������Ϻ�Τ����
�ǽ�������ID:i5Oz4epa2g 2024ǯ07��25��(��) 13:44:33����

���祤�饹�ȡû��ͥץ���ץȡ�https://majinai.art/ja/i/LmVqyND
�Ϥ���� 
�����ѤȤ�ή�Ԥ�Ȥ���ˤȤ����⤷�Ƥ����ڡ���
����Ū�ʥΥ��ϥ��Ȥ������ѥڡ����˽ơ������ϾҲ����٤ˡ�
����ۤۤɿ������Ȥ����������Խ����Ƥ��äƤ���������

����Ū�ʥΥ��ϥ��Ȥ������ѥڡ����˽ơ������ϾҲ����٤ˡ�
����ۤۤɿ������Ȥ����������Խ����Ƥ��äƤ���������
�Խ��ˤ����äƤΤ���«
- �Ϥ����
- 2024ǯ
- 2024-07-23 Civitai��SD3�ζػߤ���
- 2024-07-18 AI Reviewers����
- 2024-07-09 Paints-UNDO����
- 2024-07-08 Pony�Ǥ�LoRA�ؽ��������������λ��ѤˤĤ���
- 2024-07-07 ��ǽ�ʸ¤�A1111���ѹ�����������forge�Υե����������������
- 2024-07-06 Stability AI��SD3�Υ饤�����ѹ�
- 2024-06-26 Open Model Initiative��ȯ
- 2024-06-20 ����ȯ�μ�ե���Ȥ����������
- 2024-06-19 ComfyUI����������������������
- 2024-06-18 Civitai��SD3��ǥ뤪��������ǡ����θ�����������
- 2024-06-13 Pony��7������6.9���뤳�Ȥ�
- 2024-06-12 Stable Diffusion 3�����̸���
- 2024-06-10 ComfyUI�Υ�������Ρ��ɡ�Comfy_LLMVISION�פ˥������������Ź��ޤ�Ƥ����Ȥ����
- 2024-06-09 Forge���¸�Ū��ݥ��ȥ���ѹ������ȤΥ��ʥ���
- 2024-06-06 �������ͤθ����Hires.fix��Adetailer�Υ����Ϣư�������ĥ��ǽ�����������
- 2024-06-05 ��̡�褬ή�Ԥ���
- 2024-06-03 SD3�Υ�����ȯɽ
- 2024-05-31 Omost�����������
- 2024-05-31 ��������ץ���ץȤ��¬����ġ���ʤɤ����������
- 2024-05-19 3x3x3mixXL�����������
- 2024-05-12 ebara_pony_2�����������
- 2024-05-08 URL��ޤ���ߤǡ֤⤦;��Ǥ�äƤ����������פȸ����륱������³��
- 2024-05-08 ic-light�����������
- 2024-04-27 cnlllite-anystyle��ή�Ԥ���
- 2024-04-23 Hyper-SD����
- 2024-04-18 Stable Diffusion 3��API�����������
- 2024-04-16 Adobe Premiere Pro�ؤ�Sora�μ�����ȯɽ
- 2024-04-12 �ʤ�JNVA����382 �ɤꥷ���ƥ�ͭ���������
- 2024-03-23 Stability AI�μ��ץ��С������
- 2024-03-18 Animagine XL 3.1������
- 2024-03-14 ������ˡ��ʸ
- 2024-03-13 Animagine�Ǥ������ߥ����餷����ư��Ƚ��
- 2024-03-12 �ܥ���˷㤷��������ץ�����
- 2024-03-12 Pony�������ޤ줿�����θ��椬�����
- 2024-03-01 sd-forge-layerdiffusion�����������
- 2024-02-23 sd-danbooru-tags-upsampler������
- 2024-02-22 Stable Diffusion 3ȯɽ
- 2024-02-22 NovelAI�˥Х��֥��ȥ�ե�����ǽ�����������
- 2024-02-20 ComfyUI��Stable Cascade���б�
- 2024-02-17 pixiv�Ǥ�AI����BAN����꼡��
- 2024-02-16 ư������AI��Sora��ȯɽ
- 2024-02-13 Stable Cascade����
- 2024-02-12 ZLUDA������
- 2024-02-06 stable-diffusion-webui-forge����
- 2024-01-19 Pony Diffusion V6 XL������ˤʤ�
- 2024-01-11 Animagine XL 3.0������
- 2023ǯ
- 2023-12-12 ���������ˤ��2023��������AI�ޤȤ�
- 2023-12-10 PNG�ǽ��Ϥ��������Υ�ǡ�����ݻ������ޤ�JPEG���Ѵ�����ġ��뤬GitHub�˸��������
- 2023-12-05 ��ʪ������ư�������Ѥ�³���о�
- 2023-11-29 SDXL Turbo����
- 2023-11-28 WebUI��Generate�������˥ܥ���˵�ǽ�Ĥ��������ܥ�����ɲä�����ˡ����Ƥ����
- 2023-11-20 LCM LoRA�β�������Ҳ𤵤��
- 2023-11-16 NovelAI�������3������
- 2023-11-01 nVIDIA�Υ���ե��å��ɥ饤�Ф��ᥤ��������Ѥ��ʤ���������
- 2023-10-29 ɱ���Υץ���ץȤ���ɽ�����
- 2023-10-21 NovelAI������ǥ�NovelAI Diffusion Anime V2��ȯɽ
- 2023-10-01 DALLE-3��Bing Image Creator���ʲ�
- 2023-09-18 �ִ�ñ�ץ���ץȥ��˥�פ����������
- 2023-09-12 Animatediff����
- 2023-09-08 ����륲�����Υ������åȤ���ġ���
- 2023-08-10 SDXL���ѥե���ȥ���ɡ�Fooocus����
- 2023-08-06 ������ץ��������
- 2023-07-28 SDXL 1.0������
- 2023-07-19 Waifu Diffusion XL(WDXL)������/SDXL 1.0���������
- 2023-07-14 ���५��ˡ�����
- 2023-07-12 ���ߤ��ܥ���ξ���
- 2023-07-12 5ch�˴ؤ��른������Ҥ�����
- 2023-07-11 Janestyle�˴ؤ���5ch���Ĥ�����
- 2023-07-11 ������ɤ߽��뤵�ޤ��ޤ���ˡ����Ƥ����
- 2023-07-10 ��֥�ǥ�����ʤ��ʤ�
- 2023-07-03 superhappy peacesign�ץ���ץȤ�ή�Ԥ���
- 2023-06-30 ���५��ˡ���Ҳ𤵤��
- 2023-06-29 �ؽ���ǥ뤫�鳵ǰ��õ����ˡ��LECO�ˤ�ȯɽ�����
- 2023-06-27 NVA���ʹߤǥ�����ץȰʳ�����������������3��ʾ����ٿ��ӤƤ������������
- 2023-06-18 ���������LoRA���͵����
- 2023-04-30 �ե�åȥ��顼LoRA��ͥ���Ŭ�Ѥ���Ƚ��ߤ�������
- 2023-04-21 Google Colab ��̵���ץ���Automatic1111�����Ѥ��ػߤˤʤ�
- 2023-04-20 imgur����Ƥ�������ˡ�nsfw���ػߤˤʤ�
- 2023-04-17 basilmix�ξ������Ѥ��ػߤ����
- 2023-04-12 AI�������졧�ʤ�JRBC����Ω��
- 2023-04-08 �����ꤹ��Controlnet���Ǥ�
- 2023-04-07 �ͥ��ƥ��֥ץ���ץȥ��ǥ��ƥ���
- 2023/04/04(��)��LoRA�ؽ�GUI�����̳ؽ��� Stable Diffusion XL
- 2023/04/03(��)�åݥ��ࡢ�ڹ�˥������̥ޡ�����ɽ���ܸ���
- 2023/04/02(��) �����̳ؽ�Ψ/������dim(rank)���ɲá��ڹߥ�����̥ޡ����λ���
- 2023/03/31(��)��ToMe (Token Merging for Stable Diffusion)
- 2023/03/28(��) �ؽ������������512�ǽ�ʬ���� VS 1024�ǹ��������
- 2023-03-27 �ʤ�JNVA������������
- 2023-03-25 ����
- 2023-03-25 MultiDiffusion
- 2023-03-23 ��������AI�����ӥ����祹�������(�ͥåȥ����ӥ���)
- 2023-03-20 Windows Defender��VAE�ҤȤߤʤ�
- 2023-03-18 torch2.0�ǹ�®��
- 2023-03-11 ����������ץ顼UniPC
- 2023-03-09 ������ץ��������
- 2023-03-09 Colab�Υǥե����Python��3.9.16��
- 2023-03-05 LoCon
- 2023-02-28 chilloutmix�������
- ControlNet�ε�ǽ��������Ƚ��
- 2023-02-13 WD1.5�¤��Ф���ControlNet���б�����������Ѥʰ���
- 2023-02-06 ������ץ�����
- 2023-02-05 ����̱������
- 2023-01-28 HN�Υɥ��åץ��������褷���ʤĤ��Ǥ�LoRA���դ�����
- 2023-01-28 pix2pix��ǥ�ޡ������������줿
- 2023-01-24 Anything-v3.0�����
- 2023-01-23 torch��xformers�ο侩�С��������kohya��LoRA�������б�
- 2023-01-22 HN��Lora�����������ѹ�
- 2023-01-14 ��ǥ�ޡ�������³��
- 2023-01-11 StableTuner
- 2023-01-05 1111�ü�����
- 2023-01-05 �֤����
- 2023-01-04 ��������
- ǯ��ǯ�Ϥ�ư��
- 2022ǯ����
- ��������
2024ǯ
2024-07-23 Civitai��SD3�ζػߤ���
Civitai�ϥ饤���ʤɤη�ǰ�ˤ��SD3�Υ�ǥ��LoRA�θ�����ػߤȤ��Ƥ���������褵�줿�Ȥ��ƶػߤ���������
�饤����������ʤ����ˤΤ���Civitai��Ǥ�SD3����Ѥ��Ƥ������ϤǤ��ʤ���
https://civitai.com/articles/6221/sd3-unbanned-com...
�饤����������ʤ����ˤΤ���Civitai��Ǥ�SD3����Ѥ��Ƥ������ϤǤ��ʤ���
https://civitai.com/articles/6221/sd3-unbanned-com...
2024-07-18 AI Reviewers����
2024-07-09 Paints-UNDO����
ControlNet��stable-diffusion-webui-forge�κ��lllyasviel�ˤ�ꡢPaints-UNDO�Ȥ������������餽�β��������襷��������Ϥ����ǥ뤪��ӡ���������ư��Ȥ�����¸���륳���ɤ��������줿��
�ܺ٤ϥ�ݥ��ȥ껲��
https://github.com/lllyasviel/Paints-UNDO
README�Ǥ�Anaconda�ǤΥ��ȡ�����ˡ�����ܤ���Ƥ��뤬��Windows��Python3.10.X��Cuda�Ķ�����ư�����������μ��ϰʲ����̤�(3.11�ϳ�ǧ���Ƥ��ʤ���3.12��pytorch���б�����������ǽ���Ȭ��2024/7/10���ߤ�ư���ʤ�)
���ȡ��뤷�����ǥ��쥯�ȥ�ذ�ư��
�����ܰʹߵ�ư�������Ȥ���
ư����������ȡ��Ǹ��ffprobe�����Ĥ���ʤ��Ȥ������顼���Ф뤬��results�ǥ��쥯�ȥ����mp4�ե����뤬��������Ƥ��롣
�ܺ٤ϥ�ݥ��ȥ껲��
https://github.com/lllyasviel/Paints-UNDO
README�Ǥ�Anaconda�ǤΥ��ȡ�����ˡ�����ܤ���Ƥ��뤬��Windows��Python3.10.X��Cuda�Ķ�����ư�����������μ��ϰʲ����̤�(3.11�ϳ�ǧ���Ƥ��ʤ���3.12��pytorch���б�����������ǽ���Ȭ��2024/7/10���ߤ�ư���ʤ�)
���ȡ��뤷�����ǥ��쥯�ȥ�ذ�ư��
git clone https://github.com/lllyasviel/Paints-UNDO.git cd Paints-UNDO python -m venv venv .\venv\scripts\activate pip install xformers pip install -r requirements.txt pip install torch==2.3.0 torchvision==0.18.0 torchaudio==2.3.0 --index-url https://download.pytorch.org/whl/cu121 python gradio_app.py
�����ܰʹߵ�ư�������Ȥ���
.\venv\scripts\activate python gradio_app.py
ư����������ȡ��Ǹ��ffprobe�����Ĥ���ʤ��Ȥ������顼���Ф뤬��results�ǥ��쥯�ȥ����mp4�ե����뤬��������Ƥ��롣
2024-07-08 Pony�Ǥ�LoRA�ؽ��������������λ��ѤˤĤ���
Pony��LoRA��ؽ�����ݤˡ��ؽ������Υ����˥���������(score_9_up�ʤ�)������뤳�Ȥdzؽ���Ψ��夲����ˡ������˾�롣
PonyDiffusionV6XLTips�ؤ����Ĥ��쥹��ȴ�褷����
PonyDiffusionV6XLTips�ؤ����Ĥ��쥹��ȴ�褷����
2024-07-07 ��ǽ�ʸ¤�A1111���ѹ�����������forge�Υե����������������
https://github.com/Panchovix/stable-diffusion-webu...
I've forked Forge and updated (the most I could) to upstream dev A1111 changes!�ʥե���������Panchovix��ˤ��ܺ٤����ܤ��줿reddit����åɡ�
I've forked Forge and updated (the most I could) to upstream dev A1111 changes!�ʥե���������Panchovix��ˤ��ܺ٤����ܤ��줿reddit����åɡ�
Forge��5����֥��åץǡ��Ȥ���ʤ��ä��塢A1111����ν��פʥ��åץǡ��Ȥ侮���ʥѥե����ޥ��åץǡ��Ȥ���������礱�Ƥ����Τǡ�ɬ�פǤ���С����Ȥ��䤹����������˹礦�褦�˥��åץǡ��Ȥ��٤�����Ƚ�Ǥ��ޤ�������DeepL�ˤ���������ȤΤ��Ȥǡ�DoRA���ݡ��Ȥ䥹�����塼���ʬΥ�ʤɡ�forge�ι��������ڤ��Ƥ���������A1111�����ä��羮���ѹ���Ŭ�Ѥ���Ƥ���ʸĿ�Ū�ˤ�avif�Υ��ݡ��Ȥ����ˡ�������SD3�б��ʤɤϴޤޤ�Ƥ��ʤ���Ƴ����ˡ�ʤɤξܺ٤Ͼ嵭reddit�Ȥ�����ɤ���������
2024-07-06 Stability AI��SD3�Υ饤�����ѹ�
https://stability.ai/news/license-update
���ܸ�: https://ja.stability.ai/blog/license-update
Stability AI��SD3 Medium��"Stability AI Community License"�Ȥ����������饤���Τ�ȸ������뤳�Ȥˤ�����
�ޤ���SD3 Medium�Ǹ���������ξ��ǿ��Τ���þ���븽�ݤ��н褹��ȤΤ��ȡ�
���ܸ�: https://ja.stability.ai/blog/license-update
Stability AI��SD3 Medium��"Stability AI Community License"�Ȥ����������饤���Τ�ȸ������뤳�Ȥˤ�����
Our new Community License is now free for research, non-commercial, and commercial use. You only need a paid Enterprise license if your yearly revenues exceed USD$1M and you use Stability AI models in commercial products or services.ǯ�֤μ�����100���ɥ�(���ܱߤ���1.5����)̤���Ǥ���и��桢���ѡ�������鷺̵���ǻ��ѤǤ��롣
�ޤ���SD3 Medium�Ǹ���������ξ��ǿ��Τ���þ���븽�ݤ��н褹��ȤΤ��ȡ�
2024-06-26 Open Model Initiative��ȯ
������ư�衦���������Τ���Υ����ץ�饤����AI��ǥ�γ�ȯ���ʤ��뤳�Ȥ���Ū�ˤ����ץ��������ȤǤ���Open Model Initiative��ȯ������ȯ���С���Invoke��ComfyOrg��Civitai��LAION����С����ä������ä��ʤ����Ȥˤʤä���
³��ǿ����ʥ��С���ȯɽ���졢������ˤ�Pony Diffusion�γ�ȯ�ԤǤ���AstraliteHeart��⤤�롣
ȯɽ��https://www.reddit.com/r/StableDiffusion/comments/...
³��https://www.reddit.com/r/StableDiffusion/comments/...
³��ǿ����ʥ��С���ȯɽ���졢������ˤ�Pony Diffusion�γ�ȯ�ԤǤ���AstraliteHeart��⤤�롣
ȯɽ��https://www.reddit.com/r/StableDiffusion/comments/...
³��https://www.reddit.com/r/StableDiffusion/comments/...
2024-06-20 ����ȯ�μ�ե���Ȥ����������
����������ɡ�https://tiananmen-square.booth.pm/items/5848321
https://fate.5ch.net/test/read.cgi/liveuranus/1718...
====
774: ������[Lv.42] (�������� 1acc-Fyfa) sage 2024/06/20(��) 22:40:00.63 ID:1zaStuBA0
https://mega.nz/file/gJ1DmS5b#s5FpmhxfKujG4ST8hKQ_...
����μ�����ʸ���ե���Ȥ���������
����������ե����̾�ϡ֤����ˤʤ���Фʤ��פǽФƤ���Ϥ���
��ʬ���Ȥ������������ե���Ȥ䤫�餽���礷�����Ǥ�ʤ����餽���ϴ�Ǧ���
�Ҥ餬�ʡ��������ʤΤ��б�
�ƥ��ˡ֤��ס֤ϡס֤�פΥХꥨ�������

====
https://fate.5ch.net/test/read.cgi/liveuranus/1718...
====
776: ������[Lv.42] (�������� 1acc-Fyfa) sage 2024/06/20(��) 22:44:28.07 ID:1zaStuBA0
�ե���ȼ��Τκ����ۤ�����Τ߶ػߤǤ��Τ��
���Υե���Ȥ����˽Ф����Ȥ��ϥ磻�����Ȥ�������
====
https://fate.5ch.net/test/read.cgi/liveuranus/1718...
====
158: ������[Lv.43] (�������� 1a56-Fyfa) sage 2024/06/21(��) 22:07:34.16 ID:iyTJupHe0

