ʊ�ͤ����ܥ�������ܥ��ξ�礽�줾�쎢blurry foreground����blurry background���ȤʤäƤ��뤿�ᡢñ�Τ�blurry�Ϻ������褦�ˤ��Ƥ��ޤ���
���β��Υ����å��ܥå����ώ��������������������˥��ڡ�������Ѥ��뎣����̤������פ��뎣�˥����å���ޤ���
�������Ǥ����� Interrogate �ܥ�����Ƥ���������
���Ф餯�ԤĤȳؽ�������Ʊ��̾���Υƥ����ȥե����뤬���ꤷ���ե�����ˤǤ������äƤ���Ϥ��Ǥ���
�����դ��ˤ�wd14 tagger����Ѥ��ޤ���
������Extension��������Ƴ������Ƥ���Ў�Tagger�����֤������Ƥ���Ϥ��Ǥ���
Tagger���֤β��Ύ�Batch from directory�����֤�����ꤷ���ե������β������Ƥ˥������դ��뤳�Ȥ���ǽ�ʤΤǡ���������Ѥ��ޤ���
�ޤ��������Ǥ������ϥե���������ϥե�����˳ؽ��Ǻब���äƤ���ե��������ꤷ�Ƥ���������
³���Ʋ��ʤǤ�����Interrogator�� wd14-convnext ����ꤷ�ޤ�����������褬̵������Extension���Ť���ǽ��������Τǹ������ޤ��礦��
�����Τ�� (���ߤ� wd14-vit �Ȥ���̾���ˤʤäƤ���) ���⤤���٤ǥ����դ����ʤäƤ���ޤ���
�������ͤ�0.35�Τޤޤ�����פǤ���
�������륿���Ǥ�������ʬ�� breasts, blurry ���˽�������褦�ˤ��Ƥ��ޤ���
danbooru��Ф狼��ޤ��������������ξ��ώ�breasts, small breasts�����礭�ʶ��ξ��ώ�breasts, large breasts���ȶ������ä���Ȥꤢ����breasts�����äƤ��뤳�Ȥ�¿�����ؽ��ˤ�ä�breasts�ΰ�̣����ư���Ƥ��ޤ����Ȥ����뤿��Ǥ���
blurry��Ʊ�ͤ����ܥ�������ܥ��ξ�礽�줾�쎢blurry foreground����blurry background���ȤʤäƤ��뤿�ᡢñ�Τ�blurry�Ϻ������褦�ˤ��Ƥ��ޤ���
���β��Υ����å��ܥå����ώ��������������������˥��ڡ�������Ѥ��뎣����̤������פ��뎣�˥����å���ޤ���
�������Ǥ����� Interrogate �ܥ�����Ƥ���������
���Ф餯�ԤĤȳؽ�������Ʊ��̾���Υƥ����ȥե����뤬���ꤷ���ե�����ˤǤ������äƤ���Ϥ��Ǥ���
�����γ�ǧ
��ǧ���Ƽ��ľ�������������ΤǤ������Ȥꤢ�������������ޤ���
�Ȥꤢ�������ˤ������Τޤ��ι��ܤء�
�Ȥꤢ�������ˤ������Τޤ��ι��ܤء�
textual_inversion_templates ���
textual_inversion_templates/ �ե�����β��˥ƥ�ץ졼�ȥե������������ޤ���
�ʲ��Υƥ����ȥե�������äƤ���������
���פ��ʤ����Ϥ��줾�������ˤʤäƤ���ս���Խ������狼��䤹��̾���� textual_inversion_templates/ �ե�����β�����¸���Ƥ���������
�ʲ��Υƥ����ȥե�������äƤ���������
- ����饯������ؽ�������
character is ����饯������̾��, [filewords]
- �����γؽ�����
artist is ������̾��, illustration drawn by style of ������̾��, [filewords]���ΤȤ�����������hypernetwork��̾��������饯������̾���������̾���Ȱ��פ��Ƥ���ʤ� [name] �Ȥ��뤳�Ȥ����ޤ���
���פ��ʤ����Ϥ��줾�������ˤʤäƤ���ս���Խ������狼��䤹��̾���� textual_inversion_templates/ �ե�����β�����¸���Ƥ���������
Hypernetwork���
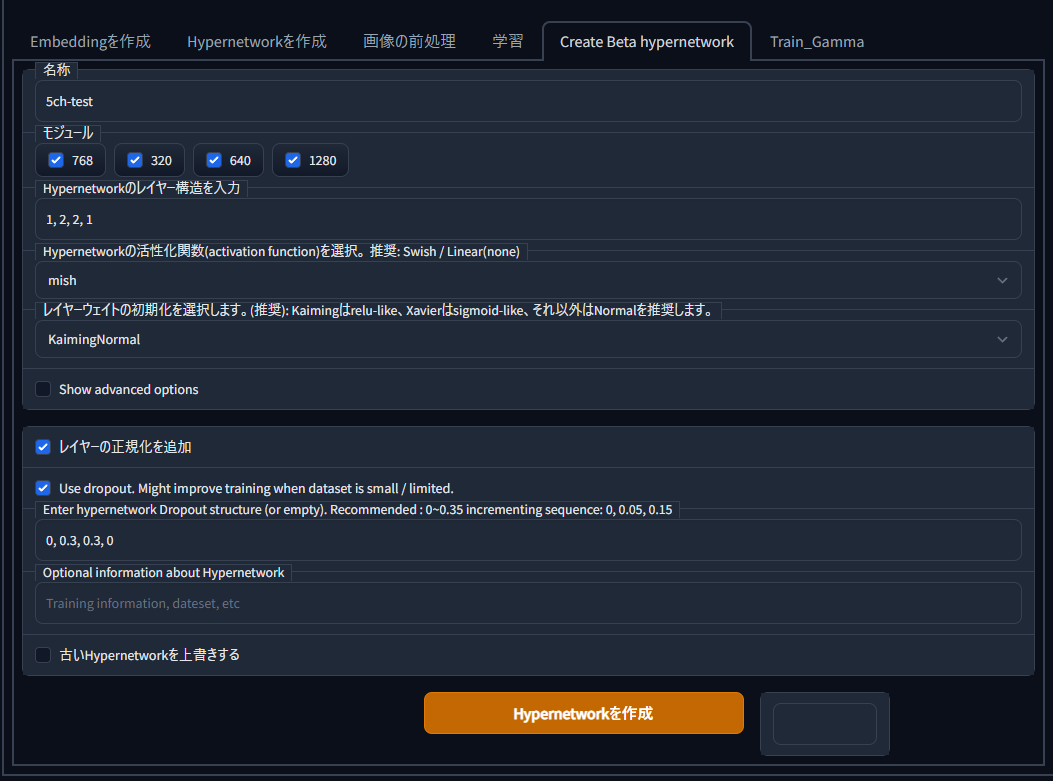
Create Beta hypernetwork���֤���hypernetwork��������ޤ���
- ̾��
- �⥸�塼��
- Hypernetwork�Υ쥤�䡼��¤������
1,2,4,2,1�Τ褦�ʎ������ƿ����ͥåȥ�����ϸ���Ū�ǤϤʤ��ؽ����֤����̤��礭���ʤ�Τǥ������ᤷ�ޤ���
�ޤ��ǥե���Ȥ��ͤǤ���1,2,1�Ǥ⽽ʬ����Ū�ʥϥ��ѡ��ͥåȥ�����뤳�Ȥϲ�ǽ�ʤ��ᡢVRAM��;͵���ʤ��ͤ�1,2,1�ΤޤޤǤ��ޤ��ޤ���
- �������ؿ�
- �쥤�䡼�������Ȥν����
�����Ǥ����դȤ��ơ�KaimingNormal����ꤷ����礽�β��Ύ��쥤�䡼��������(Layer Normalization)���ɲÎ��˥����å���ʤ��ȳؽ���̤�������������Dz���ޤ���
- Show advanced option
- �쥤�䡼�����������ɲ�
�ޤ����쥤�䡼������������Ѥ����硢�ؽ�Ψ��⤯���ʤ��ȳؽ����ʤޤʤ��ʤ�ޤ���
- Use dropout.