https://tiananmen-square.booth.pm/items/5848321
����������ե���ȡ�
���Ф����Ȥ��ϡ��ȥޡ����Ȥ��ĽDz��ˤʤ�ʸ�������ä�Ĵ����������
����Ƥ����Ƥ����ǡ�
���Ф餯������ͭ���ˤ��뤫�⤷���Ǥ��������˥���������ɤ��Ƥ����Ƥ�
https://fate.5ch.net/test/read.cgi/liveuranus/1718...
====
774: ������[Lv.42] (�������� 1acc-Fyfa) sage 2024/06/20(��) 22:40:00.63 ID:1zaStuBA0
https://mega.nz/file/gJ1DmS5b#s5FpmhxfKujG4ST8hKQ_...
����μ�����ʸ���ե���Ȥ���������
����������ե����̾�ϡ֤����ˤʤ���Фʤ��פǽФƤ���Ϥ���
��ʬ���Ȥ������������ե���Ȥ䤫�餽���礷�����Ǥ�ʤ����餽���ϴ�Ǧ���
�Ҥ餬�ʡ��������ʤΤ��б�
�ƥ��ˡ֤��ס֤ϡס֤�פΥХꥨ�������
- -*/�˥ϡ���
====
https://fate.5ch.net/test/read.cgi/liveuranus/1718...
====
776: ������[Lv.42] (�������� 1acc-Fyfa) sage 2024/06/20(��) 22:44:28.07 ID:1zaStuBA0
>774��������OK�䤫����ܹ����˻ȤäƤ���Ƥ����ǡ�
�ե���ȼ��Τκ����ۤ�����Τ߶ػߤǤ��Τ��
���Υե���Ȥ����˽Ф����Ȥ��ϥ磻�����Ȥ�������
====
https://fate.5ch.net/test/read.cgi/liveuranus/1718...
====
158: ������[Lv.43] (�������� 1a56-Fyfa) sage 2024/06/21(��) 22:07:34.16 ID:iyTJupHe0
https://tiananmen-square.booth.pm/items/5848321
����������ե���ȡ�
���Ф����Ȥ��ϡ��ȥޡ����Ȥ��ĽDz��ˤʤ�ʸ�������ä�Ĵ����������
����Ƥ����Ƥ����ǡ�
���Ф餯������ͭ���ˤ��뤫�⤷���Ǥ��������˥���������ɤ��Ƥ����Ƥ�
2024-06-19 ComfyUI����������������������
�����ݥ��ȡ�https://x.com/ComfyUI/status/1803109283263029616
���������ȡ�https://www.comfy.org/
ComfyUI�κ�ԤǤ���comfyanonymous���StabilityAI����ҡ�SwarmUI�κ�Ԥ�mcmonkey4eva��ʤɤȤȤ�ˡ�Comfy Org�פ���Ω�����������ץ�����AI�ġ����ȯŸ����̱�粽���뤳�Ȥ���ɸ�Ȥ��Ƥ��롣
���������ȡ�https://www.comfy.org/
ComfyUI�κ�ԤǤ���comfyanonymous���StabilityAI����ҡ�SwarmUI�κ�Ԥ�mcmonkey4eva��ʤɤȤȤ�ˡ�Comfy Org�פ���Ω�����������ץ�����AI�ġ����ȯŸ����̱�粽���뤳�Ȥ���ɸ�Ȥ��Ƥ��롣
2024-06-18 Civitai��SD3��ǥ뤪��������ǡ����θ�����������
SD3�˴ؤ���饤����(�ä˾��ѥ饤�����ϰ�)�������Ƥʤ��Ȥ��顢����Ū�ʥ�ǥ��������饤�����������̵ͭ�ʤɤΰ������ǧ�Ǥ���ޤǡ�
Civitai��SD3�˴ؤ����ǥ�ڤ������ǡ���(Lora��ControlNet�ʤɤ�SD3��١����ˤ����ؽ���̤�ޤ�)�θ��������Ū����ߤ��줿��
https://civitai.com/articles/5732
�⤷���Ǥ�SD3�˴ؤ���ؽ���ײ褷�Ƥ���ͤϡ��ܹ��ܵ��ܻ����ˤ�����Civitai�Ǹ����Ǥ��ʤ��Τ�������
Civitai��SD3�˴ؤ����ǥ�ڤ������ǡ���(Lora��ControlNet�ʤɤ�SD3��١����ˤ����ؽ���̤�ޤ�)�θ��������Ū����ߤ��줿��
https://civitai.com/articles/5732
�⤷���Ǥ�SD3�˴ؤ���ؽ���ײ褷�Ƥ���ͤϡ��ܹ��ܵ��ܻ����ˤ�����Civitai�Ǹ����Ǥ��ʤ��Τ�������
2024-06-13 Pony��7������6.9���뤳�Ȥ�
SD3��١�����Pony Diffusion V7����ͽ����ä�����
SD3�ξ��ѥ饤����ۣ��ʤ��Ȥʤɤ���ͳ�ˡ�SDXL���١�����V6.9�����ȯɽ������
�ܤ����ϡ�https://civitai.com/articles/5671/towards-pony-dif...
SD3�ξ��ѥ饤����ۣ��ʤ��Ȥʤɤ���ͳ�ˡ�SDXL���١�����V6.9�����ȯɽ������
�ܤ����ϡ�https://civitai.com/articles/5671/towards-pony-dif...
2024-06-12 Stable Diffusion 3�����̸���
��ݥ��ȥ�: https://huggingface.co/stabilityai/stable-diffusio...
�֥���: https://ja.stability.ai/blog/stable-diffusion-3-me...
�ǥ�ڡ�����https://huggingface.co/spaces/stabilityai/stable-d...
StabilityAI����ȯ����Stable Diffusion�κǿ��Ǥ��������줿������������줿�Τϥѥ�����20����Medium��
�����SD�����þ�����������ץ���ץȤؤ�����٤������������ޤ�ʸ���������������Ǥ���褦�ˤʤä���
�����������б����Ƥ���WebUI��ComfyUI�Τߡ��ޤ���ǥ�Υ���������ɤˤ�Huggingface�Υ桼������Ͽ��ɬ�ס�
���������Ѥ���ˤ�ͭ���Υ饤����ɬ��
��comfy_example_workflows�פ��饵��ץ����ե����Ρ�sd3_medium_example_workflow_basic.json�פ����������ɤ���ComfyUI���ɤ߹��ࡣ
����ե����Ρ�TripleClipLoader�פ���³������LoadCheckpoint�סʥ�ǥ�������ˤ���ľ�ܡ�ClipTextEncode�סʥץ���ץ�������ˤ�Clip�ν��Ϥ�Ҥ��ʤ�����
�֥���: https://ja.stability.ai/blog/stable-diffusion-3-me...
�ǥ�ڡ�����https://huggingface.co/spaces/stabilityai/stable-d...
StabilityAI����ȯ����Stable Diffusion�κǿ��Ǥ��������줿������������줿�Τϥѥ�����20����Medium��
�����SD�����þ�����������ץ���ץȤؤ�����٤������������ޤ�ʸ���������������Ǥ���褦�ˤʤä���
�����������б����Ƥ���WebUI��ComfyUI�Τߡ��ޤ���ǥ�Υ���������ɤˤ�Huggingface�Υ桼������Ͽ��ɬ�ס�
���������Ѥ���ˤ�ͭ���Υ饤����ɬ��
- �������ǤκǤ��ñ�ʥ�������Ƴ����ˡ
��comfy_example_workflows�פ��饵��ץ����ե����Ρ�sd3_medium_example_workflow_basic.json�פ����������ɤ���ComfyUI���ɤ߹��ࡣ
����ե����Ρ�TripleClipLoader�פ���³������LoadCheckpoint�סʥ�ǥ�������ˤ���ľ�ܡ�ClipTextEncode�סʥץ���ץ�������ˤ�Clip�ν��Ϥ�Ҥ��ʤ�����
2024-06-10 ComfyUI�Υ�������Ρ��ɡ�Comfy_LLMVISION�פ˥������������Ź��ޤ�Ƥ����Ȥ����
2024-06-09 Forge���¸�Ū��ݥ��ȥ���ѹ������ȤΥ��ʥ���
https://github.com/lllyasviel/stable-diffusion-web...
�ʰʲ��ϵ�����������Ĵ�ϰ��ѼԤˤ���
====
�ե������桼�����γ�����
���������åץ��ȥ�� sd-webui�γ�ȯ�֥����Ǥϡ��ѥե����ޥ˴ؤ���¿���ο�Ľ����������ޤ����������Υܥȥ�ͥå���¿���ϲ�褵���Ϥ��Ǥ������������������褦�ˡ���¿���Υ桼�����ˤϥ��åץ��ȥ�� webui ���᤹���Ȥ��ᤷ�ޤ� (webui �γ�ȯ�֥�����ľ�ܻ��Ѥ��뤫����ȯ�֥������ᥤ��˥ޡ��������ޤ��Ե����ޤ�)��
Ʊ���ˡ�Forge ��¿���ε�ǽ (unet-patcher ��ǿ��Υ�������ʤ�) �ϡ����ߤ� WebUI �Υ��������ƥ�˼�������ˤϥ����Ȥ������ꤹ����ȹͤ����Ƥ��ޤ���
���θ塢Forge �ϡ�������祳���ȤΤ����뵡ǽ��ƥ��Ȥ��뤿��μ¸�Ū�ʥ�ݥ��ȥ�ˤʤ�ޤ���Gradio 4 �Ǽ¸�����LRU �ץ����� �������塼��� pickle �١����Υץ������̿��˴�Ť� huggingface space �Υ��� GPU ��������Υ������� GPU �С������μ������ΥС������� Forge ���ɲä��ޤ�������ˤ�ꡢForge �ˡ�Forge Space��(Gradio 4 SDK @spaces.GPU ̾�����֤˴�Ť�) �Ȥ������������֤ȡ���LLM�פȤ����̤Υ��֤��ɲä���ޤ���
�����Υ��åץǡ��Ȥˤ�ꡢ�ۤܤ��٤Ƥγ�ĥ��ǽ��������ǽ�������뤿�ᡢ�²�Ư�Ķ��Τ��٤ƤΥ桼�����ˤϡ�������ѤǤϥ��åץ��ȥ��� WebUI ���᤹���Ȥ��ᤷ�ޤ���
gradio �� LLM �����ե������ȥ��ȥ�ߥ� �����ƥࡢ����� ���ǥ������ȥǥ����ץ쥤�ˤ�����Ƕ�ο��⡢����� Gradio SDK �Υ��� GPU �����������ƥ�Υ�����쥹������˴ؤ��ơ����åץ��ȥ��θ�Ƥ��Ŭ���ˤ� Gradio 4 �Υե����ɥХå��ȳ�ĥ��ɬ�פǤ��뤿�ᡢ�����Υ桼�������˻Ĥ��� Gradio 4 ��ƥ��Ȥ���褦���Ԥ��ޤ���
�Ǹ�ˡ�Forge �桼�����˺������ե�����ΥХå����åפ��뤳�Ȥ�侩���ޤ� (�ޤ��ϡ���ǽ�Ǥ���Х��åץ��ȥ��� WebUI ���᤹�����Ǥ�)�����Υ��ʥ��˵��դ����˸��ä� Forge ��������硢���Υ��ʥ������κǸ�Υ��ߥåȤ�29be1da�Ǥ���
====
2024-06-06 �������ͤθ����Hires.fix��Adetailer�Υ����Ϣư�������ĥ��ǽ�����������
https://github.com/Takenoko3333/sd-webui-reuse-see...
��ȯ�Τ������Ĥϰʲ���
�ʤ�JNVA����402/260
�ʤ�JNVA����402/631
³���ơ������ܥ����ʬ�䤷��🎲��♻��+1�ܥ�����ɲä���JavaScript��ǽ��ĥ������ꥯ�����Ȥ��Ф��줿��
�ʤ�JNVA����403/177
�ʤ�JNVA����403/523


��ȯ�Τ������Ĥϰʲ���
�ʤ�JNVA����402/260
260 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 6938-l7CW)[sage] �������2024/06/05(��) 18:28:30.55 ID:4POD0XU60 SD��WebUI�ǥץ���ץȤ�����ʤ���Ŭ���˽��Ϥ��� �ɤ�SEED���Ĥ�������ꤷ��hires.Fix��Adetailer�Υ����å�����Ƥ��䤬 ��������դ�����SEED���ꤷ���������ˤ���Τ����ݤʤ�䤬 �ܥ����ȯ�Ǥ����ˡ�Ȥ��ʤ���
�ʤ�JNVA����402/631
631 ̾���� ������[Lv.30] (�������� 4ac3-M/1B)[sage] �������2024/06/06(��) 15:44:42.87 ID:UNK+HALX0 >>382 �Ǥ����� https://github.com/Takenoko3333/sd-webui-reuse-seed-plus ���ܥ���Ǥ�ꤿ���ä�����Hires.fix�ε�ư��ʣ�����ä����� Ϣư������å��ܥ�����ڤ��ؤ��������ˤ��� �ܤ�����github���������ɤ�Ǥ��� Ϣư���Ȥ߹�碌��¿�����Ϥ뤷���ܥ������ɡ��������Ƥ���ͽ�� �ꥯ�����Ȥ�����Фɤ���
³���ơ������ܥ����ʬ�䤷��🎲��♻��+1�ܥ�����ɲä���JavaScript��ǽ��ĥ������ꥯ�����Ȥ��Ф��줿��
�ʤ�JNVA����403/177
177 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 86a4-6Hk5)[] �������2024/06/07(��) 22:16:52.73 ID:vd08XaSL0 >>146 ���������Ǥ�����ĥ��ǽ�ˤ��Ƥۤ��� https://seesaawiki.jp/nai_ch/d/%b5%a1%c7%bd%a4%c4%a4%ad%a4%ce%c0%b8%c0%ae%a5%dc%a5%bf%a5%f3%a4%f2%c4%c9%b2%c3%a4%b9%a4%eb%ca%fd%cb%a1 �ӥå��������֤���Ƥ���櫓���������ʤ�����
�ʤ�JNVA����403/523
523 ̾���� ������[Lv.32] (�������� 4ac3-M/1B)[sage] �������2024/06/08(��) 22:47:02.79 ID:t6FS3GUu0 sd-webui-reuse-seed-plus �˵�ǽ���ɲä��ޤ�������v0.2.0�� https://github.com/Takenoko3333/sd-webui-reuse-seed-plus txt2img, img2img �β��̤˻��Ĥε�ǽ�դ������ܥ�����ɲä��ޤ��� Hires.fix �Υ���/���դ�Ϣư����¾�ε�ǽ�Υ���/���դ��ڤ��ؤ��ޤ��� https://files.catbox.moe/13c29a.png https://files.catbox.moe/pnm6wi.png �����ܥ���ˤĤ��� �ꥯ�����Ȥ˱����Ʋ���ǾҲ𤵤�Ƥ����֥å��ޡ�����åȤ�������Ƶ�ǽ��ĥ���Ȥ߹��ߤޤ�����
2024-06-05 ��̡�褬ή�Ԥ���
Animagine3.1�˸���ǭLoRA���Ȥ߹�碌������ꤵ�줿�ޥΤ褦�ʲ�������Ϥ���Τ�ή�ԡ�����̡��פȸƤФ줿��
�ʤ�JNVA����402/252
====
252 ̾���� ������[Lv.34] (�������� beee-WQ8n)[] �������2024/06/05(��) 17:54:13.15 ID:xEbGq8Wl0
��ޤ�


��>>115
����ǡ���ǭlora�Υ������Ⱦ夲���ǭ��ꡢ������ȥ������
�ץ���ץ����äƤ뤫��褫�ä��鹥���ʥ����Ǥɤ������
�磻����2����AI�ζ����ͥ���SAN�ͺ���ƥ����ʤ��
�⤦�����Ľ��������������
====
���������ץȤ������ʤɾܤ����������̡���ȤΤ��ȡ�
�ʤ�JNVA����402/252
====
252 ̾���� ������[Lv.34] (�������� beee-WQ8n)[] �������2024/06/05(��) 17:54:13.15 ID:xEbGq8Wl0
��ޤ�
��>>115
����ǡ���ǭlora�Υ������Ⱦ夲���ǭ��ꡢ������ȥ������
�ץ���ץ����äƤ뤫��褫�ä��鹥���ʥ����Ǥɤ������
�磻����2����AI�ζ����ͥ���SAN�ͺ���ƥ����ʤ��
�⤦�����Ľ��������������
====
���������ץȤ������ʤɾܤ����������̡���ȤΤ��ȡ�
2024-06-03 SD3�Υ�����ȯɽ
6/13�ɵ������ܻ��֤�6��12�����10�������˰��̸������줿��
6/13�ɵ����饤��������������¿������SD3�Ǥγؽ�����ʬ������餷����
2024-05-31 Omost�����������
ControlNet��Fooocus��Forge�γ�ȯ���Τ���lllyasviel����÷�AI���Ѥ��Ʋ��������������Omost�פ����������
https://github.com/lllyasviel/Omost
PC�˥��ȡ��뤷�ʤ��Ƥ⡢huggingface��Υǥ�ڡ����ǻ���Ȥ�Ǥ��롣
https://huggingface.co/spaces/lllyasviel/Omost
2024-05-31 ��������ץ���ץȤ��¬����ġ���ʤɤ����������
�ʤ�JNVA����400
https://fate.5ch.net/test/read.cgi/liveuranus/1716...
- ������β�������ץ���ץȤ��¬����ġ��� https://huggingface.co/spaces/John6666/wd-tagger-t...
- ��Τ˲ä��ƥ����ץ���ץȤ���������ġ��� https://huggingface.co/spaces/John6666/danbooru-ta...
- ���̤�Danbooru������ݥˡ��Ѥ�e621�������Ѵ�����ġ��� https://huggingface.co/spaces/John6666/danbooru-to...
������⥤�ȡ����ɬ�פʤ���huggingface�Υ��ڡ���������ѤǤ��롣
��Ŭ���˥ѥ��äƲ�¤�������ʤ��ï�Ǥ����Ŭ���˥ѥ��äƲ�¤�����äƤ䡼�פȤΤ��ȡ�
2024-05-19 3x3x3mixXL�����������
https://civitai.com/models/464044
Pony����Υ�ǥ뤬�夤�Ȥ�����طʤ��������ߤ���������Ƥ���Τ���ħ��
https://fate.5ch.net/test/read.cgi/liveuranus/1716...
Pony����Υ�ǥ뤬�夤�Ȥ�����طʤ��������ߤ���������Ƥ���Τ���ħ��
https://fate.5ch.net/test/read.cgi/liveuranus/1716...
3x3x3mixXL�������Ƥߤ��� typeA~C�����Ƥߤ���䤬��ľ��������Ǥ����ޤäƤ�����ޤ��ˤʤäȤ뤫��ѤäƻȤ��ˤ������⤷���� ���ȥޡ������֤���������������빽�ޤ��ȴ餬����䤹���Τ�ADtailer�ǤĤ��ä��ۤ������������ǡ�
2024-05-12 ebara_pony_2�����������
https://huggingface.co/tsukihara/xl_model
https://fate.5ch.net/test/read.cgi/liveuranus/1715...
�ѹ����ˤĤ��Ƥϡ֤ޤ������Ƹ����ʤ鹽�ޡġ��狼���磻��ʷ�ϵ��ǥޡ������Ȥ�ס�1.5�ΤȤ��ߤ����ˡ֥С�����åס��פä�������ʤ���ñ�˳������㤦�äƴ����פȤ⡣�� https://fate.5ch.net/test/read.cgi/liveuranus/1715... ��
����2.1���������줿����ȩ��ή�Ф������������ΤǼ㴳���ꥸ�ʥ�pony�˶��������ʬ��ǹ�����Ĵ�����Ƥ�����פȤΤ��ȡ�
https://fate.5ch.net/test/read.cgi/liveuranus/1715...
625: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� 6106-txKt) sage 2024/05/12(��) 17:25:40.46 ID:jCfcGQrA0 https://files.catbox.moe/mil0up.jpg�� https://huggingface.co/tsukihara/xl_model �������ޤ�����ǥ��� ����äȥ��ꤹ���뤫�⤷��ɤޤ��������Ǹ������
�ѹ����ˤĤ��Ƥϡ֤ޤ������Ƹ����ʤ鹽�ޡġ��狼���磻��ʷ�ϵ��ǥޡ������Ȥ�ס�1.5�ΤȤ��ߤ����ˡ֥С�����åס��פä�������ʤ���ñ�˳������㤦�äƴ����פȤ⡣�� https://fate.5ch.net/test/read.cgi/liveuranus/1715... ��
����2.1���������줿����ȩ��ή�Ф������������ΤǼ㴳���ꥸ�ʥ�pony�˶��������ʬ��ǹ�����Ĵ�����Ƥ�����פȤΤ��ȡ�
2024-05-08 URL��ޤ���ߤǡ֤⤦;��Ǥ�äƤ����������פȸ����륱������³��
�����Ĺ���ʾ��ʸ�� URL���ȡ֤⤦;��Ǥ�äƤ����������פˤʤꡢ
URL ʸ���ʤ�н����Ȥ�����꼡������
2024-05-08 ic-light�����������
2024-04-27 cnlllite-anystyle��ή�Ԥ���
4/22�˸������줿�������ι��ޤ�ݻ������ޤް����䥭���ʤ�¾�����Ǥ��ѹ��Ǥ���Controlnet��ǥ롢cnlllite-anystyle��ή�Ԥ�����
�ܤ�����ControlNet������������
�ܤ�����ControlNet������������
2024-04-23 Hyper-SD����
https://hyper-sd.github.io/
LCM��SDXL-Lightning�Τ褦����STEP��������λ���뵻�Ѥˡ������ʼ�ˡ�Ȥ���Hyper-SD���������줿
��Ҥδ�¸��ˡ��������ʪ�����٤��ɤ��Ȥ��졢�ºݤ˥����386�Ǥ���Ѥ��줿������Ž���Ƥ���Τǻ��ͤˤ�����ɤ�
https://fate.5ch.net/test/read.cgi/liveuranus/1713...
Ƴ����ˡ�ϡ����������Ȥ�������Ƥ���HuggingFace��LoRA�Ȥ��ƥ���������ɤǤ���
SD1.5�Ѥ�SDXL�Ѥ�����Τǡ����Ӥ˹�碌�ƥ���������ɤ���
���ѻ��ϡ�LCM LoRA��Ʊ���褦�˥ץ���ץ���ǸƤӽФ����ɤ�
������ Hyper-SDXL-8steps-lora.safetensors��
���ƥå�:8������ץ��:Euler a SGM Uniform(Uniform�Ǥ⤤����)��CFG:Animagine�Ϥ�1��2��Pony�Ϥ�3��3.5���餤
������ SDXL�Ѥ�safetensor�����ä�SD1.5�ѤȤ��������˵��ܤ���Ƥ��뤿�ᡢWebUI�ǥե���������SDXL��ǥ���ɤ߹���Ǥ����LoRA�ꥹ�Ȥ�ɽ������ʤ�
�����꤫��Extra Networks(�ɲäΥͥåȥ��)�ڡ����ˤ���Always show all networks on the Lora page(otherwise, those detected as for incompatible version of Stable Diffusion will be hidden)�˥����å���������ɽ�������Τǡ�LoRA�Υ��ѥʥ������������SDXL���ѹ�������ɤ�
LCM��SDXL-Lightning�Τ褦����STEP��������λ���뵻�Ѥˡ������ʼ�ˡ�Ȥ���Hyper-SD���������줿
��Ҥδ�¸��ˡ��������ʪ�����٤��ɤ��Ȥ��졢�ºݤ˥����386�Ǥ���Ѥ��줿������Ž���Ƥ���Τǻ��ͤˤ�����ɤ�
https://fate.5ch.net/test/read.cgi/liveuranus/1713...
Ƴ����ˡ�ϡ����������Ȥ�������Ƥ���HuggingFace��LoRA�Ȥ��ƥ���������ɤǤ���
SD1.5�Ѥ�SDXL�Ѥ�����Τǡ����Ӥ˹�碌�ƥ���������ɤ���
���ѻ��ϡ�LCM LoRA��Ʊ���褦�˥ץ���ץ���ǸƤӽФ����ɤ�
������ Hyper-SDXL-8steps-lora.safetensors��
���ƥå�:8������ץ��:Euler a SGM Uniform(Uniform�Ǥ⤤����)��CFG:Animagine�Ϥ�1��2��Pony�Ϥ�3��3.5���餤
������ SDXL�Ѥ�safetensor�����ä�SD1.5�ѤȤ��������˵��ܤ���Ƥ��뤿�ᡢWebUI�ǥե���������SDXL��ǥ���ɤ߹���Ǥ����LoRA�ꥹ�Ȥ�ɽ������ʤ�
�����꤫��Extra Networks(�ɲäΥͥåȥ��)�ڡ����ˤ���Always show all networks on the Lora page(otherwise, those detected as for incompatible version of Stable Diffusion will be hidden)�˥����å���������ɽ�������Τǡ�LoRA�Υ��ѥʥ������������SDXL���ѹ�������ɤ�
2024/5/1�ɵ� CFG��������5��8���б�������ǥ����
4/30�ˡ�CFG��������5��8���б�������ǥ뤬�������줿���������Ѥ���ȡ�HyperSD���ѻ����Ի��ѻ���CFG���������Ĵ������ɬ�פ�̵���ʤ롣
2024-04-18 Stable Diffusion 3��API�����������
https://ja.stability.ai/blog/stable-diffusion-3-ap...
�������Ǥ�ͭ����
��®�ݶ⤷�ƻ���ͤ⤤�뤬�֤��ޤꥯ����ƥ��θ���ϴ������ʤ��פȤΤ��ȡ�
�������������줿�Τϳ�ȯ�Ӿ�Υ�ǥ�Ȥξ���⤢�ꡢ��������SD3�μ��Ϥ����Τ�ɾ�������ʳ��ˤϤʤ���
�������Ǥ�ͭ����
��®�ݶ⤷�ƻ���ͤ⤤�뤬�֤��ޤꥯ����ƥ��θ���ϴ������ʤ��פȤΤ��ȡ�
�������������줿�Τϳ�ȯ�Ӿ�Υ�ǥ�Ȥξ���⤢�ꡢ��������SD3�μ��Ϥ����Τ�ɾ�������ʳ��ˤϤʤ���
2024-04-16 Adobe Premiere Pro�ؤ�Sora�μ�����ȯɽ
https://news.adobe.com/news/news-details/2024/Adob...
https://gigazine.net/news/20240416-adobe-premiere-...
ư���Խ����եȡ�Adobe Premiere Pro�פˡ���Sora�פ�Ϥ���Ȥ���ʣ����ư������AI��ǥ뤬2024ǯ��Ⱦ���ɤ˼���ͽ��Ǥ��뤳�Ȥ�ȯɽ���줿��
����ޤ��ޤ����̿ͤ����ǽ��ư��AI��Ȥ���褦�ˤʤäƤ������Ȥ����Ԥ���롣
https://gigazine.net/news/20240416-adobe-premiere-...
ư���Խ����եȡ�Adobe Premiere Pro�פˡ���Sora�פ�Ϥ���Ȥ���ʣ����ư������AI��ǥ뤬2024ǯ��Ⱦ���ɤ˼���ͽ��Ǥ��뤳�Ȥ�ȯɽ���줿��
����ޤ��ޤ����̿ͤ����ǽ��ư��AI��Ȥ���褦�ˤʤäƤ������Ȥ����Ԥ���롣
2024-04-12 �ʤ�JNVA����382 �ɤꥷ���ƥ�ͭ���������
���ͤƤ�ꥹ����ץȹӤ餷�˸�����Ƥ���5ch�ǡ������к��Ȥ��Ƴ�ȯ���줿�ɤꥷ���ƥब���ܥ���382�Ƕ���ͭ�������줿��
������������ˤ��̤�б��֥饦��̱������˽���ʤ��ʤ����꤬ȯ�����뤿�ᡢ�����ͭ������³���뤫�ɤ����ϵ�����ɬ�פǤ��롣
�ɤΤ��餤����ʤ��桼���������뤫�İ��Τ���ˤ⡢�����Ԥϥƥ�ץ����������𤷤Ƥۤ�����
������������ˤ��̤�б��֥饦��̱������˽���ʤ��ʤ����꤬ȯ�����뤿�ᡢ�����ͭ������³���뤫�ɤ����ϵ�����ɬ�פǤ��롣
�ɤΤ��餤����ʤ��桼���������뤫�İ��Τ���ˤ⡢�����Ԥϥƥ�ץ����������𤷤Ƥۤ�����
2024-03-23 Stability AI�μ��ץ��С������
https://stability.ai/news/stabilityai-announcement
CEO��Emad Mostaque���Ϥ���Ȥ��뽾���Stability AI�γ�ȯ���С�������ʬ����Ҥ��Ƥ��뤳�Ȥ����餫�ˤʤä���
����ˤ��SD�Υ��ݡ���������SD3�Υ����˱ƶ��������뤫�ɤ����ϸ������Ǥ�������
SD3�������ץ����ǥ�������뤳�Ȥϳ��ꤷ�Ƥ������͡�
CEO��Emad Mostaque���Ϥ���Ȥ��뽾���Stability AI�γ�ȯ���С�������ʬ����Ҥ��Ƥ��뤳�Ȥ����餫�ˤʤä���
SD3�������ץ����ǥ�������뤳�Ȥϳ��ꤷ�Ƥ������͡�
2024-03-18 Animagine XL 3.1������
https://huggingface.co/cagliostrolab/animagine-xl-...
https://cagliostrolab.net/posts/animagine-xl-v31-r...
Linaqurf��餬Animagine XL 3.0�θ�ѤΡ�Animagine XL 3.1�פ����������
3.0�ǽФʤ��ä�¿���Υ��˥ᥭ��餬�Ф���褦�ˤʤä���
Quality tags�λ��ͤ��ѹ����줿���Ȥ����ա�Aesthetic Tags���ɲä��줿��
https://cagliostrolab.net/posts/animagine-xl-v31-r...
Linaqurf��餬Animagine XL 3.0�θ�ѤΡ�Animagine XL 3.1�פ����������
3.0�ǽФʤ��ä�¿���Υ��˥ᥭ��餬�Ф���褦�ˤʤä���
Quality tags�λ��ͤ��ѹ����줿���Ȥ����ա�Aesthetic Tags���ɲä��줿��
- ���͡�animagine31tips
2024-03-14 ������ˡ��ʸ
��Фϰʲ��Υ���
�ʤ�JNVA����361
https://fate.5ch.net/test/read.cgi/liveuranus/1710...
581: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� 12e8-xhpr) sage 2024/03/14(��) 09:20:02.25 ID:QawQpn3/0
RTX 2000 Ada�����䤵���餷�����ɤ��Υ���Ū�ˤϤɤ��ʤ��
�����Ĥ�PCIe4x8�餷������RTX4060 16GB�Τ���äȾ�äƤ���������
582: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� 7e66-UCxz) sage 2024/03/14(��) 09:26:02.88 ID:Uav7afoj0
���581
����������Ϥ�70W�����饬����AI�ʳ��Ǥ����Ӥ���˾Ū�������餯�ѥե����ޥ������櫓�Ǥ�ʤ�
24����������³���뤱���ŵ��夬���ˤʤ�äƿͤ���ʤ������̵�����ʤ���
584: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� 12e8-xhpr) sage 2024/03/14(��) 09:29:29.97 ID:QawQpn3/0
���582
���Ĥ�
�Ĥ����Ȥϳؽ����äȲ����ͤȤ������ܻ����ܤ�¤��Ѥ߽Ťͤ����ͤऱ���������
587: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� 2e3e-gl2Z) sage 2024/03/14(��) 09:40:29.78 ID:MzzNXCG/0
���584
ttps://i.imgur.com/O14NCsP.jpeg
ü�ҹ���������ʴ����ʤ����ꡢ3~4���ʣ����˥����Ķ����ۤ����������Ȥ�����������ʳ��ΰ��̥桼�����ˤϤ��������Ȥ��ˤ�������ܤǤ����ʤ��Ȼפ�
591: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� 12e8-xhpr) sage 2024/03/14(��) 10:11:45.54 ID:QawQpn3/0
���587
��ʤ��ȤϤ狼�äƤ������ˡ��
Kohaku�˥��ʤ�3090��4�ѤߤȤ���äƤ뤫�顢�ؽ��˥ޥ��GPU�äư�̣����ʤȻפä�
�����ξ����̡��Υ����ˤʤäƤ��ޤ����餢�ޤ��̣�ʤ��ΤϤ狼�äƤ�䤱��
592: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� a2bb-On+R) sage 2024/03/14(��) 10:12:33.69 ID:jyi7Ntuv0
���591
�����������ä��Τ���
594: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� 7ef3-OcrC) sage 2024/03/14(��) 10:14:22.42 ID:FJxL1hfC0
������ˡ��ʬ¦�˻Ȥ��ͽ��Ƹ�����
������ˡ�Ȥ�
����β�������äƤ����ʤ��鼫ʬ�λ�����ȾΤ������ۤ��Ѥ˥���̱��ʢ�ڤ�����������ϰ������֡���Ȥʤä���
�ߡ���Ȥ������ΤϳΤ����������ͥ����Τ�ʤ��Ȥ�����������ʤ����Ǥ��롣��ˡ���̤ˤ����դ��褦
2024-03-13 Animagine�Ǥ������ߥ����餷����ư��Ƚ��
Animagine�Ǥ⡢Pony��Ʊ�ͤ˥�����ʱѿ���3ʸ��������뤳�Ȥǥ������뤬�Ѳ����뤳�Ȥ�Ƚ��������
���⤽��XL��ɸ���ǥ������äƤ�����ͤ˱ƶ����������ư�ʤΤǤϤʤ����Ȥ�����¬��ʤ��줿��
���⤽��XL��ɸ���ǥ������äƤ�����ͤ˱ƶ����������ư�ʤΤǤϤʤ����Ȥ�����¬��ʤ��줿��
2024-03-12 �ܥ���˷㤷��������ץ�����
�ܥ���(�Ȥ������ʤ�U)������������Ω�Ƥ륹����ץȤ�ȯ������ǽ�����˴٤äƤ��롣
�ʲ������������褦��
�ᥤ�������: https://bbs.3chan.cc/test/read.cgi/liveuranus/1695...
���������: http://bbs.jpnkn.com/test/read.cgi/JNVA/1696574746...
�ʲ������������褦��
�ᥤ�������: https://bbs.3chan.cc/test/read.cgi/liveuranus/1695...
���������: http://bbs.jpnkn.com/test/read.cgi/JNVA/1696574746...
2024-03-12 Pony�������ޤ줿�����θ��椬�����
PonyDiffusionV6XL�ˤϡ����饹�ȥ졼�����ʤɤΥ������ѿ���3ʸ���ǤҤ����������ޤ�Ƥ��뤳�Ȥ�Ƚ�����ʤ�JNVA����356 https://fate.5ch.net/test/read.cgi/liveuranus/1710... �����פ��餳�����꤬����������줬��®���������콪�פˤϥ�����ץȹӤ餷���轱���������ˡ�
2024-03-01 sd-forge-layerdiffusion�����������
LayerDiffusion��ControlNet��ȯ�������С���ȯɽ������Τǡ�����������ǥ뤬Ʃ������������Ǥ���褦�ˤ�����Τ餷����
����LayerDiffusion���Ȥ���Ķ���forge�����˸������줿��sd-forge-layerdiffusion��
����̱���Ȥä����ۤȤ��Ƥϰʲ����褯�ޤȤޤäƤ���Τǰ��Ѥ��롣
����̱���Ȥä����ۤȤ��Ƥϰʲ����褯�ޤȤޤäƤ���Τǰ��Ѥ��롣
0027 ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� de28-9+AH) 2024/03/02(��) 18:57:42.58ID:g50+9iiw0 �ޤ���Ƥ��ʤ��۸����� ��Layer Diffusion�ϸ����������ޤ仨������Ǻ������ �����ʤȤ��طʤ�������������Τϸ����ۤɲ���Ϲ⤯�ʤ� ���ɤ������Τ��礦�Τ��Ȥ��ͤ���ñ��˻����餷���� ��������������λ���Ȥ��Ǥ��ʤ��ΤǸ������ä���Τ� �������˱������������������� ��i2i�Ϥ���1���֤��餤�����餷���礭���Ķ����Ѳ�����ޤǻ��֤Ϥޤ��ݤ��ꤽ������������˴��Ԥ�������
2024-02-23 sd-danbooru-tags-upsampler������
https://github.com/p1atdev/sd-danbooru-tags-upsamp...
LECO�κ�ԤǤ���p1atdev����Ϥ��줿�ץ���ץȤ�³��danbooru������LLM����������Extension�����������
AI�����������˥ץ���ץȤ��������Ƥ����Τǡ��ץ���ץȤ��פ��Ĥ��ʤ����䥬��������Ȥ���������
LECO�κ�ԤǤ���p1atdev����Ϥ��줿�ץ���ץȤ�³��danbooru������LLM����������Extension�����������
AI�����������˥ץ���ץȤ��������Ƥ����Τǡ��ץ���ץȤ��פ��Ĥ��ʤ����䥬��������Ȥ���������
2024-02-22 Stable Diffusion 3ȯɽ
https://stability.ai/news/stable-diffusion-3
���ܸ�ε���: https://ja.stability.ai/blog/stable-diffusion-3
Stability AI�ˤ�ꡢStable Diffusion�μ������ǥ��Stable Diffusion 3�פ�ȯɽ���줿��
����Υ�ǥ����ץ���ץȤ��ɲ��Ϥ�ɽ���Ϥ������˸��夷���ƥ����Ȥ����Τ˽��ϤǤ���ȤΤ��ȡ�
OpenAI�Ρ�Sora�פ�Ʊ�ͤο����ʳȻ��ȥ�ե����ޡ����Ѥ����Ѥ���Ƥ���Ȥ�����
�������Ǥϰ��̸�������Ƥ��餺������θ���ͽ�����ڥå��ʤɤ�������
Stable Cascade�Ȥϲ����ä��Τ�
���ܸ�ε���: https://ja.stability.ai/blog/stable-diffusion-3
Stability AI�ˤ�ꡢStable Diffusion�μ������ǥ��Stable Diffusion 3�פ�ȯɽ���줿��
����Υ�ǥ����ץ���ץȤ��ɲ��Ϥ�ɽ���Ϥ������˸��夷���ƥ����Ȥ����Τ˽��ϤǤ���ȤΤ��ȡ�
OpenAI�Ρ�Sora�פ�Ʊ�ͤο����ʳȻ��ȥ�ե����ޡ����Ѥ����Ѥ���Ƥ���Ȥ�����
�������Ǥϰ��̸�������Ƥ��餺������θ���ͽ�����ڥå��ʤɤ�������
2024-02-22 NovelAI�˥Х��֥��ȥ�ե�����ǽ�����������
https://twitter.com/novelaiofficial/status/1760394...
���������Ǥ�����̤γ�����Ϥ��뵡ǽ�����٤ι⤵�˥��줬����夬�롣
2024-02-20 ComfyUI��Stable Cascade���б�
https://comfyanonymous.github.io/ComfyUI_examples/...
ComfyUI��Stable Cascade���б��������Ȥ�ȯɽ���줿��
Cascade�Υ�ǥ��Checkpoint�ե����������������ư���ȤΤ��ȡ�
�ܥ���Ǥ�VRAM8GB�Ǥ�ư������Ȥ���𤵤�Ƥ��롣
ComfyUI��Stable Cascade���б��������Ȥ�ȯɽ���줿��
Cascade�Υ�ǥ��Checkpoint�ե����������������ư���ȤΤ��ȡ�
�ܥ���Ǥ�VRAM8GB�Ǥ�ư������Ȥ���𤵤�Ƥ��롣
2024-02-17 pixiv�Ǥ�AI����BAN����꼡��
pixiv��R18��AI������夲���Ȥ���BAN���줿���Ȥ��ܥ�����꼡������𤵤�롣
���ѵ���Ƕػߤ���Ƥ���¼̥ݥ�Ρ�¾�Ԥε�����¾�����Ȥʤɤ�ͶƳ�˰��ä����äƤ���ȿ�¬����Ƥ��뤬�ܺ٤�������
�����pixiv��AI������夲��Τ��������ɤ���������
���������դ�BAN����¿�����뤿�ᡢ����pixiv���Ĥˤ��������ΤȤ����Ϥ狼��ʤ���
���ѵ���Ƕػߤ���Ƥ���¼̥ݥ�Ρ�¾�Ԥε�����¾�����Ȥʤɤ�ͶƳ�˰��ä����äƤ���ȿ�¬����Ƥ��뤬�ܺ٤�������
���������դ�BAN����¿�����뤿�ᡢ����pixiv���Ĥˤ��������ΤȤ����Ϥ狼��ʤ���
2024-02-16 ư������AI��Sora��ȯɽ
https://openai.com/sora
OpenAI�ˤ��ư������AI��Sora�פ�ȯɽ���줿��
�ץ���ץȤ����Ĺ1ʬ�֤ι������ư���������ǽ�Ǥ��ꡢʣ���ʥץ���ץȤˤ��б����롣
����Ū��ʪ�����ߥ�졼����Ԥ��Ƥ���ȤΤ��Ȥǡ����������AI��������Ū����ǽ�����夷���ꥢ��ʱ���������Ȥʤä���
�ʤ��������ǤϤ����ޤǤ��ȯɽ�Ǥ����ǥ�ΰ��̸����ϹԤ��ʤ���
OpenAI�ˤ��ư������AI��Sora�פ�ȯɽ���줿��
�ץ���ץȤ����Ĺ1ʬ�֤ι������ư���������ǽ�Ǥ��ꡢʣ���ʥץ���ץȤˤ��б����롣
����Ū��ʪ�����ߥ�졼����Ԥ��Ƥ���ȤΤ��Ȥǡ����������AI��������Ū����ǽ�����夷���ꥢ��ʱ���������Ȥʤä���
�ʤ��������ǤϤ����ޤǤ��ȯɽ�Ǥ����ǥ�ΰ��̸����ϹԤ��ʤ���
2024-02-13 Stable Cascade����
https://ja.stability.ai/blog/stable-cascade
https://github.com/Stability-AI/StableCascade
Stability AI�ˤ�ꡢ�����ʲ���������ǥ��Stable Cascade�פ��������줿��
SDXL����û���֤Ǥ���������ǽ�Ǥ��ꡢ����˥ץ���ץȤ�����٤����������Ū�ʼ�����夷�Ƥ���Ȥ�����
���������ư�����ˤϥǥե���Ȥ�20GB��VRAM��ɬ�פȤ��뤬�������ɤ���Ѥ��뤳�ȤǤ�꾯�ʤ�VRAM��ư����Ȥ����⤢�롣
https://note.com/hakomikan/n/n75f0ee78abf9
https://github.com/Stability-AI/StableCascade
Stability AI�ˤ�ꡢ�����ʲ���������ǥ��Stable Cascade�פ��������줿��
SDXL����û���֤Ǥ���������ǽ�Ǥ��ꡢ����˥ץ���ץȤ�����٤����������Ū�ʼ�����夷�Ƥ���Ȥ�����
���������ư�����ˤϥǥե���Ȥ�20GB��VRAM��ɬ�פȤ��뤬�������ɤ���Ѥ��뤳�ȤǤ�꾯�ʤ�VRAM��ư����Ȥ����⤢�롣
https://note.com/hakomikan/n/n75f0ee78abf9
2024-02-12 ZLUDA������
Radeon��CUDA��ư������褦�ˤ����åѡ����եȥ�����ZLUDA��GitHub����ǡ�������줿��
https://github.com/vosen/ZLUDA/
������AMD�dz�ȯ���Ƥ��������줬ή�Ԥ�ȱס�CUDA�Ǥ������ȤʤäƤ��ޤ�����ץ��������Ȥ��פˤʤ��Ԥ���������˻�ä���AMD��2023ǯ10���nod.ai SHARK��������Ƥ���ˡ�
��ǽ�Ȥ��Ƥ�Geekbench��OpenCL�Ǥ�ư��������ۤȤ����ǽ���夬��ʺ���75.34�åס��ʤɡ�����ñ�˥��եȸߴ�������������ǤϤʤ����ѥե����ޥ��åȤޤǤ������Ƚ��������
2024ǯ6��1�����ߡ�Stable Diffusion WebUI AMDGPU�ʵ�Stable Diffusion WebUI DirectML����--use-zluda���ץ����䡢ComfyUI��ZLUDA�ե���������Ȥ�����Radeon�Ǥ�Stable Diffusion�Ϥ��®�˰������������褦�ˤʤäƤ��롣
https://github.com/vosen/ZLUDA/
������AMD�dz�ȯ���Ƥ��������줬ή�Ԥ�ȱס�CUDA�Ǥ������ȤʤäƤ��ޤ�����ץ��������Ȥ��פˤʤ��Ԥ���������˻�ä���AMD��2023ǯ10���nod.ai SHARK��������Ƥ���ˡ�
��ǽ�Ȥ��Ƥ�Geekbench��OpenCL�Ǥ�ư��������ۤȤ����ǽ���夬��ʺ���75.34�åס��ʤɡ�����ñ�˥��եȸߴ�������������ǤϤʤ����ѥե����ޥ��åȤޤǤ������Ƚ��������
2024ǯ6��1�����ߡ�Stable Diffusion WebUI AMDGPU�ʵ�Stable Diffusion WebUI DirectML����--use-zluda���ץ����䡢ComfyUI��ZLUDA�ե���������Ȥ�����Radeon�Ǥ�Stable Diffusion�Ϥ��®�˰������������褦�ˤʤäƤ��롣
2024-02-06 stable-diffusion-webui-forge����
ControlNet�κ��lllyasviel�ˤ�롢WebUI�Υ�ե���������Ǥ��������줿
https://github.com/lllyasviel/stable-diffusion-web...
��VRAM�Ķ��Ǥι�®������ѥ���︺����������ΤΡ�����Extension���ޤ�ư���ʤ��餷���ΤǾ嵭Github������
Github���
NVA����Τߤʤ��ޤδ�Ӥ���
https://github.com/lllyasviel/stable-diffusion-web...
��VRAM�Ķ��Ǥι�®������ѥ���︺����������ΤΡ�����Extension���ޤ�ư���ʤ��餷���ΤǾ嵭Github������
Github���
���ꥸ�ʥ��WebUI��1024px�Ǥ�SDXL�����ˤ���Ӥ���ȡ��ʲ��Τ褦�ʥ��ԡ��ɥ��åפ����ԤǤ��ޤ���
- 8GB vram�Τ褦�ʰ���Ū��GPU����Ѥ����硢����®�١�it/s�ˤ���30��45%���夷��GPU����ԡ����ʥ������ޥ͡�����ˤ���700MB����1.3GB�˸�����������Ȼ������١�OOM��VRAM����Out Of Memory���ʤ��ˤ���2�ܤ���3�ܤ����ä�������Ȼ��Хå���������OOM���ʤ��ˤ���4�ܤ���6�ܤ����ä��ޤ���
- 6GB vram�Τ褦�ʶ��ϤǤʤ�GPU����Ѥ����硢����®��(it/s)����60��75%���夷��GPU����ԡ���(�������ޥ͡�����)����800MB����1.5GB�˸�����������Ȼ�������(OOM���ʤ�)����3�ܡ�����Ȼ��Хå�������(OOM���ʤ�)����4�ܤ����ä��ޤ���
- 24GB��vram�����4090�Τ褦�ʶ��Ϥ�GPU����Ѥ����硢����®�١�it/s�ˤ���3��6%��®������GPU����ԡ����ʥ������ޥ͡�����ˤ���1GB����1.4GB���㲼��������Ȼ������١�OOM���ʤ��ˤ���1.6�ܤˤʤꡢ����Ȼ��Хå���������OOM���ʤ��ˤ���2�ܤˤʤ�ޤ���
- SDXL��ControlNet����Ѥ����硢ControlNet�κ��祫����ȿ���OOM���ʤ��ˤ���2�ܤˤʤꡢSDXL+ControlNet��®�٤���30��45%®���ʤ�ޤ���
NVA����Τߤʤ��ޤδ�Ӥ���
�ʤ�JNVA����328 https://fate.5ch.net/test/read.cgi/liveuranus/1707027741/994 994: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� b73c-jSnV) sage 2024/02/06(��) 13:01:10.84 ID:73PRlTFt0 A1111�����Ϻǿ���ʤ�1.6.0�䤬Forge����Ӥ����� �Ķ���5900X, RTS4070tis (PL70%) ��ͤ�1024x1024 step30��2�ܤ�hires������̤� A1111��https://litter.catbox.moe/xmggsd.png Forge��https://litter.catbox.moe/sozkxc.png ���ѥ����̤�4GB�ʾ�︺����Ȥ���®�٤�30�ðʾ��������Ȥ� hires��®���Ƥ���Ϥ������� ư�����ĥ������餷���Τ��ͥå��䤬����ľŬ���˥ݥ�Ф�����ʤ�ComfyUI��ꤳ�ä������������� https://litter.catbox.moe/nt6n0p.jpg �ʤ�JNVA����329 116: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� d7d4-KLri) sage 2024/02/06(��) 15:08:10.66 ID:+EIplyW30 4080 VRAM16GB��forge��� SDXL 1024*1536�����2��hires��2048x3072�Ԥ��ƴ�ư����. ����hires�ʤ����Ȥ����ޤ��δ��Ѥ��ʤ��Τȡ�hires����Ǥ�12GB���餤����VRAM�ȤäƤʤ��ΤǤ��������Τʤ�����. ���֤�12GB���Ǥ�2�ܹԤ��� lora-block-weight�ϥ��顼�Фʤ����ɸ����Ƥʤ��ߤ������� 132: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� 9f2c-by7P) sage 2024/02/06(��) 15:29:23.02 ID:4ViKf5KT0 3060ti8G�Ǥ�832*1216��hires*2��2ʬ�Ǥ������ ��̿�Ǥ���
2024-01-19 Pony Diffusion V6 XL������ˤʤ�
https://civitai.com/models/257749/pony-diffusion-v...
���줬Animagine XL 3.0������ǻ�������ˤʤ��桢��������Civitai�˥��åץ����ɤ���Ƥ�����ǥ롣
���ʤ����äʥ�����ƥ�������negative prompt�λ��Ѥ�ɬ�פǡ���꤯���塼�˥��ʤ��ȥХ�����������������뤬��
�ϥޤä����μ��ι⤵�˥��������夬�ä����ä�NSFW��ͥ����
lora�γؽ���ǥ�Ȥ��Ƥ�ͥ���ǡ�Animagine�����ü����ʤؤ�������(����)
������ƥ�������negative prompt�ϥ���Ƕ�ͭ���줿�����ʲ��˵�������civitai�Υ���ץ�������ơ�õ�äƤۤ�����
�������ɤ���Τ�����Х���Ƕ�ͭ���Ƥۤ�����
������ƥ���������
negative prompt����(ɱ���Υ˥�)
���ȡ�PonyDiffusionV6XLTips
���줬Animagine XL 3.0������ǻ�������ˤʤ��桢��������Civitai�˥��åץ����ɤ���Ƥ�����ǥ롣
���ʤ����äʥ�����ƥ�������negative prompt�λ��Ѥ�ɬ�פǡ���꤯���塼�˥��ʤ��ȥХ�����������������뤬��
�ϥޤä����μ��ι⤵�˥��������夬�ä����ä�NSFW��ͥ����
lora�γؽ���ǥ�Ȥ��Ƥ�ͥ���ǡ�Animagine�����ü����ʤؤ�������(����)
������ƥ�������negative prompt�ϥ���Ƕ�ͭ���줿�����ʲ��˵�������civitai�Υ���ץ�������ơ�õ�äƤۤ�����
�������ɤ���Τ�����Х���Ƕ�ͭ���Ƥۤ�����
������ƥ���������
0229����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� a7b0-OBZN) 2024/01/26(��) 11:50:33.13ID:HD6WR8TC0 pony�������Ƭ�ˤ��줤��Ȥ��Ф���������������� score_9, score_8_up, score_7_up, BREAK source_anime, rating_explicit, best quality, masterpiece, uncensored, 1girl,
negative prompt����(ɱ���Υ˥�)
0077����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 5f14-zQB7) 2024/01/25(��) 22:47:04.32ID:qJvUoh9O0 >>75 ����������Ѥ��ۤ�ȴ���Ȣ���� Pony���طʼ夤��depth of field�Ȥ��Υͥ���ȴ�����طʥܥ䤫�����ۤ�����������ʤ��Ȥ������⤷�Ƥ���� censored, mosaic censoring, bar censor ,border, worst quality, low quality, simple background, white background, realistic, sketch ,muscle , normal quality, jpeg artifacts, depth of field, blurry, messy drawing, amateur drawing, lowres, bad anatomy, bad hands, text, error, missing fingers, fewer digits, extra digits,cropped , greyscale, monochrome, source_furry, source_pony, source_cartoon, comic ,source filmmaker,video ,3d
���ȡ�PonyDiffusionV6XLTips
2024-01-11 Animagine XL 3.0������
https://huggingface.co/cagliostrolab/animagine-xl-...
https://cagliostrolab.net/posts/animagine-xl-v3-re...
Linaqurf��餬SDXL�١����Υ��˥��ǥ��Animagine XL 3.0�פ����������
NovelAI V3��������ǽ��ؤꡢQuality Tags�ʤɤ⤢��NAI3�˶ᤤ���Фǻ��ѤǤ��뤫�⡣
����Ǥ�sd-scripts�θ��ۤ�Ʊ������ʤ��Զ��dzؽ������ޤ��Ǥ��Ƥʤ���ǽ��������������ι��ʤ�ʲ��˴��ԤǤ��롣
���ȡ�AnimagineXL3.0tips
https://cagliostrolab.net/posts/animagine-xl-v3-re...
Linaqurf��餬SDXL�١����Υ��˥��ǥ��Animagine XL 3.0�פ����������
NovelAI V3��������ǽ��ؤꡢQuality Tags�ʤɤ⤢��NAI3�˶ᤤ���Фǻ��ѤǤ��뤫�⡣
����Ǥ�sd-scripts�θ��ۤ�Ʊ������ʤ��Զ��dzؽ������ޤ��Ǥ��Ƥʤ���ǽ��������������ι��ʤ�ʲ��˴��ԤǤ��롣
���ȡ�AnimagineXL3.0tips
2023ǯ
2023-12-12 ���������ˤ��2023��������AI�ޤȤ�
�������� �����ΤΡ֥�С������ץ쥼�� ��46�� ��������AI����®�ǿʲ�����2023ǯ��ޤȤ�ƿ����֤�
������������AI����ӥ���ӥ������ޥ��Ȥɤ��ʤ롩��14��2023ǯ��Ⱦ���ޤȤ�+����13��ʬ���֤� (�����µ�)
����Ȥϴط��ʤ�����2023ǯ�β�������AI�˴ؤ��������ѥ��ȤˤޤȤ���Ƥ���Τǡ����礬�ɤ�Τˤ��礦���ɤ���
������������AI����ӥ���ӥ������ޥ��Ȥɤ��ʤ롩��14��2023ǯ��Ⱦ���ޤȤ�+����13��ʬ���֤� (�����µ�)
����Ȥϴط��ʤ�����2023ǯ�β�������AI�˴ؤ��������ѥ��ȤˤޤȤ���Ƥ���Τǡ����礬�ɤ�Τˤ��礦���ɤ���
2023-12-10 PNG�ǽ��Ϥ��������Υ�ǡ�����ݻ������ޤ�JPEG���Ѵ�����ġ��뤬GitHub�˸��������
- �ʤ�JNVA����299 https://fate.5ch.net/test/read.cgi/liveuranus/1702...
- https://github.com/Takenoko3333?tab=repositories
- png2jpg-for-a1111-and-NAI�ʥ�ǡ�����ݻ�����PNG��JPEG���Ѵ� ��̾��:png2jpg����
- jpg2png-for-NAI��JPEG�Ѵ�����NAI������PNG���Ѵ���
- jpg2jpg-bugfix-metadata�ʥХ��б� �Ѵ��Ѥ�JPEG�����ѡ�
2023-12-05 ��ʪ������ư�������Ѥ�³���о�
��ʪ���Ż߲��ư�������Ȥ��ò�������ǥ뤬³�����о줷�Ƥ��롣
Animate Anyone�ϥ���ХХ��롼�פˤ�äƳ�ȯ���줿��ǥ�Ǥ���(Animate Anyone�γ���)��
�Ż߲����Ȥ�������ư����openpose�η�����Ϳ���뤳�Ȥǡ��Ż߲����μ̤ä���ʪ��ư�������Ȥ��Ǥ��롣
����Ĥ����ʤ���ư�����Τΰ������褯�ݤ���Ƥ��뤿������ˤʤäƤ��롣��
2023/12/05���ߡ������������ɤʤɤϸ�������Ƥ��ʤ������������뤳�Ȥ��������Ƥ���GitHub�Υ����Ȥ��Ѱդ���Ƥ���(AnimateAnyone��GitHub��)
MagicAnimate��Animate Anyone��Ʊ�ͤΥ�ǥ�ǡ�����Ĥ��Τʤ�������Τ���ư�������Ǥ����ǥ�Ǥ���(MagicAnimate�γ���)��
Animate Anyone�Ȥϰ㤤����ʪ��ư����openpose�ǤϤʤ�densepose�Ȥ��������ǻ��ꤹ�롣
Hugging Face�ǻ���Ȥ��Ǥ�������Ǥʤ������Ǥ˥����������ɤʤɤ���������Ƥ��뤿���������Ķ��ǻ��(MagicAnimate�ǥ⥵������MagicAnimate��GitHub)��
������ϻ����Τ�Twitter�ʤɤ�ή��Ƥ��뤬
�������ϲ����Ȥ���㤦��ˤʤäƤ��
����(densepose���ͤ��سԤ���¸���뤿�ᤫ)�������Τ������λҤˤʤäƤ��ޤä���
�ʤɰ����ǤϹԤ��ʤ��褦�ǤϤ��롣
Animate Anyone�ϥ���ХХ��롼�פˤ�äƳ�ȯ���줿��ǥ�Ǥ���(Animate Anyone�γ���)��
�Ż߲����Ȥ�������ư����openpose�η�����Ϳ���뤳�Ȥǡ��Ż߲����μ̤ä���ʪ��ư�������Ȥ��Ǥ��롣
����Ĥ����ʤ���ư�����Τΰ������褯�ݤ���Ƥ��뤿������ˤʤäƤ��롣��
2023/12/05���ߡ������������ɤʤɤϸ�������Ƥ��ʤ������������뤳�Ȥ��������Ƥ���GitHub�Υ����Ȥ��Ѱդ���Ƥ���(AnimateAnyone��GitHub��)
MagicAnimate��Animate Anyone��Ʊ�ͤΥ�ǥ�ǡ�����Ĥ��Τʤ�������Τ���ư�������Ǥ����ǥ�Ǥ���(MagicAnimate�γ���)��
Animate Anyone�Ȥϰ㤤����ʪ��ư����openpose�ǤϤʤ�densepose�Ȥ��������ǻ��ꤹ�롣
Hugging Face�ǻ���Ȥ��Ǥ�������Ǥʤ������Ǥ˥����������ɤʤɤ���������Ƥ��뤿���������Ķ��ǻ��(MagicAnimate�ǥ⥵������MagicAnimate��GitHub)��
������ϻ����Τ�Twitter�ʤɤ�ή��Ƥ��뤬
�������ϲ����Ȥ���㤦��ˤʤäƤ��
����(densepose���ͤ��سԤ���¸���뤿�ᤫ)�������Τ������λҤˤʤäƤ��ޤä���
�ʤɰ����ǤϹԤ��ʤ��褦�ǤϤ��롣
2023-11-29 SDXL Turbo����
����������
��ǥ�
�Ƕ�����ȤʤäƤ���LCM�ˤ���®���Ȥ��̤ε���(�ʲ�����)���Ѥ���SDXL�ι�®��ǥ뤬Stability AI�������ȯɽ���줿��
Turbo SDXL-LoRA-Stable Diffusion XL faster than light(Civitai)
����ˤ�ꡢ�����Υ�ǥ��1STEP��LoraŬ�Ѥ�4STEP��SDXL��ǥ�ˤ�������������ǽ�Ȥʤä���
��ǥ�
�Ƕ�����ȤʤäƤ���LCM�ˤ���®���Ȥ��̤ε���(�ʲ�����)���Ѥ���SDXL�ι�®��ǥ뤬Stability AI�������ȯɽ���줿��
Ũ��Ū�Ȼ���α��Adversarial Diffusion Distillation��ADD�ˤȸƤФ�뿷������α���Ѥ˴�Ť��Ƥ��ޤ������ε��Ѥˤ�ꡢSDXL Turbo ��1�ĤΥ��ƥåפDz������Ϥ���������⤤����ץ������٤�ݻ����ʤ���ꥢ�륿����ǥƥ����Ȥ�������ؤν��Ϥ��������뤳�Ȥ��Ǥ��ޤ��ޤ���ȯɽ��������ָ�ˤ�Lora���������졢LCM��Ʊ���褦�˴�¸�Υ�ǥ���Ф��ƹ�®����Ŭ�ѤǤ���褦�ˤʤä�
Turbo SDXL-LoRA-Stable Diffusion XL faster than light(Civitai)
����ˤ�ꡢ�����Υ�ǥ��1STEP��LoraŬ�Ѥ�4STEP��SDXL��ǥ�ˤ�������������ǽ�Ȥʤä���
2023-11-28 WebUI��Generate�������˥ܥ���˵�ǽ�Ĥ��������ܥ�����ɲä�����ˡ����Ƥ����
Generate�ܥ���β���🎲�ʥ����ॷ���ɤ������ˡ�♻��ľ���Υ����ɤ������ˡ�+1������Υ����ɤ�+1���������ɤ������ˤγƥܥ�����ɲä����Ρ�
�ܺ٤ϡ���ǽ�Ĥ��������ܥ�����ɲä�����ˡ�פȡ�
�ܺ٤ϡ���ǽ�Ĥ��������ܥ�����ɲä�����ˡ�פȡ�
2023-11-20 LCM LoRA�β�������Ҳ𤵤��
LCM LoRA�Ϥ�꾯�ʤ����ƥå��Dz������«�����뵻�ѤΤ��ȡ�
���������̤��Ť��ʤ뷹���������ΤΡ����ޤǤ�1/3�ۤɤΥ��ƥå�����3�ܤ�®�٤Dz����������Ǥ��롣
�ʤ�JNVA����288 https://fate.5ch.net/test/read.cgi/liveuranus/1700...
���������̤��Ť��ʤ뷹���������ΤΡ����ޤǤ�1/3�ۤɤΥ��ƥå�����3�ܤ�®�٤Dz����������Ǥ��롣
�ʤ�JNVA����288 https://fate.5ch.net/test/read.cgi/liveuranus/1700...
797 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� a5a4-jMfl)[] �������2023/11/20(��) 14:26:31.02 ID:ve33UeCg0 �������µפ������������Stable Diffusion��®���η������о졪���ʼ���Ȥ������¤�ۤܤʤ���2��3��®�� - PC Watch https://pc.watch.impress.co.jp/docs/column/nishikawa/1547611.html LCM LoRA��1�������˻���Ȥ��ϡ��ᤤ�����ʼ��ϥ��ޥ����פȴ��������ɺ��Ͻ����ˡ��½���ʤ��ʤä��ߤ���?https://pc.watch.impress.co.jp/docs/column/nishika...
2023-11-16 NovelAI�������3������
NovelAI�β������������ӥ��ΥС������3�����̤˸������줿��
SDXL�١����Υ�ǥ�ˡ������餯���ĤƤ�Ʊ���褦��Danbooru�����١����dzؽ����줿�褦�ǡ�Danbooru�����Ǥλ���ȼ���ʸ�Ǥλ��꤬���ѤǤ��롣
¾�β������������ӥ��Ȱ㤤�����ʤ구���ϥ��Х��Фǥ����Ǥⲿ�Ǥ�Ф��Ƥ���롢���ĤƤ�NovelAI��̾���˰��ʤ����Ϥ���ǽ(�������ô��ȥڥɤϤ�������NG������)
SDXL�١����Υ�ǥ�ˡ������餯���ĤƤ�Ʊ���褦��Danbooru�����١����dzؽ����줿�褦�ǡ�Danbooru�����Ǥλ���ȼ���ʸ�Ǥλ��꤬���ѤǤ��롣
¾�β������������ӥ��Ȱ㤤�����ʤ구���ϥ��Х��Фǥ����Ǥⲿ�Ǥ�Ф��Ƥ���롢���ĤƤ�NovelAI��̾���˰��ʤ����Ϥ���ǽ(�������ô��ȥڥɤϤ�������NG������)
2023-11-01 nVIDIA�Υ���ե��å��ɥ饤�Ф��ᥤ��������Ѥ��ʤ���������
nVIDIA������ե������ѥɥ饤��Ver536.40�ʹߡ�VRAM��Ȥ��ڤä��ݤ˥ᥤ��������Ѥ���OUT OF MEMORY���顼���Фʤ����ͤˤʤäƤ�����
���������Ѥ�VRAM��Ȥ��ڤ�Ȳ�������®�٤��������㲼�������꤬ȯ�����Ƥ�����
���ϻ���2023-10-31�˥������줿Ver546.01�ˡ����ε�ǽ�Υ���/���դ��ڤ��ؤ������꤬�ɲä��줿���ᡢĹ�餯��ä���Ƥ��ʤ��ä��������꤬�Ĥ��˲�褷��
546.01�����ˤϽ���ʥ������ƥ��ۡ����¸�ߤ���𤵤�Ƥ��뤿�ᡢ����®������ˤ��Ƥ���ޤǥ��åץǡ��Ȥ��Ƥ��ʤ��ä��ͤ������ؤ���侩���롣
������ˡ�ϰʲ��Υڡ�������
https://nvidia.custhelp.com/app/answers/detail/a_i...
���������Ѥ�VRAM��Ȥ��ڤ�Ȳ�������®�٤��������㲼�������꤬ȯ�����Ƥ�����
���ϻ���2023-10-31�˥������줿Ver546.01�ˡ����ε�ǽ�Υ���/���դ��ڤ��ؤ������꤬�ɲä��줿���ᡢĹ�餯��ä���Ƥ��ʤ��ä��������꤬�Ĥ��˲�褷��
546.01�����ˤϽ���ʥ������ƥ��ۡ����¸�ߤ���𤵤�Ƥ��뤿�ᡢ����®������ˤ��Ƥ���ޤǥ��åץǡ��Ȥ��Ƥ��ʤ��ä��ͤ������ؤ���侩���롣
������ˡ�ϰʲ��Υڡ�������
https://nvidia.custhelp.com/app/answers/detail/a_i...
2023-10-29 ɱ���Υץ���ץȤ���ɽ�����
�ʤ�JNVA����279 https://fate.5ch.net/test/read.cgi/liveuranus/1698...
��ɱ���Τ����ϥե�Ǻ�Ǥ�
������ޤ�����Υ��ڡ�����Ĵ���������ڥ������aminal��animal�ˤ������
126: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� 1314-CP9B) 2023/10/29(��) 20:17:13.22 ID:to5BfwrK0 ��걢�����ʤ��Ҥ����ͥ���������� ������>>977 �磻��ɱ���Τ����ˤ�LoRA��̵���ǡĥץ���ץȤǴ�ñ�˽Ф뤪��ڻҤ� ������Τ���˿���LoRA�褻�뤫��LoRA�Ȥ��Ǥ�Ф���Ȥ�����LoRA�Ȥ�ʤ��Τ��磻�α��� �ݥ���young girl ,tiara , white hair ,twintails , 13 years old,big blue eyes ,gold accent cape, embroidery breastplate ,thighhighs �ͥ���elf,aminal ear,forehead ,pubic hair, asymmetrical thighhighs,heterochromia ���줬�Ƕ�Υ١���ɱ���Τ����Ǥ��ä����ǥ��LoRA�˹�碌��tiara��white hair�ζ�Ĵ�ٹ礤Ĵ���������夻�ؤ������ꤹ������ˤ��ɱ���Τ����ư�ϰ�(����Ӹ���η�)�������ˤҤ�����
��ɱ���Τ����ϥե�Ǻ�Ǥ�
������ޤ�����Υ��ڡ�����Ĵ���������ڥ������aminal��animal�ˤ������
- young girl, tiara, white hair, twintails, 13 years old, big blue eyes, gold accent cape, embroidery breastplate, thighhighs
- elf, animal ear, forehead, pubic hair, asymmetrical thighhighs, heterochromia
2023-10-21 NovelAI������ǥ�NovelAI Diffusion Anime V2��ȯɽ
NovelAI�Ҥ������˳ؽ�����������������������ǥ�NovelAI Diffusion Anime V2��ȯɽ����(Introducing NovelAI Diffusion Anime V2)
V3�Ⳬȯ��Ǥ��뤳�Ȥ�Ʊ����ȯɽ���졢³���Ԥ���롣
��ǥ빽¤��Stable Diffusion���Ȥˤ��Ƥ���Ȥ�����Ƥ��ʤ����ᡢ�ɤΥ�ǥ빽¤����Ѥ��Ƥ���Τ��������Ǥ��롣
�ץ���ץȤ��������褯�����Ȥ�����������Ϥ����夷�Ƥ���ʤɤȸ����Ƥ�����˼����⤯�ʤäƤ���褦�Ǥ��롣
(���͡��ʤ�JNVA����277)
���θ���ˤȤɤޤ餺����ǽ�̤Ǥ��Ѳ��⤢�롣����Ȥ��Ƥ���masterpiece���������ꡢ�ʳ�Ū�ʥ�����ƥ�����(quality tag)�����إ���(aesthetics tag)�Ȥ�����Τ����Ѥ��줿��
������ƥ����������إ����ΰ㤤�Ϥ狼��ˤ�������ȯɽ������¤�Ǥϥ�����ƥ�����������Ⲥ��ɤ�ʤɥߥ���Ū�������礭���ƶ���Ϳ���Ƥ��ꡢ���إ����Ϥɤ��餫�Ȥ����й��ޤ��سԤʤɤΥޥ���Ū�����˱ƶ���Ϳ���Ƥ���褦�Ǥ��롣
�㤤�ʤ�ƹͤ���"masterpiece"�������"very aesthetic, best quality"������Ƥ����Ф���������Ȥ����������ˤϤʤ뤬���سԤ乽�ޤΤޤޤ˺�����Ĵ�����ǤǤ���Τ�ͭ�Ѥ��⤷��ʤ���
DALLE-3���Ȥ߹��ޤ줿Bing Image Creator�Ȥ�GPT-4V�Υ˥塼������٤�ȥ���ѥ��Ȥ������ä��������֤��Ƥ����Τ�����NovelAI 5ch Wiki�Ȥ��������ȥ�ʤΤ�Novel AI�Υ��åץǡ��Ȥ���Ƥ��ʤ��Τ�����ʤΤǤϡ��Ȼפ����Ƥ��ɵ������Τ���̩�Ǥ��롣
V3�Ⳬȯ��Ǥ��뤳�Ȥ�Ʊ����ȯɽ���졢³���Ԥ���롣
��ǥ빽¤��Stable Diffusion���Ȥˤ��Ƥ���Ȥ�����Ƥ��ʤ����ᡢ�ɤΥ�ǥ빽¤����Ѥ��Ƥ���Τ��������Ǥ��롣
�ץ���ץȤ��������褯�����Ȥ�����������Ϥ����夷�Ƥ���ʤɤȸ����Ƥ�����˼����⤯�ʤäƤ���褦�Ǥ��롣
(���͡��ʤ�JNVA����277)
���θ���ˤȤɤޤ餺����ǽ�̤Ǥ��Ѳ��⤢�롣����Ȥ��Ƥ���masterpiece���������ꡢ�ʳ�Ū�ʥ�����ƥ�����(quality tag)�����إ���(aesthetics tag)�Ȥ�����Τ����Ѥ��줿��
������ƥ����������إ����ΰ㤤�Ϥ狼��ˤ�������ȯɽ������¤�Ǥϥ�����ƥ�����������Ⲥ��ɤ�ʤɥߥ���Ū�������礭���ƶ���Ϳ���Ƥ��ꡢ���إ����Ϥɤ��餫�Ȥ����й��ޤ��سԤʤɤΥޥ���Ū�����˱ƶ���Ϳ���Ƥ���褦�Ǥ��롣
�㤤�ʤ�ƹͤ���"masterpiece"�������"very aesthetic, best quality"������Ƥ����Ф���������Ȥ����������ˤϤʤ뤬���سԤ乽�ޤΤޤޤ˺�����Ĵ�����ǤǤ���Τ�ͭ�Ѥ��⤷��ʤ���
DALLE-3���Ȥ߹��ޤ줿Bing Image Creator�Ȥ�GPT-4V�Υ˥塼������٤�ȥ���ѥ��Ȥ������ä��������֤��Ƥ����Τ�����NovelAI 5ch Wiki�Ȥ��������ȥ�ʤΤ�Novel AI�Υ��åץǡ��Ȥ���Ƥ��ʤ��Τ�����ʤΤǤϡ��Ȼפ����Ƥ��ɵ������Τ���̩�Ǥ��롣
2023-10-01 DALLE-3��Bing Image Creator���ʲ�
Bing Image Creator�ϥ����������������������������⤢�ޤ�ѥäȤ��ʤ��ä��������ܤ���Ƥ��ʤ��ä���
9��22���������������åץǡ��Ȥ����ä�����(Bing Image Creator�Υ��åץǡ��Ȥ˴ؤ��뵭��)��
9��30���������饹��̱�����Ť��Ф������͡�100��ʬ��̵����30�����٤�û���������֤��餪��ڤ˻���Ȥ��Ǥ���10��1�����ߤ����äǻ�������Ǥ��롣
�礭���Ѥ�ä��Τϥץ���ץȤι⤤�ɲ�ǽ�ϤǤ��롣
�֥��˥����β����ǡ��ƥ�ӤΥ�⥳������륵��ȡ�����Ĥ�븤��

�ץ���ץȤ������äƤ��ޤ����Ȥ����ʤ��褦�˴�����ۤ����¼����β�������˥��饹�����β������ޤ����ळ�Ȥ��ǽ�ʤ褦�Ǥ���
(��Ϣ����reddit�ε���: Dall-e 3 natively supports a mix of anime and realistic style)��
�֥��˥��¼����μ㤤������

����䤹������ʸ�����ޤ����ळ�Ȥ��ǽ�Ǥ���(������������ܸ��̵������)��
�֤��ӥ����ǡ���Big Brother Watching You�פȽ줿���Ĥ�Ǥ��������

�������Ȥ��Ƥ�
1. ���������������뤳��(���襤�����˥����ν��λҤϹ��Ψ�ǡ֥ץ���ץȤ��֥��å�����ޤ����פ�ɽ������롣����������Բ�)
2. ��ǥ뤬��������Ƥ���櫓�ǤϤʤ����ᡢ�������Ǹ�������Ф������뤳�Ȥϸ����Բ�ǽ(�ݥ��������������̾�ʥ����ϽФƤ���)
3. ControlNetŪ�ʤ�ΤϤʤ�
�ʤɤǤ��롣i2i�θ������Ȥ��Ƥʤ�Ȥ��뤫�⤷��ʤ��ʤɻȤ�ƻ���Ϻ�����Ƥ��롣
9��22���������������åץǡ��Ȥ����ä�����(Bing Image Creator�Υ��åץǡ��Ȥ˴ؤ��뵭��)��
9��30���������饹��̱�����Ť��Ф������͡�100��ʬ��̵����30�����٤�û���������֤��餪��ڤ˻���Ȥ��Ǥ���10��1�����ߤ����äǻ�������Ǥ��롣
�礭���Ѥ�ä��Τϥץ���ץȤι⤤�ɲ�ǽ�ϤǤ��롣
�֥��˥����β����ǡ��ƥ�ӤΥ�⥳������륵��ȡ�����Ĥ�븤��

�ץ���ץȤ������äƤ��ޤ����Ȥ����ʤ��褦�˴�����ۤ����¼����β�������˥��饹�����β������ޤ����ळ�Ȥ��ǽ�ʤ褦�Ǥ���
(��Ϣ����reddit�ε���: Dall-e 3 natively supports a mix of anime and realistic style)��
�֥��˥��¼����μ㤤������

����䤹������ʸ�����ޤ����ळ�Ȥ��ǽ�Ǥ���(������������ܸ��̵������)��
�֤��ӥ����ǡ���Big Brother Watching You�פȽ줿���Ĥ�Ǥ��������

�������Ȥ��Ƥ�
1. ���������������뤳��(���襤�����˥����ν��λҤϹ��Ψ�ǡ֥ץ���ץȤ��֥��å�����ޤ����פ�ɽ������롣����������Բ�)
2. ��ǥ뤬��������Ƥ���櫓�ǤϤʤ����ᡢ�������Ǹ�������Ф������뤳�Ȥϸ����Բ�ǽ(�ݥ��������������̾�ʥ����ϽФƤ���)
3. ControlNetŪ�ʤ�ΤϤʤ�
�ʤɤǤ��롣i2i�θ������Ȥ��Ƥʤ�Ȥ��뤫�⤷��ʤ��ʤɻȤ�ƻ���Ϻ�����Ƥ��롣
2023-09-18 �ִ�ñ�ץ���ץȥ��˥�פ����������
��266
https://fate.5ch.net/test/read.cgi/liveuranus/1694...
https://fate.5ch.net/test/read.cgi/liveuranus/1694...
229 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 8fb2-xbk3)[] �������2023/09/18(��) 16:40:42.77 ID:u/gM0xJC0 Ϣ�ٻȤä�ï�Ǥ�ץ���ץȤ�����ư������Ǥ���褦�ˤ����� https://twitter.com/Zuntan03/status/1703674198101803268 ��¤�ʤ���Զ�礢�ä��鶵���Ƥ� WebUI�ϻȤäƤʤ���Ǻ��ΤȤ��������ȿ�ǤϤʤ��Ϥ��� ������ư���Google Drive����¸�������ʤ�����output_to_google_drive��Disable�ˤ��Ƥ�https://twitter.com/Zuntan03/status/17036741981018...
����
- https://yyy.wpx.jp/m/202309/nadenadesitai_v10.mp4
- https://yyy.wpx.jp/m/202309/xxmix9realistic_v40.mp...
- https://yyy.wpx.jp/m/202309/onigiriMix_v10.mp4
- https://yyy.wpx.jp/m/202309/mistoonAnime_v20.mp4
230 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 8fb2-xbk3)[] �������2023/09/18(��) 16:51:44.23 ID:u/gM0xJC0 >>229 Colab�Υ��˺��Ȥä� https://colab.research.google.com/drive/1QVxBjAamxOIAAlSohQklZltRPx8WsxEN
https://colab.research.google.com/drive/1QVxBjAamx...
�Τ��˥��������Ǥ�������줿��
https://github.com/Zuntan03/EasyPromptAnime
2023-09-12 Animatediff����
��264��>>960����ѡ�
AnimateDiff���ΤϾ������˽ФƤ�������9����ܤ˥���������AnimateDiff�Ф���ˤʤä���
���̥ڡ���̵���Τ�ï���Ƥ����¾���ܴ��
7��19��Web UI��AnimateDiff���Ȥ���褦�ˤʤ� 8��24��TDS_�CN�Ǥλ��������������� 8��26��TDS_�AnimateDiff�β������ˡ����� 8��26����29����259 AnimateDiff���������Ȥ��뤫���Ϥ��������ۤ� 8��29����9��2����260 30��������˽Ф��ñȯ�ǽ���� 9��2����5����261 2����4��������˽Ф��ñȯ�ǽ���� 9��5����8����262 AnimateDiff������0�� 9��8����12����263 9���������Ф��ͤ��ФƤ���10���˲Ф��Ĥ�gif��100��Ž���� 9��11��ASCII��AnimateDiff����夲�� 9��12����13����264 200��ʾ�gif��Ž��쥹���AnimateDiff�쿧
2023-09-08 ����륲�����Υ������åȤ���ġ���
https://fate.5ch.net/test/read.cgi/liveuranus/1693...
����륲�����Υ������åȤ��륨�ǥ���������������Τ��ɤ��ä���ȤäƤ�������
https://huggingface.co/spaces/SenY/GalGameUI


2023-08-10 SDXL���ѥե���ȥ���ɡ�Fooocus����
https://github.com/lllyasviel/Fooocus
����ץ�ʥץ���ץȤȲ����Υ����������������ǹ��ʼ��ʲ�������������뤳�Ȥ��ܻؤ��Ƥ��롣
����ץ�ʥץ���ץȤȲ����Υ����������������ǹ��ʼ��ʲ�������������뤳�Ȥ��ܻؤ��Ƥ��롣
2023-08-06 ������ץ��������
�����ʣ���μ¶��Ĥ�̵���̤˹Ӥ餵��Ƥ��롣������Ω�����̥����С��ˤ��DAT������������Ω�Ƥǵ�ǽ�����ˤʤäƤ��롣
����U�������档
����U�������档
2023-07-28 SDXL 1.0������
stability.ai�������������SDXL 1.0���������줿(SDXL 1.0��������)
masterpiece�ʤɤΥ������դ����ꤷ�ʤ��Ƥ⥷��ץ�ʥץ���ץȤǤޤȤ�ʲ������Ǥ�褦�ˤʤä���
���ʳ��Ǥ�ControlNet���Ȥ��ʤ��������������ˤ��г�ȯ�ϹԤäƤ���餷������ۤɥ�������ȤΤ��ȡ�
civitai�Ǥ�SDXL 1.0�Υ���ƥ�����������Ƥ��뤽���ǡ������ǻȤ�������ɤ���ǥ뤬����뤳�Ȥ����Ԥ����
masterpiece�ʤɤΥ������դ����ꤷ�ʤ��Ƥ⥷��ץ�ʥץ���ץȤǤޤȤ�ʲ������Ǥ�褦�ˤʤä���
���ʳ��Ǥ�ControlNet���Ȥ��ʤ��������������ˤ��г�ȯ�ϹԤäƤ���餷������ۤɥ�������ȤΤ��ȡ�
civitai�Ǥ�SDXL 1.0�Υ���ƥ�����������Ƥ��뤽���ǡ������ǻȤ�������ɤ���ǥ뤬����뤳�Ȥ����Ԥ����
2023-07-19 Waifu Diffusion XL(WDXL)������/SDXL 1.0���������
Stable Diffusion XL(SDXL) 0.9��ե�������塼�˥���Waifu Diffusion XL(WDXL)���������줿
1111webui�Ϥޤ�dev�֥����ǤϤ��뤬��1.5.0����SDXL���б����Ƥ������Ȥ��Ǥ���
����̱�δ��ۤȤ��ƤϤޤ�SD1.5�ϤΤۤ����ɤ�����괹����ۤɤǤϤʤ��Ȥ����ո���¿����ΤΡ������ư���˴��Ԥ���Lora�ʤɤ���Ϥ�Ƥ���˥����¬����Ƥ���
7����ܥ�����ͽ�ꤷ�Ƥ���SDXL 1.0�ϥ�����1���֤ۤɱ��������褦����������������뤷�Ƥ�������
1111webui�Ϥޤ�dev�֥����ǤϤ��뤬��1.5.0����SDXL���б����Ƥ������Ȥ��Ǥ���
����̱�δ��ۤȤ��ƤϤޤ�SD1.5�ϤΤۤ����ɤ�����괹����ۤɤǤϤʤ��Ȥ����ո���¿����ΤΡ������ư���˴��Ԥ���Lora�ʤɤ���Ϥ�Ƥ���˥����¬����Ƥ���
7����ܥ�����ͽ�ꤷ�Ƥ���SDXL 1.0�ϥ�����1���֤ۤɱ��������褦����������������뤷�Ƥ�������
2023-07-14 ���५��ˡ�����
2023-06-30�˾Ҳ𤵤줿�ƥ��˥å��β������ȯɽ���줿��
>>495-496 ���ġ� https://note.com/mitsukinozomi/n/n1c5913239ed8 ����ɤ��ޤDz��⤷���館�����狼��ʤ��ʤäơ��Ҥ�ü������⤷�Ƥ���Ĺ���ʤä���ġĤ������https://note.com/mitsukinozomi/n/n1c5913239ed8
2023-07-12 ���ߤ��ܥ���ξ���
�Ƽ���֥��5ch����������ߤ��������ˡ���Τ��Ϥä�����talk�������3�������¸���ʤ������ޤ�talk���Ĥؤ��Կ�������ޤäƤ�
2023/07/12���ߤ�5ch�Υ���˽�̱����äƤ��Ƥ��ꡢ5ch¦���ܥ���ȤʤäƤ��롣
talk¦�Υ�����ؤɽ��ߤ���������ʤ����֡�
2023/07/12���ߤ�5ch�Υ���˽�̱����äƤ��Ƥ��ꡢ5ch¦���ܥ���ȤʤäƤ��롣
talk¦�Υ�����ؤɽ��ߤ���������ʤ����֡�
2023-07-12 5ch�˴ؤ��른������Ҥ�����
�٤�Ф��ʤ��饸�������(JaneStyle�γ�ȯ����API�����Ĥʤ�5ch�ΰ�����̳����)����������ȯɽ���줿��
http://janesoft.net/news/20230712.html
3�Ԥ�Ż����
- ��������˴ؤ���5ch.net�ȤΥӥ��ͥ��������
- 2ch��5ch�ξ�ɸ��������Ƚ������(5ch¦�����ʤ��ƾ����)
- 5ch���Ĥ�8kun�����ӥ�(Q���Υ�ط�)�����褦�Ȥ��Ƥ���
�����������������ʤ���talk�˥桼�������ܹԤ���������API̵��������֥������ԲĤˤ������ʤɤ��Ф��������ϰ��ڽ�Ƥ��ʤ���
5ch���Ĥ������ȥ�������Ҥ��������ɤ�����Ѥ��뤫�ϳƼ���Ƚ�Ǥ��٤���
2023-07-11 Janestyle�˴ؤ���5ch���Ĥ�����
������Janestyle�γ�ȯ��������5ch�ݡ��Ƚ�λ��talk�Ȥ����Ǽ��Ĥ˶����ܹ�+API̵��������֥餫�餹�٤ƤΥ��줬�����ʤ����˴ؤ���5ch������������Ф�����
Ʊ���������ˤ����̤ꡢJanestyle�ʳ�����֥�ʲ���APIƳ���ǻ����ԲĤȤʤä���Τ�ޤ�ˡ�Chrome�ʤɤ�Web�֥饦����5ch�˥�����������ǽ�Ȥʤä���
��Janestyle������ñۤ������١���֥�Ρ������ؤ������ɽ��ߤǤ��ʤ��٤ʤɤ������Ĥγ���֥饹��ء�
���եȥ�������
https://egg.5ch.net/software/
2023-07-11 ������ɤ߽��뤵�ޤ��ޤ���ˡ����Ƥ����
2023-07-10 ��֥�ǥ�����ʤ��ʤ�
Janestyle�γ�ȯ��������5ch�ݡ��Ƚ�λ��talk�Ȥ����Ǽ��Ĥ˶����ܹ�+API̵��������֥餫�餹�٤ƤΥ��줬�����ʤ���
��������ޤäƤ��餺��ɡ�����λ��֤ˤʤäƤ��롣
2023-07-03 superhappy peacesign�ץ���ץȤ�ή�Ԥ���
���λҤ�¿�Ϳ��ǥԡ������Ƥ�������ι�ʸ��superhappy��ʸ�Ȥ⡣
�ʤ�JNVA����230 https://fate.5ch.net/test/read.cgi/liveuranus/1688...
394: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� eb3c-hRAP) sage 2023/07/03(��) 19:29:22.82 ID:oIjgfyxV0 >>348 �����줫���ˤޤ��ʤ�URLŽ�äȤ뤱�ɤ⤦����Ž��� �Ĥˤ���ȥץ���ץ�������������˾���˱��Ԥ���äƤ����� https://majinai.art/i/hasL8oW ���Ȥ����餻��Ȥ���������ط������ޤ�륷���奨����������Τ⥢���� ʣ���ͤ˸�����ǥ�ȸ������ǥ뤬���뤫��¾�Υ�ǥ�ȤäƤߤ�Τ���� https://majinai.art/ja/i/7RRw33Q

- 6+ girls, school uniform, friends, super happy smiling, open mouth, closed eyes, in classroom, group shot, zoom camera, peace sign
598: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� 7b46-92Bd) sage 2023/07/06(��) 13:15:50.60 ID:cJGTUEcs0 >>590 ������ʬ���뤷�ؤ��ɤ��ʤ뤫�Ȥ���ʬ���뤷���ʤ٥���ޡ����Ȥ���ͥ���ʲ������ �ʤˤ���������
2023-06-30 ���५��ˡ���Ҳ𤵤��
�ʤ�JNVA��228��768���־��̤ߤ������̤�bukkake��ɤ�ʹ��ޤǤ���ꤷ�ƽФ����Ȥ������������ǡפȤ��ƥ��५��ˡ��ȯɽ�����५��ˡ��̾�Τϥ���ץ�����Υץ���ץȤˡ�cum cum everybody�פ��ޤޤ�Ƥ������Ȥˤ��
ControlNet��2���Ѱդ��ơ�1���ܤ�lineart_anime, weight0.3���餤, Start0.1, Ending0.7���餤�����ꤷ�Ƥ��Υƥ����������� https://files.catbox.moe/87gvo4.png 2���ܤ�tile�ˤ���Weight1.0, Start0.0, Ending0.1���餤�����ꤷ�Ƥ��ä��Υƥ�����������ʢ��Υƥ�������Ǥ⤤���ˤ�OK�� https://files.catbox.moe/teinah.png �ץ���ץȤ�cum��ռ������ơ�lineart�Ȥ������դ��سԤ�ͶƳ���ơ�tile�Ȥ������դο���������ǡ�3�Ť˻��ꤹ��Τ��������ݥ���Ȥ� weight��strength��Ϯ���img2img��inpaint�Ǥ�Ȥ��뤫����Ѥ��ƤߤƤ䡣�ƥ��������Ѥ���з�ޤߤ�Ȥ�����뤫�⤷��ؤ�


�ʤ�JNVA��229��367�ˡ������ͻҤ����褹������㤬��Ƥ����
367 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 4f7b-hRAP)[sage] �������2023/07/01(��) 21:26:58.46 ID:1FW38K3Q0 >>200 >>297 ����Ȥ����ɤ����籫�����५��Ǥ�äƤߤ��ǡ���̯��ŷ������������̤���֤ˤ�����ɤ��ä��ġ� https://i.imgur.com/GFQ6TWd.png https://i.imgur.com/jxaFOcA.png https://i.imgur.com/x55yelj.png https://i.imgur.com/UstVEGM.png https://i.imgur.com/QYZ7zv3.png png info https://files.catbox.moe/5zjz45.png �ƥ�������ϥե���Ǻ��ĺ�פ��Ƥ��ˤ�äȶʤ��ƿ�̣����礤���礤�� https://files.catbox.moe/bp1hx3.png ����ϡ�lineart_anime, Weight0.3, 0.1-0.6�ס�tile, Weight0.5, 0.0-0.1�פ�ǡ�>>258�˥��θ����Ȥ���DDIM��UniPC�ǤϻȤ��ʤ��������դ�


2023-06-29 �ؽ���ǥ뤫�鳵ǰ��õ����ˡ��LECO�ˤ�ȯɽ�����
�ץ���ץȤ�cowboy shot�ʿ�ʪ���Ⱦ�Ȥ�������⤯�餤�ޤ�����ˤ����줿�Ȥ����ͥ��ƥ��֥ץ���ץȤˡ�cowboy�פ�����ʤ��Ƥ��ʪ�˥����ܡ������Ǥ�����ʤ��褦�ˤ���ʤɤ���ǽ�ˤʤ�
�ʤ�JNVA��229��294����������
294 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 0628-+Mc8)[sage] �������2023/07/01(��) 19:15:29.04 ID:JALQpqNB0 cowboy shot����LOCO��cowboy���Ǿä��Ƥߤ��� 1girl, solo, cowboy shot https://i.imgur.com/p7jKr2C.png NP��(cowboy:1.5) https://i.imgur.com/heGYOJS.png cowboy LOCO���ѡ�NP����ʤ� https://i.imgur.com/Y3TdxNz.png



2023-06-27 NVA���ʹߤǥ�����ץȰʳ�����������������3��ʾ����ٿ��ӤƤ������������
�����Ƕ�ϤȤ�����ɮ����褦�ʽ�������ʤ��ä��桢�����Τ��ä�����������ޤȤ�Ƥ���Ƥ����ΤǷǺ�
0173����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� a50d-VcrX)2023/06/26(��) 17:51:14.29ID:Zhv4g73c0
NVA���ʹߤǥ�����ץȰʳ�����������������3��ʾ����ٿ��ӤƤ�������β�����������å����ơ���ʥϥ��饤�Ȥ�Ĵ�٤Ƥߤޤ���
95, 96��FANBOX����ػ�
99�ļ��������衢niji���㡼�ˡ�
123��automatic1111github���
178��zuntan�����ؽ��ե졼������250MB�����겼��1024�ؽ�����
188��4070ȯ�䡢basil���Ѷػ����
190��Colab��WUI�ػߡ���ĥ��lora�ˤ��뤫lyco�ˤ��뤫
195��flatLoRA��🤖��AI���դϡ������٤ǤϤʤ���
198�ĥ������LoRA���ХХ��Υե������
206�ĥͥ��ͥ���ɾ�ޥ��ԥХ�LoRA
209�Ĥ䤿�����٤Υǥ����鿴�Լ���˥�
�������Ǥ������������������餷�����������夬�äƤ��ޤ��͡�
0173����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� a50d-VcrX)2023/06/26(��) 17:51:14.29ID:Zhv4g73c0
NVA���ʹߤǥ�����ץȰʳ�����������������3��ʾ����ٿ��ӤƤ�������β�����������å����ơ���ʥϥ��饤�Ȥ�Ĵ�٤Ƥߤޤ���
95, 96��FANBOX����ػ�
99�ļ��������衢niji���㡼�ˡ�
123��automatic1111github���
178��zuntan�����ؽ��ե졼������250MB�����겼��1024�ؽ�����
188��4070ȯ�䡢basil���Ѷػ����
190��Colab��WUI�ػߡ���ĥ��lora�ˤ��뤫lyco�ˤ��뤫
195��flatLoRA��🤖��AI���դϡ������٤ǤϤʤ���
198�ĥ������LoRA���ХХ��Υե������
206�ĥͥ��ͥ���ɾ�ޥ��ԥХ�LoRA
209�Ĥ䤿�����٤Υǥ����鿴�Լ���˥�
�������Ǥ������������������餷�����������夬�äƤ��ޤ��͡�
2023-06-18 ���������LoRA���͵����
�ʤ�JNVA����223#969
969 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 9214-Qzqc)[sage] �������2023/06/18(��) 17:57:33.16 ID:Dvbj1tvg0 �������������� https://i.imgur.com/zGGB6a7.png ���������Х���������LoRA�äƸ�����������̵���ʤȻפäƺ�äƤߤ����

�ʤ�JNVA����224#46
46 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 9214-Qzqc)[sage] �������2023/06/18(��) 19:12:42.73 ID:Dvbj1tvg0 SFW���������LoRA�����ۤ����� https://mega.nz/folder/XN8U0AgI#1jr90d0jlPTCjNssbfHfPQ holding_balloon���֤��Ƥ���� https://i.imgur.com/AJABFZa.png https://i.imgur.com/gSK79Ak.png https://i.imgur.com/6UHmBxH.png https://i.imgur.com/Xok79Iq.png NSFW�����Ф��ʤ���SFW�����Ƕ�����Ǥ⤨������ ��������AI�ϼ�ͳ�ʤ��https://mega.nz/folder/XN8U0AgI#1jr90d0jlPTCjNssbf...