�������Υ쥤�䡼�ǤϾ�������ͤ���Τۤ����ͤϤ���礭��ο��ͤ����ꤹ��Ȥ����褦�Ǥ���
WEB UI�ǤΥǥե�����ͤ�0.3�Τ��ᡢ�����Ǥ�0.3����ꤷ�Ƥ��ޤ���
�ʾ�����꤬�Ǥ����鎢Hypernetwork��������ܥ�������ե������������ޤ���
�ؽ���Ԥ�
����ץ���������ѤΥץ���ץȤ�����
�ޤ���txt2img���֤ǥ���ץ��������Ϥ��뤿�������ޤ���
- �ؽ��Ǻ�ե�����ˤ���ƥ����Ȥ���Ŭ���ʤ�Τ����ӡ����Τޤ�Prompt������
- Negative Prompt�ˤ����ʻȤäƤ����Τ�����
- Seed�����
- ����ץ����䥵��ץ���르�ꥺ�ࡢ�������ʤɤ��ä˻���Ϥʤ����������ν��Ϥ˻��֤�����������Ƥ��ޤ��ȥȡ�����γؽ����֤���Ӥ�Τǹ������
�ؽ��γ���
Train_Gamma���֤������Ԥ����ؽ��Ϥ��ޤ���
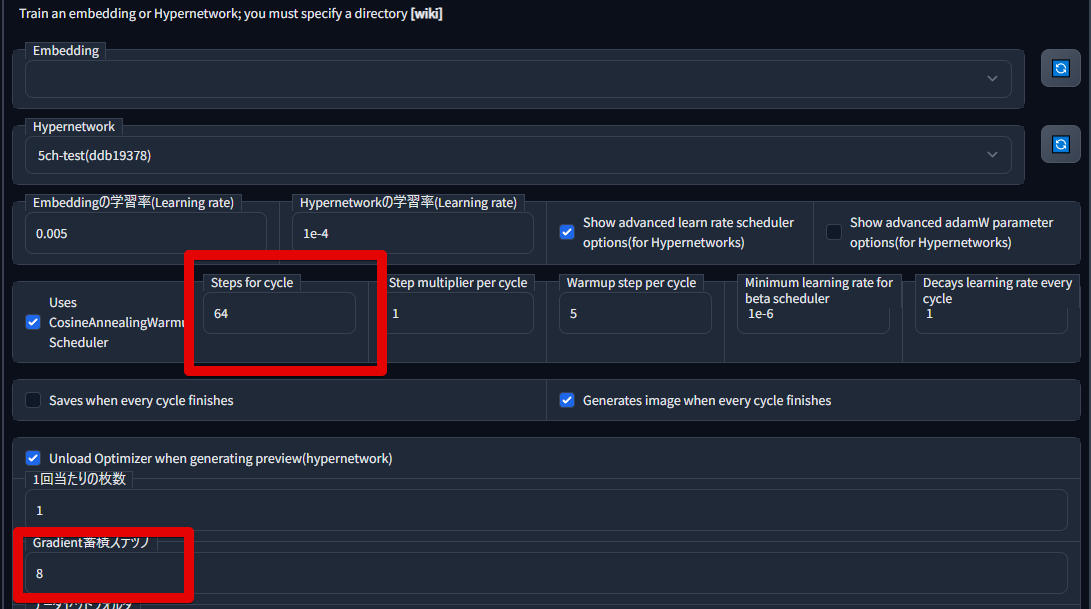
���դ���Τ����ȤǰϤä���ʬ������Ǥ���
����¾����ʬ�ϲ����̤�����ꤷ�Ƥ���������
Gradient���ѥ��ƥåפ�4�ޤ���8�����ꤷ�ޤ�����������ϳؽ�������٤��ʤ�����������VRAM�ξ�����ޤ�����̤�����ޤ���
Steps for cycle���ͤώ��ؽ��Ǻ�� �� Gradient���ѥ��ƥå������ͤ�10�ܤˤ������ͤ����Ϥ��ޤ���ü�����ڤ�ΤƤǤ���
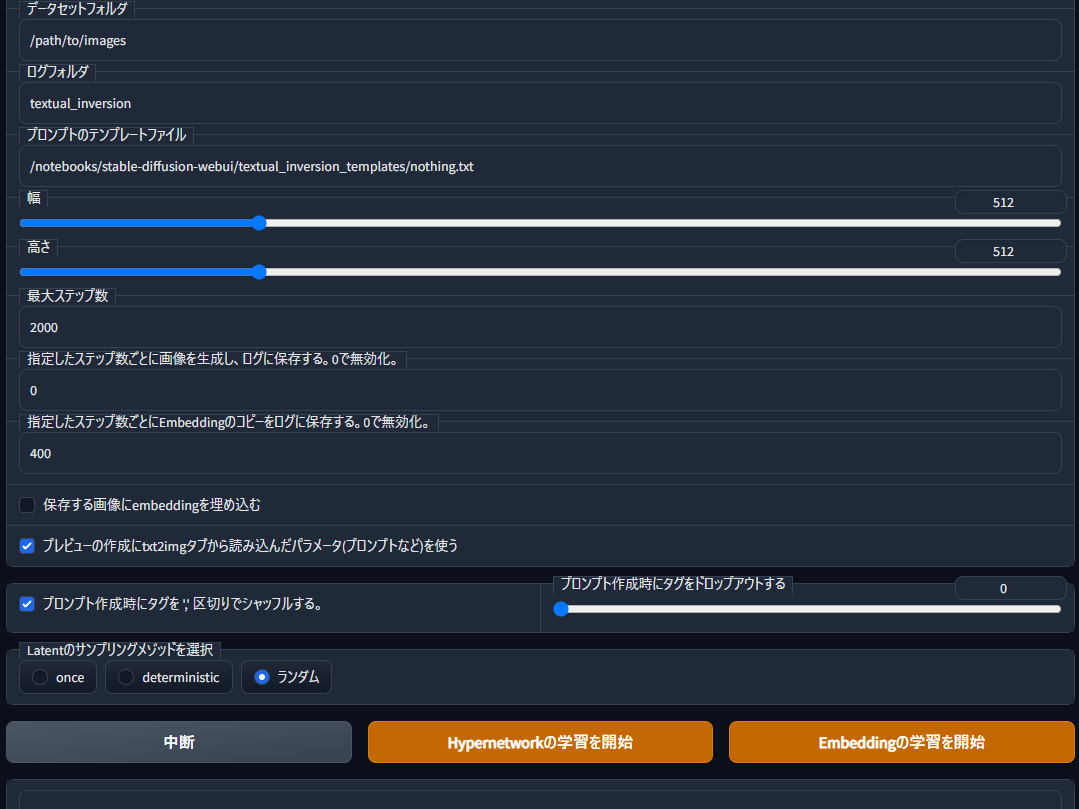
�Ĥ������Ǥ���
�ǡ������åȥե�������ץ���ץȤΥƥ�ץ졼�ȥե�����ˤϤ��줾��ؽ��Ǻ������Ƥ���ե������textual_inversion_templates�ι��ܤǺ�ä��ƥ�ץ졼�Ȥ���ꤷ�ޤ���
���ȹ⤵�ϳؽ����β����Υ������Ǥ���
MonkeyPatch����Ѥ����硢�ؽ������Υ������Ȥ����ǻ��ꤷ�����������碌��ɬ�פϤ���ޤ����ؽ����ΤϤ��������ꤷ���ͤ���˹Ԥ��ޤ���
���������礭������к٤�����ʬ�ޤdzؽ��Ǥ��ޤ�������VRAM���礭���ʤꡢ�ؽ����֤��Ӥޤ���
ɬ�����ȹ⤵���ͤ�Ʊ���ˤ��ޤ���
���祹�ƥå��ˤ�Steps for cycle�ǻ��ꤷ���ͤ�40��50�ܤ��ͤ��ꤷ�����ƥå����Ȥ�Embedding�Υ��ԡ����������¸�ˤ�Steps for cycle�ǻ��ꤷ���ͤ�10�ܤ����Ϥ��ޤ���
Embedding�Υ��ԡ�����¸������ϻ��ꤷ�����ƥå����Ȥ˥����ե�����ˤ��λ���hypernetwork����¸��������Ǥ������ȥ졼����;͵������Τʤ��äȺ٤�����¸���Ƥ⤤���Ǥ��礦��
�Ĥ������ϲ����̤�ˤ��Ƥ���������
�������Ǥ����鎢Hypernetwork�γؽ��ώ��ܥ�����ޤ���
���դ���Τ����ȤǰϤä���ʬ������Ǥ���
����¾����ʬ�ϲ����̤�����ꤷ�Ƥ���������
Gradient���ѥ��ƥåפ�4�ޤ���8�����ꤷ�ޤ�����������ϳؽ�������٤��ʤ�����������VRAM�ξ�����ޤ�����̤�����ޤ���
Steps for cycle���ͤώ��ؽ��Ǻ�� �� Gradient���ѥ��ƥå������ͤ�10�ܤˤ������ͤ����Ϥ��ޤ���ü�����ڤ�ΤƤǤ���
�Ĥ������Ǥ���
�ǡ������åȥե�������ץ���ץȤΥƥ�ץ졼�ȥե�����ˤϤ��줾��ؽ��Ǻ������Ƥ���ե������textual_inversion_templates�ι��ܤǺ�ä��ƥ�ץ졼�Ȥ���ꤷ�ޤ���
���ȹ⤵�ϳؽ����β����Υ������Ǥ���
MonkeyPatch����Ѥ����硢�ؽ������Υ������Ȥ����ǻ��ꤷ�����������碌��ɬ�פϤ���ޤ����ؽ����ΤϤ��������ꤷ���ͤ���˹Ԥ��ޤ���
���������礭������к٤�����ʬ�ޤdzؽ��Ǥ��ޤ�������VRAM���礭���ʤꡢ�ؽ����֤��Ӥޤ���
ɬ�����ȹ⤵���ͤ�Ʊ���ˤ��ޤ���
���祹�ƥå��ˤ�Steps for cycle�ǻ��ꤷ���ͤ�40��50�ܤ��ͤ��ꤷ�����ƥå����Ȥ�Embedding�Υ��ԡ����������¸�ˤ�Steps for cycle�ǻ��ꤷ���ͤ�10�ܤ����Ϥ��ޤ���
Embedding�Υ��ԡ�����¸������ϻ��ꤷ�����ƥå����Ȥ˥����ե�����ˤ��λ���hypernetwork����¸��������Ǥ������ȥ졼����;͵������Τʤ��äȺ٤�����¸���Ƥ⤤���Ǥ��礦��
�Ĥ������ϲ����̤�ˤ��Ƥ���������
�������Ǥ����鎢Hypernetwork�γؽ��ώ��ܥ�����ޤ���
���θ�ϡ�
�ҤȤޤ�����dzؽ��������Τ��ԤƤ�Hypernetwork�����������Ϥ��Ǥ���
��������Ǥ������٤����̤������ޤ��������Ŭ�����ؽ��Ǻ�ν����䥿����Ĵ�����ؽ�Ψ��Ĵ����ؽ����ƥå��ʤ�Ĵ��������ܤ�¿��������;�Ϥ�¿������ȹͤ��Ƥ��ޤ���
���¿�����������㡦���Ի��㤬���ޤ뤭�ä����ˤʤ�й����Ǥ���
��������Ǥ������٤����̤������ޤ��������Ŭ�����ؽ��Ǻ�ν����䥿����Ĵ�����ؽ�Ψ��Ĵ����ؽ����ƥå��ʤ�Ĵ��������ܤ�¿��������;�Ϥ�¿������ȹͤ��Ƥ��ޤ���
���¿�����������㡦���Ի��㤬���ޤ뤭�ä����ˤʤ�й����Ǥ���
���
801 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� f31e-ZR1D)[sage] �������2022/12/17(��) 17:08:25.41 ID:03SdMsEd0 [7/8] ��ä�Hypernetwork��ͭ��������ͤ������Ƥۤ�������ȣ��������θĿ�Ū�ʥ���֤��Ȥ����Ŀ�Ū���ۤ�����ְ�äƤ뤫�⤷��� ��¸�Ρ�stable-diffusion-webui�٥ե�����ˤ���MOD����롣����ȳؽ����֤�Create Beta hypernetwork��Train_Gamma�������� https://github.com/aria1th/Hypernetwork-MonkeyPatch-Extension Create Beta hypernetwork���ֳ�����̾�Τ�Ŭ�������ܸ��Ԥ���ˡ��쥤�䡼��¤��1, 1��Hypernetwork�γ������ؿ���relu��Hypernetwork����� ���������������ֳ��������ϥե�����˳ؽ�����������������뢨����deepbooru��������Ĥ���˥����å������������� Train_Gamma���ֳ�����̾�η�Hypernetwork���ؽ�Ψ��0.00004�ʥǥե��ˡ����祹�ƥåפ�2000�dzؽ����Ϣ�����ä����0.000004��(��帺�餹)��4000�ޤǢ�����ä��餵��˰�帺�餷�ơ�0.0000004�٤�6000�ޤǢ���������ΤǤ��Ƥ� 2000���ʳ��ǰ��ٲ�����t2i�ǽФ��Ƥߤ���ʤ����3000��4000�ޤ��ɲóؽ����Ƥ��鼡�� ������������ؽ��������ʤ������ڤ�ȴ���Ǥ������ʽ��ס��Τϼ���� �ΰ̤ʤ�����������롣�طʽ���������ȸ��������Ƽ¤Ϥ���ޤꤤ��ʤ������Ͳ�����40��50����ߤ������⤷��ʤ������ʤ��Ƥ�Ԥ��뤫�⤷��ʤ����ɤ�äƤʤ��� MOD�Τ������Dz�����ͳѷ����ڤ���ɬ�פϤʤ������ǥե�������ȶ���Ū�˿��ͳѤ��ڤ�Ф����ΤDz�Ĺ�������ͳѲ�������Ĺ������ե����ʬ������3��720x512��512x512��512x720�Ȥ��ǽФ��Ф��ɤ������ʤ���|�ؽ�Ψ�λ����Ż���
���祹�ƥåס�6000
�ؽ�Ψ��4e-05:2000,4e-06:4000,4e-07:6000
�Ǥ�������
845 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (������������ Sa9f-fzMu)[] �������2022/12/17(��) 19:38:59.30 ID:6aA74DbMa HN����������512��512��512��768��768��512��ʬ����3�ե������ä����ɤ����1�ĤΥǡ������åȥե�����ˤޤȤ���ɤ��� ����train_ganma��widh��hight��512��512�Τޤޤ��ɤ��Ρ� ����Фä��Ǥ��ޤ� 849 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (���������Îێ� Spb3-zkD9)[sage] �������2022/12/17(��) 19:42:19.24 ID:jvT5L/5rp > >845 �ޤȤ�Ƥ����� ���ȸ�Ԥ�512�ΤޤޤǤ��� ����˷�����Ƥ����餷������
874 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (���������Îێ� Spb3-zkD9)[sage] �������2022/12/17(��) 20:18:41.08 ID:RAi7H65Kp [5/5] ����ڤ�ȴ�����ϥϥå���Ȥ� �������������褦�Ȥ�����ʥ����Ȥ����������ʤ��Ȥ��ʤ�����ߤ���� ���ȳ����ؽ���50�礯�餤�Ϥ��ä������������⤷���
999 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� f31e-ZR1D)[sage] �������2022/12/18(��) 00:32:38.61 ID:hdK6/sqT0 [4/4] ���������Ĥ����ڤ�ȴ���������������뢪���������Ѥ߲�������betaHypernetwork���뢪 ��Train_Gamma�dzؽ����Ϣ�������в�ǥ����ե�����ˤ���äݤ��Τ�����뢪 �����������������hypernetwork�ɤ߹���ǥ�����



429 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� f31e-ZR1D)[sage] �������2022/12/18(��) 21:28:52.55 ID:hdK6/sqT0 [14/15] ������801�� ���ΤȤ������椷��HyperNetwork�γ����ؽ��ˤĤ��Ƥ�ޤȤ�� ���쥤�䡼��¤�ˤĤ��� ��1, 1 �ۤȤˤ����ڤ����������ʤ餳������̤˹Ԥ��롣�������������ɬ�ס� ��1, 2, 1�����٤����⤤������������������ᤫ�⡩ ��1, 2, 2, 1�۽Ť�����ʪ�Ȥ�ȱ���Ȥ��٤������Ǥ�ؽ�����äݤ�����Mish�β��̤���ʤ��ä��ꡢ���⤽��Leru���ȴο��γ��������ʤ������٤ʳ��ʤ�礦���� ���������ؿ��ˤĤ��� ��Leru�ۺ��ΤȤ���̵��ʴ����� ��Mish�۳����������Τϥ��ӥ���Ĵ�������뤬�Ƥ��ʷ�ϵ��ϻ��롣�����1,2,2,1�ȹ�碌��ȷ��Ū�˰��ֻ��롣�������ʤ�i2i�Ȥ�����������㥯���㰭����
����
���Υڡ����ؤΥ�����
tagger �ϽФ�������ɡ��ؽ������褦�Ȥ���� input path is not a directory
�äƽФ� ����ϡ�
�㤦�����Τˤϥ����դ����褦�Ȥ���Ȥ���
���ϥե������Ƚ��ϥե������˥ե�ѥ������줿�餤����ʤ�����
��ĥ��ǽ���֤���wd14 tagger���ȡ��뤷�����ɥ��֤��ФƤ��ʤ�
stable-diffusion-webui-wd14-tagger�ǹ�äƤ��ʡ�
Ʊ���������ȡ���Ϥ��Ƥ���ä�ɽ���ˤʤäƤ뤱�ɽФƤ��ʤ�
hypernet�Ϥ���commit�˽�Ƥ��̤����λ������Ѥ�ä�
ttps://github.com/AUTOMATIC1111/stable-diffusion-webui/commit/40ff6db5325fc34ad4fa35e80cb1e7768d9f7e75
���������������̤�Ǥ�äƤ뤱�ɾ����ѥ��������ä���Ƹ����⤯�ʤä�����������˺ܤ��Ȥ�
�ں��祹�ƥå���
400
�ڳؽ�Ψ��
1e-4:130,1e-5:260,1e-6:400
��Steps for cycle��
10
�ڥХå���������������ۡʢ�RTX3060�ξ���
2
��Gradient���ѥ��ƥåס�
8
���������ΰ̤ɤ�������������Ǥ�������
�ؽ��Ǻ�����Ϥ��Ĥ�6��10�礰�餤���и��塢���¿�����Ƥ��ɤ��Ϥʤ�ʤ���������
����ΰ̳ؽ���50�硢25�硢15�硢7�����Ӥ�����7�礬���ּ�������ä�
�����ޤǸĿ�Ū�ʴ��ۡ����ͤޤ�
wd14tagger�ǥХå��������褦�Ȥ��Ƥ����ʤ�����������ü������Ȥ�����Τ���
�����ե�����Υѥ������Хѥ��ǻ��ꡢ���ĤΥե����������������֤����������