2023-04-30 �ե�åȥ��顼LoRA��ͥ���Ŭ�Ѥ���Ƚ��ߤ�������
�ʤ�JNVA��194��911�����顼��ե�åȲ�����LoRA�������
����ˤ���LoRA��֥ޥ��ʥ����̾�Υץ���ץȤ�Ŭ�Ѥ�������٤ʳ��ˤʤ�פ��Ȥ�ȯɽ��
�����嵭LoRAʸ��ͥ��ƥ��֥ץ���ץȤ�����Ƥ�ư���ޤ���
����ˤ���LoRA��֥ޥ��ʥ����̾�Υץ���ץȤ�Ŭ�Ѥ�������٤ʳ��ˤʤ�פ��Ȥ�ȯɽ��
��) <lora:flat:-1>�ۤ��β���LoRA��ޥ��ʥ��ͤ��������͡��ʸ��̤������뤫��ȥ���̱��Ĵ���档
�����嵭LoRAʸ��ͥ��ƥ��֥ץ���ץȤ�����Ƥ�ư���ޤ���
2023-04-21 Google Colab ��̵���ץ���Automatic1111�����Ѥ��ػߤˤʤ�
���ѵ���β���ˤ�ꡢ̵���ץ��Ǥ�remote UI �ΥΡ��ȥ֥å��λ��Ѥ��ػߤ��줿
(����2023/04/21 09:00���ߡ��Ѹ�ڡ����Τߤ����ܸ�faq�ϵ�ɽ���Τޤ�)
����ˤ��Automatic1111���ػߤȤʤꡢ���ѼԤ�ϩƬ���¤����ˤʤä�
����ͭ���ץ������ѼԤˤ�webuis�����Ѥ����¤���ͽ��Ϥ���ޤ���Colab���ѼԤ��ĥ����Ȥ��Ƥ���
�⤷���Τޤ����Ѥ�³�������ϥ�������Ȥ�BAN��ͭ������١�̵���ץ������ѼԤ����դ�ɬ��
Google��������Ȥ�BAN�ˤʤ�١�Gmail��Google�ɥ饤�֡�Youtube�Ȥ��ä�¾�����ӥ��ޤDZƶ��������
���ˤ�¾�����ӥ��ǥ��֥�������Ȥ�BAN������Ʊ���ˡ��ܥ�������Ȥޤ�Ϣ��BAN���줿�������⤢��
paperspace��¾�����ӥ��˰ܤ�ˤ���Google��³�������̵���Ȥϸ�������ͭ���Ǥ˰ܹ����ϥ�������δĶ����ۤ��侩�����

(����2023/04/21 09:00���ߡ��Ѹ�ڡ����Τߤ����ܸ�faq�ϵ�ɽ���Τޤ�)
����ˤ��Automatic1111���ػߤȤʤꡢ���ѼԤ�ϩƬ���¤����ˤʤä�
����ͭ���ץ������ѼԤˤ�webuis�����Ѥ����¤���ͽ��Ϥ���ޤ���Colab���ѼԤ��ĥ����Ȥ��Ƥ���
�⤷���Τޤ����Ѥ�³�������ϥ�������Ȥ�BAN��ͭ������١�̵���ץ������ѼԤ����դ�ɬ��
Google��������Ȥ�BAN�ˤʤ�١�Gmail��Google�ɥ饤�֡�Youtube�Ȥ��ä�¾�����ӥ��ޤDZƶ��������
���ˤ�¾�����ӥ��ǥ��֥�������Ȥ�BAN������Ʊ���ˡ��ܥ�������Ȥޤ�Ϣ��BAN���줿�������⤢��
paperspace��¾�����ӥ��˰ܤ�ˤ���Google��³�������̵���Ȥϸ�������ͭ���Ǥ˰ܹ����ϥ�������δĶ����ۤ��侩�����
2023-04-20 imgur����Ƥ�������ˡ�nsfw���ػߤˤʤ�
�ܹԤ�5��15�����顣
Imgur Terms of Service Update [April 19, 2023]
https://help.imgur.com/hc/en-us/articles/144155876...
�����wiki��imgur�����ϥХå����åפ��Ȥ������ɡ�
wiki�Υ���ڤ��ľ����ʤ�seesaawiki�������ƥ��åפ��ʤ���ɬ�פ����ä����ѡ�
2023/04/26 �ɵ�
"�ꥢ��ϥ�ǥ���ӡ�����"�ʳ��Υڡ�����imgur������wiki�˺ƥ��åפ�����
imgur�β������wiki�β�������б�ɽ( data/new_link.json )�ȡ���Ȥ˻Ȥä�������ץȤ����θ��Ȥ��ƶ�ͭ���롥
������ץȤ�����б�ɽ
2023/05/01 �ɵ�
wiki�˲����Ȥ���ɽ������Ƥ���imgur�����Ϥ��Ǥ˺�����줿�������Ƥ��٤��֤����������ǽ�Ū�ʿ������б�ɽ��ͭ���롥
�ǽ�Ū���б�ɽ
2023-04-17 basilmix�ξ������Ѥ��ػߤ����
basilmix�����ۼԤǤ����̤�������ˤ�äưʲ��Τ褦�ʥĥ����Ȥ���Ƥ��줿��
�̤����������̥ޡ�����ǽ�˳�����ʪ�Ǥ⤢�ꡢ���ߤΥȥ��ɤ��ä���ʪ�Ȥ��äƤ�褤�Ǥ�������
����ޤ��ˤ��ߤʤ����Ѥ����̤�������Ƥ������basilmix�������Ѷػߤϡ�������Ԥ⤤������ǡ����ʤ��餺ȿ������ä���
��ͳ�ϼ��chillout mix�����ۼԤǤ����������������դ���äƤ��뤳�Ȥ���ä����ᡣ
���θ塢���basilmix�Υޡ����쥷�Ԥ����������
https://archive.md/lTfHl
�̤����������̥ޡ�����ǽ�˳�����ʪ�Ǥ⤢�ꡢ���ߤΥȥ��ɤ��ä���ʪ�Ȥ��äƤ�褤�Ǥ�������
����ޤ��ˤ��ߤʤ����Ѥ����̤�������Ƥ������basilmix�������Ѷػߤϡ�������Ԥ⤤������ǡ����ʤ��餺ȿ������ä���
��ͳ�ϼ��chillout mix�����ۼԤǤ����������������դ���äƤ��뤳�Ȥ���ä����ᡣ
���θ塢���basilmix�Υޡ����쥷�Ԥ����������
https://archive.md/lTfHl
2023-04-12 AI�������졧�ʤ�JRBC����Ω��
RVC(Retrieval-based-Voice-Conversion)���β����Ϥ���������줬Ω��
�ʤ�JRBC��
https://fate.5ch.net/test/read.cgi/liveuranus/1681...
�ʤ�JRBC wiki
https://seesaawiki.jp/rvc_ch/
�ʤ�JRBC��
https://fate.5ch.net/test/read.cgi/liveuranus/1681...
�ʤ�JRBC wiki
https://seesaawiki.jp/rvc_ch/
2023-04-08 �����ꤹ��Controlnet���Ǥ�
�����ꤹ��Controlnet���Ǥ�
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
https://huggingface.co/CrucibleAI/ControlNetMediaP...
�����Ƥߤ�
���Ȥʤ��餬���ΰ��֤ˤ��ơ�����Τۤ���������
�ܤȸ��˴ؤ��Ƥϥץ���ץȤ��꤭�ǡ���������Ƥʤ��褦�˻פ���
�ȥ졼�˥���ˡ�⤢��餷��
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
https://huggingface.co/CrucibleAI/ControlNetMediaP...
�����Ƥߤ�
���Ȥʤ��餬���ΰ��֤ˤ��ơ�����Τۤ���������
�ܤȸ��˴ؤ��Ƥϥץ���ץȤ��꤭�ǡ���������Ƥʤ��褦�˻פ���
�ȥ졼�˥���ˡ�⤢��餷��
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
2023-04-07 �ͥ��ƥ��֥ץ���ץȥ��ǥ��ƥ���
790����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 5f88-icd+)2023/04/07(��) 05:36:38.53ID:0N3FVRMd0 EasyNegative���ng_deepnegative_v1_75t��餬�����Τ��Ȼפä�����Ƥߤ���䤬���ʤ��������������ݤäƤ����ͥ��ƥ��֥ץ���ץȤΤ������������Ƥ����� �Ȥϸ������٤����꤫�⤷����˥������Τ�������ͥ��ץ������Ƥ���� ��Ƥߤ������ 793����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 7fc5-wedF)2023/04/07(��) 06:14:57.84ID:f6FbAY2j0 >>790 Prompt Editing��negative�˻ȤäȤ� �ǽ�˥��Х���negative����ƹ����Ͼ夲�Ƥ���饹��10�ѡ��ʲ��ǥ�ǥ���᤹�뵬��(worst quality, lower quality:1.4)�Ȥ��ˤ��ƥ����ȺǶ�Υޡ��������֤�����ǥ�Ǥ�ޤ������Ф��ץ���ץȥ��ǥ��ƥ�����ͥ��ƥ��֥ץ���ץȤ˻��Ѥ���Ȥ�����ˡ���Ҳ𤵤줿��
�ǽ餫��ͥ��ƥ��֤���ꤻ�������κǸ�ˤΤ�Ŭ�Ѥ����뤳�Ȥǡ����ޤ�����������뤳�Ȥ������褦����
2023/04/04(��)��LoRA�ؽ�GUI�����̳ؽ��� Stable Diffusion XL
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
LoRA�ؽ�GUI�����̳ؽ��Ǥ���褦�ˤ�����
https://github.com/RedRayz/Kohya_lora_param_gui/re...
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
Stable Diffusion XL�äƤΤ��Ф��餷�����ɤ��ʤ�����
2.�ϤϤ��������ˤʤ�ä�����
LoRA�ؽ�GUI�����̳ؽ��Ǥ���褦�ˤ�����
https://github.com/RedRayz/Kohya_lora_param_gui/re...
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
Stable Diffusion XL�äƤΤ��Ф��餷�����ɤ��ʤ�����
2.�ϤϤ��������ˤʤ�ä�����
2023/04/03(��)�åݥ��ࡢ�ڹ�˥������̥ޡ�����ɽ���ܸ���
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
989: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�(�������� dfbf-kVuH) sage 2023/04/03(��) 11:21:40.69 ID:B8m75gQR0
>>972
�����Ϳ�������ΤǤϤʤ������
��Ω�äƸ��դ�ͥ��ƥ��֤˻ȤäȤ뤱��Ω�ƤȤ�����ޥ�
Ω�äȤ�Ѥ����Ȥ�����ޥ��ʤ���
ɨ��Ĥ��ͤο��������⸫�������Τޤ��ݤ�Ω���夬��ʤ��ʹ֤��ɤ�������뤫
�ɥ�餷�Ȥ뤪���ͤˤ�ʬ���������
��Ω���衦������Ω���衦�����ä�ʡ�ܿ��Ԥ�ʤ�̡��������Ƥ����
�ޤ�����ϸ�Ω�ǤϤʤ���Ω��̵�Ť˷��줺�ĿͤȤ���֨Ω�����äư�̣��ä��褦�˵������Ȥ뤱��
������Դ֤Фä�Ω�ƤƤʤ��ǸĤ�Ω�ƤƤ�äȤ֤Ĥ���礨��
�����˰�ˡDL��Ƥ����ʹ֤����Ϥ������줿�������˻Ĥ�����ʸ�Ǥ��롡�ɤ��Ҥ��ۤ��褦��

https://fate.5ch.net/test/read.cgi/liveuranus/1680...
����
�����������Υݥ���
>7��
���ڹ�˥������̥ޡ�����ɽ���ܸ���
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
�������>>772�δڹ�˥������̥ޡ�����ɽ�����ܸ����ˤ�����
ľ����������ʤ��ư����⤢�뤫����������ä��鶵���Ƥ����
https://i.imgur.com/pBycwjt.jpg
�����������>>804�˥���LoCon�����̥ޡ�����ޤȤ�Ƥ���Ƥ뤫�餳��ɽ�ȸ���٤ƤߤƤۤ�����
https://rentry.org/lora-bw-memo
2023/04/02(��) �����̳ؽ�Ψ/������dim(rank)���ɲá��ڹߥ�����̥ޡ����λ���
�ե��ǥ��25�ĤΥ֥��å��dzؽ��Υ������Ȥ�dim������Ǥ���褦�ˤʤä���
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
������dim���ɲäޤ���kohya��ͭǽ���
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
������dim���ɲäޤ���kohya��ͭǽ���
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
>458>>481�ڹߥ�����̥ޡ����λ��������ä����餳�ä��⻲�ͤˤ��Ƥۤ���
https://i.imgur.com/vlB9XCs.jpg
2023/03/31(��)��ToMe (Token Merging for Stable Diffusion)
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
https://github.com/dbolya/tomesd
�ʤ���ʤ�äݤ���
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
1111��ToMeŬ�Ѥ��ƥ������٥����ä���29���椬26����ˤʤä���
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
tome�ϲ����٤��⤤�ۤ�®���ʤ뤫�����������ߤ������
https://github.com/dbolya/tomesd
�ʤ���ʤ�äݤ���
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
1111��ToMeŬ�Ѥ��ƥ������٥����ä���29���椬26����ˤʤä���
https://fate.5ch.net/test/read.cgi/liveuranus/1680...
tome�ϲ����٤��⤤�ۤ�®���ʤ뤫�����������ߤ������
ToMe�ʤ� https://i.imgur.com/39P0lYJ.jpg ToMe����(ratio=0.6) https://i.imgur.com/cNwAYk9.jpg
2023/03/28(��) �ؽ������������512�ǽ�ʬ���� VS 1024�ǹ��������
2023-03-27 �ʤ�JNVA������������
02/26�˹Ӥ餷��Ω�Ƥ��ʤ�JNVA159�ν�ʣ����
�쥹20�ۤ����٤��Ť������褦�ȥ����Dz�����Ƥ���Ƥ��������Ӥ�뤳�Ȥʤ�ʿ����1000�쥹�ޤ��դ��Ƥ������ܤ���
������ø��������������ͥ�������Ž�����̥��Ū�Ȥ������ǡ������٥������Ȥ��ƿ����줬��������
����Ū�ʲ��ä�¿���ܥ����Ž��ˤϤ���äȡ�����ͭ��ͤǤⵤ�ڤ�Ž����Ȥ��Ʊ��Ѥ������Ȥʤä�
�ʤ�JNVA������
https://fate.5ch.net/test/read.cgi/liveuranus/1679...
�쥹20�ۤ����٤��Ť������褦�ȥ����Dz�����Ƥ���Ƥ��������Ӥ�뤳�Ȥʤ�ʿ����1000�쥹�ޤ��դ��Ƥ������ܤ���
������ø��������������ͥ�������Ž�����̥��Ū�Ȥ������ǡ������٥������Ȥ��ƿ����줬��������
����Ū�ʲ��ä�¿���ܥ����Ž��ˤϤ���äȡ�����ͭ��ͤǤⵤ�ڤ�Ž����Ȥ��Ʊ��Ѥ������Ȥʤä�
�ʤ�JNVA������
https://fate.5ch.net/test/read.cgi/liveuranus/1679...
2023-03-25 ����
1111���������������ꡢ�Ƽ�ġ��뤬���顼�������ꤹ��褦�ˤʤä�
2023-03-25 MultiDiffusion
4K��8K�ʤ�Ķ����ʲ����������Ǥ���Ȥ�������ĥMultiDiffusion������ä�����ˤʤ롣
�ܤ�����������٤�����������ˡ��MultiDiffusion�ι��ܤ�
pkuliyi2015/multidiffusion-upscaler-for-automatic1111: MultiDiffusion implementation with VAE VRAM optimize - https://github.com/pkuliyi2015/multidiffusion-upsc...����������������Ĥ���������������ط��奢�åץ������顼�ˤ�äƤϤ�����Ȥ�����1girl���������Ȥ��뤿�ᾮ�ͤ�¿��ȯ���������ʤ��饦�������õ�����֤ˡ��ޤ����襤�餷�������Υ�ǥ�ʤ����������פǤ��ब���ꥢ�뵤̣�ʥ�ǥ�ǻ��Ѥ���ȤȤ��ȤĤ������֤��줿�ꥪ�֥������Ȥ�ɽ�̤˿��Τ餷����Τ����̤�ȯ��������(���ơġĻ����ơġ�)�ȿͤˤ�äƤϤؤ��ʥ�����꤯���Τ�����褦�Ǥ��롣
�ܤ�����������٤�����������ˡ��MultiDiffusion�ι��ܤ�
2023-03-23 ��������AI�����ӥ����祹�������(�ͥåȥ����ӥ���)
��;���ޤ����ˡ��֤ʤ�JnovelAI���פ���ֲ�������AI�����ӥ����祹���(�ͥåȥ����ӥ���)����������
- NovelAI������ϡ֤ʤ�JnovelAI���פ�
- ����¾�β�������AI�����ӥ��ϡ�NovelAI,Holara,TrinArt����������AI�����ӥ����祹��פ�
- �֤ʤ�JNVA���פϺ��ޤ��̤�ʤ�Ǥ⤢��(�Ǥ��˥������������)��
�ʤ�JnovelAI�����������68
https://fate.5ch.net/test/read.cgi/liveuranus/1679...
NovelAI,Holara,TrinArt����������AI�����ӥ�����
https://mevius.5ch.net/test/read.cgi/esite/1679527...
�ʤ�JNVA����176
https://fate.5ch.net/test/read.cgi/liveuranus/1679...
����¾��AI�����ط�����
2023-03-20 Windows Defender��VAE�ҤȤߤʤ�
�����Фäݤ���safetensors���Ѵ����Ʋ���Ǥ��롣
173����577
Checkpoint Merger��vae��safetensors�ˤ��Ѵ�������ˡ ��äƤ뤫�ɤ����Τ���Ѵ����Ʊ�ͤ˵�ǽ�Ϥ��� ��ö��vae�γ�ĥ�Ҥ�ckpt�ޤ���safetensors���ѹ�����\stable-diffusion-webui\models\Stable-diffusion �ե�������֤� ���ѹ����ʤ���Checkpoint Merger������Ǥ��ʤ����� �� nai.vae.pt �� nai.ckpt �������ͤ������Merge�ܥ����å� https://i.imgur.com/E0YOXca.png nai.vae.safetensors (395,100KB)����������� �ǽ�˰�ö�ѹ�������ĥ�Ҥ��᤹
https://huggingface.co/aka7774/fp16_safetensors/bl...
2023-03-18 torch2.0�ǹ�®��
3/16���ˡ�nightly�ǤϤʤ�torch 2.0.0���������줿��
����Ǥ�����ˤʤꡢ172����908���ʰפ���ˡ������
1111��issue��4chan��reddit�Ǥ�����ˤʤäƤ�����
Ƴ�������VRAM�ξ�������Ȱ��������˹�®���β��ä����롣
�ܤ��������������®������ˤޤȤ��
2023-03-11 ����������ץ顼UniPC
�ʲ��Υ��ߥåȤ�Auto1111�˿���������ץ顼������
- Merge pull request #7710 from space-nuko/unipc · AUTOMATIC1111/stable-diffusion-webui@a11ce2b - https://github.com/AUTOMATIC1111/stable-diffusion-...
- ����ץ顼¦�Υ�ݥ��ȥꡧwl-zhao/UniPC: UniPC: A Unified Predictor-Corrector Framework for Fast Sampling of Diffusion Models - https://github.com/wl-zhao/UniPC
2023-03-09 ������ץ��������
����ϼ�ư����NVA��������Ӥ餷�Ƥ����͡�
�����˻ߤޤ���⤢��С����ä�ư���Ƥ���⤢�äƤ褯�狼���
�����˻ߤޤ���⤢��С����ä�ư���Ƥ���⤢�äƤ褯�狼���
2023-03-09 Colab�Υǥե����Python��3.9.16��
����ư���ʤ��ʤäƤ�Τ������⤷�����б��Ԥ���ɬ�ס�
2023-03-05 LoCon
����Ū���̤Ǥ�LoCon�Ȥ���LoRA���ĥ�����褦�ʳؽ�ˡ�����餿�˥������줿���ȤǸ��ڤ�����˹Ԥ���褦�ˤʤä�����https://github.com/KohakuBlueleaf/LoCon
����Ǥ�LoRA��Controlnet������������äƤʤ��Τˤޤ���������ǰ���о줷�Ƥ⤦�Ĥ��Ƥ����ʤ��Ȥ����������ۤ鸫����褦�ˤʤä���
2023-02-28 chilloutmix�������
Civitai�ǥ���������ɥ��1�̤��äƤ����ꥢ��ϥ�ǥ롣
�ޡ�������ǥ�Υ饤���ˤ�äƾ������Ѥ����¤����ꡢ�������Ѷػߤ���Τ����Ȥ�����
�������Ѥ���˾���꼡�������ᡢ����˾������ѲĤˤ��������ǥ뤬�о줷�������ߥǥ�ǥ������
Civitai���Ĥ���ľ���˺Ƹ������ᤵ������λ��֤Ȥʤä�����
�ä��礤������Civitai���Ĥ���Ǥ�ˤ����ƥ�ǥ��ƷǤ�����ˤʤä��ͻҡ�
https://speakerdeck.com/nhamanasu/diffusionniyorut... ���
ChilloutMix ���ܡ��ڹ�������ʥ������ͽ����μ̼�Ū�������ò������ޡ�����ǥ롣����˲ä��� �ͷ��Τ褦�����ä����Ƥδڹ�����̼��������ò�����LoRA��ǥ�Ǥ��� Korean Doll Likeness����������졼������ꥭ��饯�����ò�����LoRA��ǥ� HMS Cheshire �� �Ȥ߹�碌�뤳�Ȥǡ����˥�ƥ����Ȥʰ�����Ż���ĤĶˤ�Ƽ̼�Ū�ʽ����β������� ��¸������桼�����⸽�졢�������AI�����ץ쥤�䡼�פȤ��ƻ��ݤ�Ƥ���� ��ԤϽ��פ����ջ���Ȥ��ơ��ºߤ����ʪ��Ƹ����뤳�Ȥ��Ѥ����ꡢ�ºߤ����ʪ ��̾����������ǥ��������������ʤ��褦�ƤӤ����Ƥ��������ºݤ������μ̼� �����夬�ä����Ȥǰ����β���ɽ���侦����Ū�����Ѥ���Ƥ��ޤ����������������졢 Feb 28, 2023 �������Ƚ�ǤǸ���������֤��֤���줿��
ControlNet�ε�ǽ��������Ƚ��








2023-02-13 WD1.5�¤��Ф���ControlNet���б�����������Ѥʰ���
����
NAI����η������ʤ����ʥ�ǥ롢���SD2.1�ϤȤ����������ܤ���ӤƤ���WaifuDeffusion1.5��(epoch1)���褦�䤯�������줿
�����ޤǤˤ�3,4epoch�ݤ���Ȥ��ä�����epoch1�λ����Ǥ��ʤ����ʳ�����Ͻ���Ƥ��ꡢ�����Ǥ˴��Ԥ���ޤ�
�������ޤǤΥץ���ץȤ�����������ݤ����ˤʤ꤬���ʤΤǡ������ʥץ���ץȹ�����������
���ܸ����Ϥ����顡WD 1.5 �١����� - �����Ρ���
���
ControlNet��1111��extensions���о�(�����2���ब�ۤ�Ʊ����)
ControlNet�Ȥϡ��̿�����ݡ�������Ф����������ꡢ���饹�Ȥ����������Ф����������ꤹ�뿷����(https://github.com/lllyasviel/ControlNet )
������ʸ��ȯɽ����3����1111��extensions�˼�������ơ����줬�ðۤȴ�������Ĥ���ޤ줿
unprompted Extension����Mikubill/sd-webui-controlnet����2���ब���뤬��Ƴ�����ưפ���Ȥ����δ��ؤ�����Mikubill��sd-webui-controlnet�������͵�
����VRAM8GB�Ǥ�ư��������Ȼפ�줿����¨��LowVRAM�б��Ǥ��Ф�VRAM8GB�桼�����Ǥ�Ȥ���褦�ˤʤä�
����ˤ������DZ�����Ϻ�ɤ�������Ⱦ���DZ�����Ϻ�ˤʤ�ͤ�³�Ф���
NAI����η������ʤ����ʥ�ǥ롢���SD2.1�ϤȤ����������ܤ���ӤƤ���WaifuDeffusion1.5��(epoch1)���褦�䤯�������줿
�����ޤǤˤ�3,4epoch�ݤ���Ȥ��ä�����epoch1�λ����Ǥ��ʤ����ʳ�����Ͻ���Ƥ��ꡢ�����Ǥ˴��Ԥ���ޤ�
�������ޤǤΥץ���ץȤ�����������ݤ����ˤʤ꤬���ʤΤǡ������ʥץ���ץȹ�����������
���ܸ����Ϥ����顡WD 1.5 �١����� - �����Ρ���
���
ControlNet��1111��extensions���о�(�����2���ब�ۤ�Ʊ����)
ControlNet�Ȥϡ��̿�����ݡ�������Ф����������ꡢ���饹�Ȥ����������Ф����������ꤹ�뿷����(https://github.com/lllyasviel/ControlNet )
������ʸ��ȯɽ����3����1111��extensions�˼�������ơ����줬�ðۤȴ�������Ĥ���ޤ줿
unprompted Extension����Mikubill/sd-webui-controlnet����2���ब���뤬��Ƴ�����ưפ���Ȥ����δ��ؤ�����Mikubill��sd-webui-controlnet�������͵�
����VRAM8GB�Ǥ�ư��������Ȼפ�줿����¨��LowVRAM�б��Ǥ��Ф�VRAM8GB�桼�����Ǥ�Ȥ���褦�ˤʤä�
����ˤ������DZ�����Ϻ�ɤ�������Ⱦ���DZ�����Ϻ�ˤʤ�ͤ�³�Ф���
2023-02-06 ������ץ�����
�ܥ���143�����פ���Ϣ��Ӥ餷�ˤ��ä���Ȥ���Ƥ�����145�ǤȤꤢ�������衣
ǰ�Τ��ᤪ�Τ餻���Ȥ��ޤ������Ŀ�Ū�������Хå����åפȤäƤޤ���
ǰ�Τ��ᤪ�Τ餻���Ȥ��ޤ������Ŀ�Ū�������Хå����åפȤäƤޤ���
- �ܥ�����̤������ȤäƤ�
- https://github.com/aka7774/nai_ch_wiki
- https://github.com/aka7774/stable-diffusion-webui
- wiki�ϥ�������Хå����åפΤ�äƤ���
2023-02-05 ����̱������
�䤡���פ��֤���ʡ������ä�����������Τߤ�ʤ����Ѥ�餺������
�������ʡ��Ƕ��LoRa�Ȥ����������ؽ���ˡ��ή�Ԥ��Ƥ��ƿ����ʳؽ���ǥ�𤹤�˥�����������
�����ɥ������ʥ를�������ġ�🐧�����åե��������ꥳ�������Ƥ��ġ��ǹ������
������Lora�ؽ������ڡ�������褿�����
�Ƕ�AI���饹�Ⱥ����˶�̣����äƤ�äƤ���������̱��¿���ߤ�����
��ư����ס֥��顼�Ф��ס�xformers�����ס֤狼���ס�🎈��
�����������������Ĥ��̤����
����ˤ��Ƥ⡢����ζ��뤬˾��ʤ����ĤƤβ����������������ºǿ��ǤΥ���Ǹ���Ȥϻפ�ʤ��ä��衣
����������Ϻ�ˤʤä���ʬ��
�����⤿�ޤˤϤ��ä��˵��äƤ����衩���ߤ���ԤäƤ뤾
�������ʡ��Ƕ��LoRa�Ȥ����������ؽ���ˡ��ή�Ԥ��Ƥ��ƿ����ʳؽ���ǥ�𤹤�˥�����������
�����ɥ������ʥ를�������ġ�🐧�����åե��������ꥳ�������Ƥ��ġ��ǹ������
������Lora�ؽ������ڡ�������褿�����
�Ƕ�AI���饹�Ⱥ����˶�̣����äƤ�äƤ���������̱��¿���ߤ�����
��ư����ס֥��顼�Ф��ס�xformers�����ס֤狼���ס�🎈��
�����������������Ĥ��̤����
����ˤ��Ƥ⡢����ζ��뤬˾��ʤ����ĤƤβ����������������ºǿ��ǤΥ���Ǹ���Ȥϻפ�ʤ��ä��衣
����������Ϻ�ˤʤä���ʬ��
�����⤿�ޤˤϤ��ä��˵��äƤ����衩���ߤ���ԤäƤ뤾
2023-01-28 HN�Υɥ��åץ��������褷���ʤĤ��Ǥ�LoRA���դ�����
2023-01-22�λ����ѹ��ˤ��ä���HN�Υɥ��åץ��������褷��
Ʊ����Lora�Υɥ��åץ�������դ����褦�ˤʤä�
������ˡ�� Settings �� User interface �� Quicksettings list ���ɲä���
Ʊ����Lora�Υɥ��åץ�������դ����褦�ˤʤä�
������ˡ�� Settings �� User interface �� Quicksettings list ���ɲä���
- sd_hypernetwork
- sd_lora
- extra_networks_default_multiplier
������sd_hypernetwork_strength���ؤ���HN��LoRA����
2023-01-28 pix2pix��ǥ�ޡ������������줿
extensions��stable-diffusion-webui-instruct-pix2pix���о줫��2����Ǥ�դΥ�ǥ��pix2pix��ǥ�˥ޡ������뵡ǽ���������줿
����ˤ�깥���ʥ�ǥ��pix2pix���Ȥ���褦�ˤʤä�
pix2pix�Ȥϴ�ñ�˸����й��ޤΤޤޤ���γ����ؤ��뵻��
img2img�Ȱ㤤���ѹ��ؼ���ʸ�Ϥ����Ϥ��������Ǥ�Ĥ����ޤޤǽ�����
����ץ�Ϥ���ʴ���
����ˤ�깥���ʥ�ǥ��pix2pix���Ȥ���褦�ˤʤä�
pix2pix�Ȥϴ�ñ�˸����й��ޤΤޤޤ���γ����ؤ��뵻��
img2img�Ȱ㤤���ѹ��ؼ���ʸ�Ϥ����Ϥ��������Ǥ�Ĥ����ޤޤǽ�����
����ץ�Ϥ���ʴ���






2023-01-24 Anything-v3.0�����
NAI���������о줷�ư��������Ӥ�����ǥ뤬��Ԥˤ�äƺ�����줿��
https://twitter.com/linaqruf_/status/1616821313804...
1/26�����褷����VAE��̵���ä���
https://huggingface.co/Linaqruf/anything-v3.0
VAE��ɬ�פʤ�Anything-v4.0Ʊ���Τ�Τ�Ȥ�����
https://huggingface.co/andite/anything-v4.0
2023-01-23 torch��xformers�ο侩�С��������kohya��LoRA�������б�
- torch:1.13.1+cu117 xformers:0.0.16rc425 �˿侩�С�����夬�ä�(RTX4000��������б���)
- kohya��LoRA��0.4.0�Ȥ�������������б����줿(0.4.0�Ϧ����б�)
���ΰ١�������Ǥ�4000�桼������LoRA�˴��Ԥ���Ԥ����Τι�����torch��xformers�ι�������Ƥˤ��������ġ�
- ̵����ư�����
- xformers�Υ��ȡ���˼��Ԥ��ƴĶ������줿��
- �н�ˡ��ʹ���Ƥ��꤯ư���ʤ���
- ��ư�Ϥ�����4090�ι�®�����Ƥ����Τ���®����ư����®���㲼�˸�������
- ���ΥС�����������ˤ�git checkout ���б������ʪ�Ǥ�̵���٤˺ƥ��ȡ����;���ʤ�������
- venv�������Ƥ��ľ�����Ȥ��Ƥ⼺�Ԥ����
- ���⤽����λ�����Ƚ��ʤ���
- �����¾�ͤ�Ǥ���ƾ�������ǡָ��פ�Ű�����
�������˥Хå����åפ��äƤ����ޤ��礦
Linux(��wsl)�Ķ��οͤ�venv�������Ƥκƥ��ȡ��롢���ϥ���ȡ�����硢���Τ�1111��xformers��0.0.13������褦�Ȥ��Ƽ��Ԥ���
���ΰ١���ư��xformers�ȡ��뤹��ɬ�פ�����
venv/bin/activate
pip install xformers==0.0.16RC425
deactivate
2023-01-22 HN��Lora�����������ѹ�
- HN�Υɥ��åץ�������ѻߤˤʤä���(�ޤ�Extension��Ԥ��б����ɤ�줿)
- �ץ���ץ���� <hypernet:�ե�����̾:1.0> <lora:�ե�����̾:1.0> �Ȼ��ꤹ��
- ʣ������Ǥ���
- kohya�Ǥˤ��б����Ƥ�餷��?
- Generate�ܥ����֤�������������ƥץ���ץȤ��������뤳�Ȥ�����
HN�������������ϵ�����ꥢ������ľ������
69 ̾��������ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� cf71-XiKU)[sage] �������2023/01/22(��) 13:05:46.16 ID:OK6KChyN0��null����ʤ���none�ʤΤ��������Ϥ���������(63��64�����դ�)
����ޤꤪ���Ȥϻפ������
���ץǸ�˳��������ߤˤʤä���hyperNetwork�������ʤ��ä��ͤ�Ͼ�Ǥ�ФƤ��̤��С�������hyperNetwork�����꤬�ĤäƤƿ������ɤ߹��������Ⱦ��ͤ��Ƥ뤻����
config.json����Ģ�dz�����sd_hypernetwork��null�ˡ�sd_hypernetwork_strength��0.0�˽�������ľ���
"sd_hypernetwork": "None",
"sd_hypernetwork_strength": 0.0,
2023-01-14 ��ǥ�ޡ�������³��
��ǯ��������ˤʤä���1token�ܤ�̵�뤵�������ꡢ�ƽ��ͭ���Ԥ����θ�⸦�桦Ĵ����ʤ��̡���ǥ������ǡ�������»����»�Υᥫ�˥��ब�������ٲ�������Ƥ�����
fp16�ˤ���в�衢������äǤϤʤ��ä���
https://note.com/bbcmc/n/n12c05bf109cc
[Ĵ��] Smile Test: Elysium_Anime_V3 �����Ĵ�٤� #3
https://fate.5ch.net/test/read.cgi/liveuranus/1673...
353����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� ca14-PB+X)2023/01/14(��) 22:31:53.53ID:pwfG6ymh0
����������������ȡ���������������夯�ʤ�ǡ������꤬���Ĥ��äƤ�ߤ�����͡ʺ����Ľ��˶ᤤ�̤������
ȱ�ο���̵�����ˤʤ����,���줿��������Ƥ������ä����ɡ�����β�ǽ��������Τ��Ķ����������
397����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 2961-7DGa)2023/01/15(��) 00:18:05.61ID:oxzRJQgt0
https://seesaawiki.jp/nai_ch/d/Models~~ �������οͤ������������Ƥ���Ƥ뤫��Ƭ�ˤ���������Ȥ����ۤ������������
>405����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� dd1e-hn8B)2023/01/15(��) 00:40:33.18ID:eNiHgcBj0
��ˤ���ڤ��Ƥ���Ȥ�˥������뤱�ɡ���ǥ������token����ǽ���ˤ�������ˤĤ��ƶ�ͭ���Ȥ���
�ޡ���extension�κ�Ԥ���Ely3��1token̵������ˤĤ��Ƹ��椷�Ƥ���Ȥä��Τ����ϰϤ��ɻ��������
������ https://note.com/bbcmc/n/n12c05bf109cc~~
�����ˤ���extension�Ǥν������Ƥ������
https://majinai.art/i/zMw-3YY~~
cinnamon��������41token�˰۾�token������餷�������礦��hand on hip�Υץ���ץȤˤ��줬�������Ƥ�
force reset�ǽ���������ǥ��hand on hip�������䤹���ʤäƤ뤷����������cinnamon��hand on hip hip�äƤ����ץ���ץȤˤ���ȸ����褦�ˤʤä�
��������ϡ�add difference�Υޡ������ط������ǥ�פ˵����뤫�顢����ή�̤��Ƥ��¿���Υ�ǥ�˵����äƤ��ǽ�����������

�嵭note�ˤƥ����å��ġ����ȯɽ���졢����ޤǥޡ�����ǥ�����������Ѥ��Ƥ�������̱�δ֤�ư�ɤ����äƤ��롣
https://note.com/bbcmc/n/n12c05bf109cc
����Ǥ�Ĥ�������
������ܤ�����硢�ץ���ץȤθ��������Ѥ�뤿�ᡢ����ޤǤȤϳ������Ѥ�ä��ȴ������ǽ�������롣
�ޤ����ä� training/fine-tune ���Ƥ����硢���ζ��ä� CLIP ����dzؽ����ʤ�Ǥ�����硢��ǥ��������ǽ���Ѳ��������������ǽ�������롣
��®��������ǥ�ǡ�������������Ԥ��꼡������
�������������ʤ������¸���Ƥ������ץ���ץȤ�Ʊ�������Ƹ��Ǥ��ʤ��ʤä���
�����ˡ�Ȥ��ƤϿ���ξ���Υ�ǥ����¸���Ƥ��������ӤǻȤ�ʬ���뤷���ʤ�����ã�Υ��ȥ졼���ζ������̤��ס����ʤ��ʤ�����������ڼ¤��⤷��ʤ���
2023-01-11 StableTuner
https://github.com/devilismyfriend/StableTuner
�Ƕ�Ϥ�äƤ���餷���������ɲóؽ���
�ᤤ��UI���äƤ�����ߥ����ʤ��������ɤ��Τ��������餱(129����319)��
�����https://fate.5ch.net/test/read.cgi/liveuranus/1673...
167����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 611e-K0Bq)2023/01/11(��) 19:05:29.78ID:J3TotN+o0>>174>>275
���163
Ʊ���褦�ʥ��顼�Ǥɤ���äƤ�ޤȤ��ư���ʤ��ä����顢extension���������ʤäƤʤä�
3090�ʤ�stable tuner�Ȥ��Υ���������
��������ʤɤϤۤȤ�ɤʤ����ʲ��Τ褦�ʰո��⤢�롣
309����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (������������ Sa85-TcZo)2023/01/13(��) 12:24:01.28ID:JvPRbxiDa>>318
[���ܺ�]�Τ�Ĥ�GUI�б����Ƥʤ������Ǥ�����
���˳ؽ�����ʤ�stable tuner����������虜�虜Lora������ TI�Ǥ褯�ͤä�4¦��ʤ�ĤĤ���
vram24gb�侩�ʤΤ��ٹ�����Ǥ��뤬�����꼡��Ǥ�12gb��ư���Ȥ����ä⤢�롣
https://fate.5ch.net/test/read.cgi/liveuranus/1673...
325����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 1991-tb1I)2023/01/13(��) 12:45:53.77ID:majIue8q0>>338
12GB��textencoder�ڤ�����̤˹Ԥ����
DB�ϸ�������ʳ��������ʤ��Ȼפ�
2023-01-05 1111�ü�����
���ѡ�https://fate.5ch.net/test/read.cgi/liveuranus/1672...
893����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (���������Îێ� Spbb-mKYw)2023/01/05(��) 18:32:56.80ID:Nw26Fgbzp⋮
https://github.com/AUTOMATIC1111/stable-diffusion-...
WebUI��ʱ��
���ߤ����줷����
�����Ϥ��ܿ�۩����wiki�˷Ǻܤ���Ƥ�����˥�����Ȥʥ���ƥ�Ĥ����ä�������
�켡��������ä��Ȥ�����
GitHub��ᥤ��˻ȤäƤ�GitGUD�ϸŤ��ޤ����֤���Ƥ����ͻҡ�
ǯ��ǯ�Ϥ�ư���⤢�碌�ơ����饦��̱���ƶ�������䤹���Τǡ�
��³���ȥ졼���˰����Ǥ�ȤäȤ����ۤ��������Τ��⡣
2023-01-05 �֤����
���������Ƴ����ˡ�Ȥ��ơ��֤�������ȡ��顼�פ�ȯɽ����롣
(���դϤ⤦����äȸ���ä�����)
�Хå��ե������å����������1111��ư���ȡ��뤷�Ƶ�ư����Τ���ħ��
����ʤ��֤����Ǥ����롢�ȡ������ɾ�������롣
ž���ơ��ʰץ��ȡ��顼���̤��֤����ȸƤ֤褦�ˤʤä���
(��: �Ȥ��������֤����LoRA�Хå�)
�ޤ����鿴�ԤΤ��Ȥ��֤����ȸƤ֤褦�ˤʤä���
�Ƕ�ǤϤ�����ʿͤ��֤���å���ȯ���Ƥ���Ƥ�Τǡ�
�����ʤ�ĤĤ����顢�ɤ��֤���å�������Ū�˸��äƤ����Ƚ����롣
2023-01-04 ��������
NVA����ˤ����ƥ����ȥ����ä�💩����💩�ˤα���Ȥ����������Ѥ�����褦�ˤʤä����ä����Ȥʤ�������
����🎈���դʤɤηٹ𤬥쥹�ˤĤ��Ƥ������ϳи礷�Ƹ���褦�ˤ��褦��
�аޡ�https://fate.5ch.net/test/read.cgi/liveuranus/1672...
�����������inpaint������ˡ��Ҥͤ�Ȥ������̤��������Ƥ��ä��Τ����������˲��ä����߹��ʤ��ʤäƤ�����
250����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (������������ Sac7-e/aH)2023/01/04(��) 19:57:31.68ID:7QCJRhmka⋮>>261>>290 �㤨��inpain�Ȥä������Ф����طʤ�ʷ�ϵ���碌�����Ȥ��롣t2i�Ȥ������̤˥ץ���ץȤDz�����롣���줬�����ʤ��θ��β����� �ޤ������β����������β�����Ž���դ��롢���λ����Ǥ�Ķ������ ���ˡ����β�����inpaint�˻��äƤ��� �����ǿ�Ĵ���碌����äƤΤ�inpaint�β��ͤ��Ȼפ�������ɡ������Ǥ��ʤ��Ȥ����ʤ��Τäưʲ��ǹ�äƤ롩 1.�����Ȥ��μ�����ɤ��٤� 2.���Υץ���ץȤ���������ɤȤ�������� inpaint���� ��Τ�������ȷ�ɥ֥��ɤ����������ƥ�Υ�����ɤ�SD��ǧ���Ǥ����Τ���ʤ��Ȥ����ʤ�������ʬ�⤽�α�ñ����ΤäƤʤ��㤤���ʤ�����Ĥ�����������Ū����������Ȼפ�줿����
293����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (������������ Sac7-e/aH)2023/01/04(��) 21:02:12.09ID:nxWl5dxRa⋮>>296 >>290 �����Ȥ��Թ礤�����ȸ��ä����ɡ��פ���ˤ֤ä���������� ���ξ��Ϥޤ���cum�Ȥ�������ɤ�äơ����Ҥ�Ʃ�������Ž�ä�inpaint���ᤷ�������Τ�ޥ�������generate?�ºݤϤ��줹������Ǥ��ꡢ������Ū�Ϥ��������Ǥ��ä���
305����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (������������ Sac7-e/aH)2023/01/04(��) 21:14:31.70ID:nxWl5dxRa⋮>>309>>315>>332>>342>>353>>406>>409 >>296 ���ޤ֤ä����Ȥ����̤ʤ��ȸ��ä����ɡ������Ϥ��������褻������� �����麤�äƤ�
315����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (������������ Sac7-j4Lu)2023/01/04(��) 21:24:10.80ID:gxM4KjZda>>318⋮
>>305
���֥顼�Ȥ����������äƸ��ä��������������դǤ���
��
���դ⥪�֥顼�Ȥ������������ϥ��Ǥ���
😅
����˻ɷ������������ȥ������Ȥ��ɤ�����Ȥ�ʤ����쥹���ȥ�������ĥ���դ��Ƥ��ä����ᡢ¿���Υ���̱�˥ȥ饦�ޤ��դ�����
135����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 078a-1D2s)2023/01/05(��) 22:25:56.69ID:JT9GZ0bb0⋮
�㤨��ġ������ġġ����áġ�Ƭ���ġ�
136����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� bb7b-d25T)2023/01/05(��) 22:27:01.33ID:JzIWT9pR0⋮
>>133
����λ��ٲ����Ƥ���
����磻�⤽��Ϣ�ۤ�������
�����������pixiv�ˤ����뤪�꤬�����ˤʤ�Ȥ������פⵯ���Ƥ��ޤä���
385����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�ݎЎݎ��ގ� MM8a-1R73)2023/01/06(��) 08:12:14.72ID:c3FFjjFgM⋮>>390>>397
pixiv�κ����Τ��꤬�����餷������������Inpaint�Υƥ��˥å����Ȥ���������Ƥ��ޤ��礦
�ʤ����ͤϤ��λ����Ƥۤ����ʤ��褦�ʤΤǵ����դ��褦��
���������ε���������🎈�ΰ�̣���Τ�ʤ�����ȥ���鿴�Ԥ����դ�¥����̣�ǤϿ���Ƥ������Ȥˤ��롣���ή���ʤ���Τ⤢�롣
503����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 9311-MUzp)2023/01/09(��) 14:48:27.65ID:Ds/FFlY40⋮>>511
>>494
���ޤ�
�����ᤦ���ä�����Ǵְ㤤�ʤ���
���Ȥ�wiki�α�������������ɲä��ˤ�ʤ��ʡ�
511����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (������������ Sa85-mr8z)2023/01/09(��) 14:55:06.90ID:5XoRgcv4a⋮>>514>>518>>519
>>503
�������������䤱���Ѥ����������鼭��Ƥ���w
�嵭�λ��狼������塢huggingface�˥ʥ��Υ�ǥ뤬���åץ����ɤ��줿��
������ʤ����ܺ٤�ï�ˤ�狼��ʤ����狼��ʤ������������
https://huggingface.co/unkounko/BalloonMix
ǯ��ǯ�Ϥ�ư��
ǯ��ǯ�ϤϤ���ޤǤ����ۤ��ˤä����Τ褦������ι�����å��塣
gradio�ΥС�����夬�ä��ꤷ��Extension��Ԥ��б����ɤ��ޤ��ä���
2022ǯ����
2022-12-28 ���ԡ���
�����������뤢��ͥ���
119����394
ī����ޤ路�Ƥ������������ɸ����ä�😢
Ʊ395
>>394 �褦�����ԡ�����
Ʊ419
�ʤ��Ʊ���ΤФä���� https://imgur.com/frsXfIg.png
🎈�Τ褦�ʥ���ѥ��Ȥ�̵���ä��������˻Ĥ���դˡ�
130����229
�����ɸ��ꤷ�Ƥ�6����Ʊ��������äƤ�wwwww �Ϥ�
Ʊ243
>>229 ���ԡ�������
Ʊ311
���ԡ����ɻ�Extension��ä���ǡ� https://github.com/aka7774/sd_copyguard
ž���ơ���ؽ��ʤɤǸΰդ�����������̻������ˡ�Ȥ��Ƹ줬�Ȥ���褦�ˤʤä���
���ꥹ�ޥ��ץ쥼���
���ꥹ�ޥ�����ǯ���ˤ����ơ�
���̥ޡ��������̤�Ϥ���Ȥ���ޡ�����ǥ뤬�������ۤ���롣
���ˤ���twitter��Discord�����ۥ�ǥ�쿧�ˤʤä��Ȥ���
���ۤˤ� Huggingface Hub��Ȥ��Τ��侩�����֤�����̵���¡�
���������ۤ��뤳�ȤǺ����Ԥ�����������Τˤʤ롣
12����889
ž�ܤ����Ȥ�����ʤ��ƴ��ۤ�ʹ����Τ��ᤷ�������� �磻��100%�μ����ǽФ��Ȥ�������ʤ������ �ɤ줬ɾȽ��������������в����Ǥ�������
�Ȥ����櫓��7th������δ��ۤϥ���˽Τ��������ᡣ
�ޡ����ΥХ�ȯ��
119����905����������
���մ����Ǥ��� ���ߡ�text encoder�����줿��ǥ뤬�в�äƤ��ơ����줿��ǥ�ϥץ���ץȤκǽ����ʬ��̵�뤷�ޤ��� ���줿��ǥ��ޡ������Ǻ�˻��Ѥ���ȡ����Ϥ��줿��ǥ�����ޤ��� ��ʬ�Υ�ǥ�˾ɾ����ФƤ��ʤ�����ǧ���뤳�Ȥ����ᤷ�ޤ���
75n+1���ܤΥȡ������̵�뤹��餷����
�ܤ����ϸ��쥹�Υ����ǡ�
119����914
��Ⱦ������ʤ��ä��� 7th_anime���������ä� Sleepy cute loli ����Τߤ��������ơ����꤬���ʤ��ä��饢���Ȥ��
��������������������̤��������줿�ΤϤ���ȯ���Τ�����
120����39
��äȰ켡���ڽ���ä���� �����Ȥϡ�Abyss_7th_anime.ckpt (V1.1�ǽ�����)��Elysium_Anime_V3.safetensors��etr_odyssey.ckpt ���졼�ϡ�mdjrny-v4.ckpt ������Ƥ롩����sd-v1-4.ckpt��sd-v1-4-full-ema.ckpt��v1-5-pruned.ckpt ʣ�������ɤǸ��ʤ���sd������Ƚ�Ǥ�Ǻ��Τ�Ф��Ƥ����
������ˡ
120����47
�褷��ľ�ä� ľ�����ϡ���ǥ�A�˲���Ƥ��ۡ���ǥ�B��������� ���̥ѥ�����ALL 0��base alpha��1 �ˤ�������
{kind=link}
���̥ޡ���
automatic1111�γ�ĥ��ǽ
https://github.com/bbc-mc/sdweb-merge-block-weight...
���路�������إޡ�������
���https://fate.5ch.net/test/read.cgi/liveuranus/1671...
468����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (������������ Sa9f-jh29)2022/12/18(��) 23:31:59.96ID:SnVtaxLOa

���إ�������NAI
anygape�Υƥ�ץ�Ϥ⤦�������
��ħ�Ȥ��Ƥϼ�ΰ���Ū�ʥꥢ�뤵�Ǥ��롣����ˤ��ε��Ѥˤ�äƼ�Ȼؤ���þ������ֲ��������ΤǤϤʤ����ȹͤ����Ƥ��롣
�������¼̷ϥޡ����θ��̤ϼ�Τߤ�α�ޤ餺���ꥢ������Τ����ԤˤȤäƤ������ʿ���ˤʤ�Ǥ�������
https://github.com/bbc-mc/sdweb-merge-block-weight...
���路�������إޡ�������
���https://fate.5ch.net/test/read.cgi/liveuranus/1671...
468����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (������������ Sa9f-jh29)2022/12/18(��) 23:31:59.96ID:SnVtaxLOa
���إ�������NAI
anygape�Υƥ�ץ�Ϥ⤦�������
��ħ�Ȥ��Ƥϼ�ΰ���Ū�ʥꥢ�뤵�Ǥ��롣����ˤ��ε��Ѥˤ�äƼ�Ȼؤ���þ������ֲ��������ΤǤϤʤ����ȹͤ����Ƥ��롣
�������¼̷ϥޡ����θ��̤ϼ�Τߤ�α�ޤ餺���ꥢ������Τ����ԤˤȤäƤ������ʿ���ˤʤ�Ǥ�������
�ʤꤹ�ޤ���ư�ǰ�������
493����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 8b1e-CLTW)2022/12/19(��) 00:51:39.39ID:nICEWkdN0
468��ï���狼��ɰ㤦�ͤ��
��Ϥʤ��������㤷�Ƥ뤱�ɡ��ޤ��ޤ���Ψ�����
�ʤ�Ǥ����ʤ�Τ��Ϥ��äѤ�ʬ������
511����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (������������ Sa9f-jh29)2022/12/19(��) 01:28:31.57ID:L+4DHmw0a
�ޤ�����ѵͤ�Ƥʤ�������ä����̾��˳Ȼ������褦�Ȥ��Ƥ���ǥ��������ɤǴ��˸����Ƥ뤫��������뵤�Ϥ���ޤʤ���
512����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 8b1e-CLTW)2022/12/19(��) 01:33:53.93ID:nICEWkdN0
���511
�ʤ�Ȥʤ����äƤ뤳�ȤϹ�äƤ뤱�ɡ��٤ä�Ŭ���ʾ�������ΤϤ��Ƥ����Ƥ���
�ǥ�������Ž���Ƥ��ꡢ�ɤ����˴��˾夬�äƤ�ʳ��β����Ϸ��ˤ�Ž�����
�Ĥޤ�8b1e-CLTW=�̤�����ߤǤ��äơ�Sa9f-jh29��ž�ܤ������������������Ƥ���ΤǤ���������
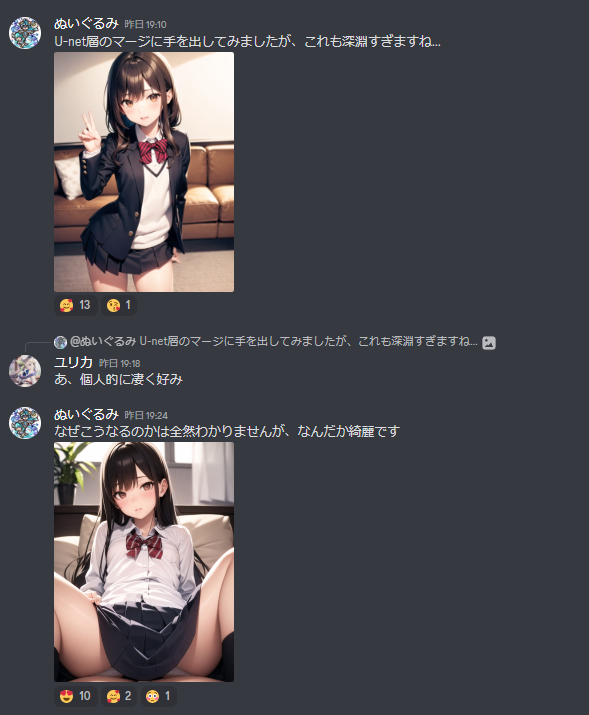
531����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� be28-0o0D)2022/12/19(��) 02:08:33.23ID:bfypsCrG0
�����ͤβ����ѥ��äƸ������뵤�Ϥʤ����Ȥ�ȴ�����Ƥ�� �����̵�ͤʤ��Ȥ��롩
�ʤ�Sa9f-jh29�Ϥ��Τ褦���ԲIJ�ʹ�ư���Τ���
�ͤ�������Ū�Ȥ��Ƥ�
��ñ��ˤ���ۤ䤵�줿���ä�
����ʬ�ǤϤ̤������γ�����Ƹ��Ǥ��ʤ��ä��ΤǤʤ�U̱�˥ޡ����θ���ʤ����Ƥ������̤���⤦�Ȥ���
�ʤɤǤ���������
���˭�����Ū���ä��Ȥ���ȡ�468�ʹߤΥ����ή������̥ޡ����쿧�Ǥ��ꡢ�ޤ�ޤȤ�����Ū��ã������Ƥ��ޤä����Ȥˤʤ롣
���ٿ���
ai��depth map���ä���After Effect�Ȥ�Blender�Ȥ��Ǥ����������ȤǤ���
���https://fate.5ch.net/test/read.cgi/liveuranus/1671...
581����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 0fed-ZR1D)2022/12/17(��) 00:07:51.88ID:ZqNYEP3K0
���ٿ��ꤷ�����äѤ�
https://i.imgur.com/2kEfJEv.mp4
https://i.imgur.com/oIlw2Bf.mp4
https://i.imgur.com/26cXt93.mp4
���Υ쥹�ʸ���ƼԤ��äˤ�����ʤɤ��������Ƥ��ʤ�
���https://fate.5ch.net/test/read.cgi/liveuranus/1671...
581����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 0fed-ZR1D)2022/12/17(��) 00:07:51.88ID:ZqNYEP3K0
���ٿ��ꤷ�����äѤ�
https://i.imgur.com/2kEfJEv.mp4
https://i.imgur.com/oIlw2Bf.mp4
https://i.imgur.com/26cXt93.mp4
���Υ쥹�ʸ���ƼԤ��äˤ�����ʤɤ��������Ƥ��ʤ�
WD1.3.5����ֽФƾä���
�٤���٤�Ƥ���WD1.4�Υƥ��ȤȤ��ƺ��줿��ǥ롣
TrinArt+Eimis�١�����
Eimis��NAI�١������Ȼפ��뤿����Ƚ�ˤ�����NAI������OK��Ф�������������ߡ�
�ǽ��110k steps��������ǥ��Ĥ���
SD2.1�١�����WD�ϥ����������¼�̤��ˡ�
112����648
�羾��🤗�ϥե����뤬�ä���Ƥ���Υ��ߥå��������������ɤǤ��뤾��
https://huggingface.co/hakurei/waifu-diffusion-v1-...
NAI�١������ɤ����ϼ����ʳ���Ƚ�ǤΤ��褦���ʤ���
��ӥġ���ȶ����о줷��¾��ǥ��ޡ�������Ƚ�˽��Ϥ�����ǥ뤬�Ф��ꡢ
Danbooru�����ؤ�ȿ����˥�ǥ�����Ԥ˶����ޤ����Υĥ����Ȥ��ǥ�����Ԥ��Ф��ꤷ�ơ�
�ݥ���NAI��ǥ�����������Ͻ������٤Ȥ����襤�����깭�����Ƥ�����
114����831
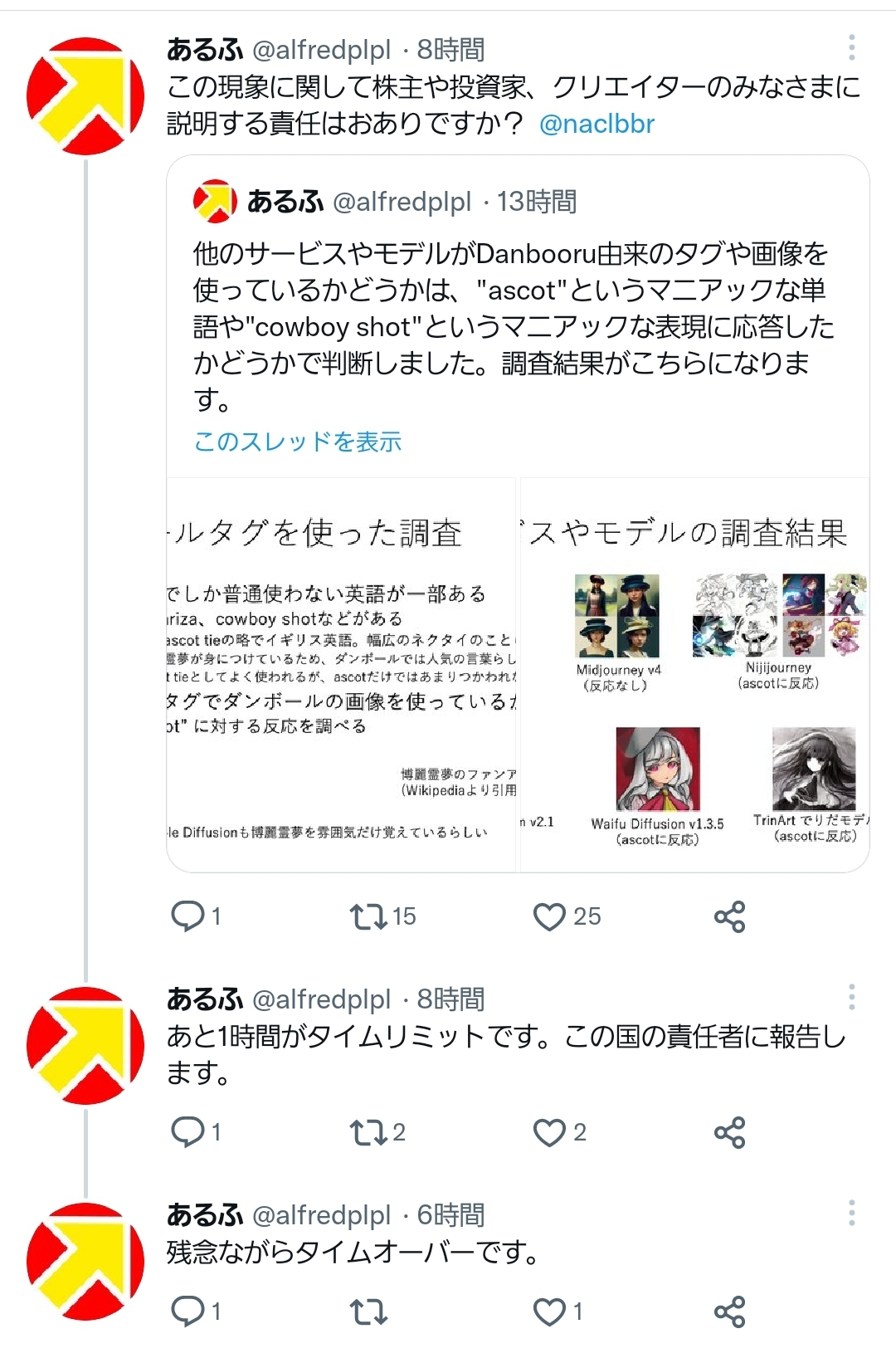
Lora
�����ʳؽ�ˡ��DreamBooth�Υ��ץ����Ȥ��ƻ��ѤǤ��롣
�ؽ���®����ɬ��VRAM�����ʤ����ե����륵������������(3MB����)�Τ���ħ��
�����VRAM 8GB�����������������HN��Ĥ��Ǥ˳�ȯ�ˤʤä���
������ץ���ץȾü�����
ȯü��https://fate.5ch.net/test/read.cgi/liveuranus/1670...
236����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (������������ Sa08-YHv1)2022/12/06(��) 11:50:24.42ID:oyNbIv5ha
�ץ���ץȤ϶����ͤ��뤫����¢�����ĤϽФ���
wiki�Υ������Ϣ���ĤΤޤˤ������ä��Ƥ���Ϫ����������
����̱��ư�ɤ����ä��������ߤϥ�����˥��ؤμ��ʤ�������ﳲ���ۤǤ��ä��Ȥ����Τ�ͭ����Ǥ��롣
528����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� f611-Znoa)2022/12/06(��) 20:31:38.66ID:AgAxETaY0
���236��(������������ Sa08-YHv1)oyNbIv5ha
���258��(������������ Sa08-YHv1)
���243,248��(�������� 9a61-R4o2)5gwb9arR0
����ä�õ����
�����Ҹˤ˥���������������˥���Ǩ��Ʃ���ޥ������ӥ����Ϫ����
���뤷������Ȼפ��Фɤ��ȤǤ�ʤ�Τ�ñȯ�ɣĥ�����������Ω����ä�
��꤯����Ƴڤ����ä�������
https://majinai.art/i/moQcFpU.webp https://majinai.art/i/Q5d5w62.webp
{kind=link}
{kind=link}
10�(NAI�֡�����)�ˤ��ä����Ƥ���̵���ʤäƤ�ߤ��������Ϥ����Ĥ����뤱�ɡ�
����ϥڡ������Ԥλ��Ȥ��˾ä�����äƤ뤫���Τ�ʤ��Τǡ�
���Ǥ�ͭ�������ʥΥ��ϥ�����äƤ�ͤϺƷǤ��Ƥ����Ȥ��꤬�����Ǥ���
������������web���������֤��̤�
���Ĥδ֤ˤ�����ϥ�������������Ⱦ�����뤳�ȤȤʤꡢ�������Ⱦ���ɲóؽ��ʤɥ�������Ǥ����Ǥ��ʤ����Ȥˤʤä������η��web�������ϸ��Ȥζ����פ��뤳�ȤȤʤꡢ������äƤ���Τ�ʬ����ʤ����Ȥ��ä���𤬤���ۤ�ȸ�����褦�ˤʤä���
�����ǤȤ�����ͳ�ˤ���ܥ���Ǥ���ʤ�JNVA����ʬΥ�����ʤ�JnovelAI����64�Ȥ������������Ѥ���web�������ѤΥ���ˤ��褦�Ȥ����ո��������夬�ä���
https://fate.5ch.net/test/read.cgi/liveuranus/1666...
955����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä� (�������� 9ff2-tmyp)2022/12/01(��) 12:50:32.04ID:ZEiSyf820
���������web�����ӥ��Ȥ�ʬ�����餤������㤦����
���η�̷��Ƥ�줿�Τ��ʤ�JnovelAI����65�Ǥ��롣
�������ƥ����ʬΥ������
�����Ƥʤ�JNVA���Ǥϥץ���ץȤθ���Ϥ��ʤ���餷���ΤǤ��ä���
����äȤ������饦�ɥ֡���
���֤�Dreambooth���פ�paperspace�����������ͤΥ����ߥ����߹�äơ�
�ؽ��饦�ɤǹԤ��֡��ब�����ä���
paperspace������ư���Ф������������ꡢ�桼�����������ƻȤ��ˤ����ʤä��ꡣ
WSL2��Ȥä�����®�٤�夲��ͥ���ФƤ��ơ������������δĶ���¿�Ͳ�������
2022-10-17 ���ޥ���Discord����+����������
162����451
���������аޤ����ä����饦�ޥ���Discord�������Twitter�ˤ��컯�����������Ф����������������ˤ��ƺ��ε�����Discord�����ޥ����ػߤ�Ω���夬�ä���䤱�� ����9��餤���餪��ʤ�ï�Ǥ�狼��Ȼפ��� wiki�����ˤ��줿�饬���Ǻ���
�̤Υ��ޥ���Discord��ɤä��ˤ�����
��������
- 11���???
- 2022/10/16 ��ڥ���Ĺ�ͥ���ȯ������� ����ˡŵ��ȯ�������Τؤ�
- 2022/10/15 �ޥ���������
- 2022/10/08 wiki����
wiki�Ĥ��äƤߤ���
����ư�ǥ��ץ��Υǡ�����ܤ��Ƥ�Ȥ���
https://seesaawiki.jp/nai_ch/
- 2022/10/04 1�����ܤ�Ω��
- 2022/10/03 NovelAI���������������ӥ���
- 2022/09/14 Waifu-Diffusion��˿�˥塼�������ȤǼ��夲����
- 2022/09/07 Stable Diffusion web UI(AUTOMATIC1111�ǡˤ�˿�˥塼�������ȤǼ��夲��������
- 2022/09/04 Stable Diffusion web UI��˿�˥塼�������ȤǼ��夲����
- 2022/08/23 reddiṯ�����饦�ɴĶ����������Ķ��Ǥ�NSFW�ե��륿�����뤳�Ȥ�ȯ����
- 2022/08 Stability.AI����Stable Diffusion�פ���̸���
���Υڡ����ؤΥ�����
�º�
��ʬ�ؽ��ʹߡ�����ʤ��礭���Ѳ��Ϥʤ���Τʤ���
������äƤ��鹹������ʤ��ʤä��Τʤ�Ǥ��Ȼפä���
FANBOX��AI�жػ��郎���������Ȥ�뵤̵���ʤä���ͳ�狼��䤹������
ñ������������������Ω���ʤ��ʤä����餸��ʤ��Ǥ�����
��������Ѥˡ�������Ƥ��륵���Ȥ�����ޤ���
ttps://www.sdcompendium.com/doku.php?id=start
���祤�饹�Ȥ�����
���Ū�Ƕ�Τ��ޤȤޤä������Ȥ�����ޤ���
ttps://rentry.org/niakonichan