Dreambooth-LoRA
�ǽ�������ID:1NhN+40vQg 2024ǯ05��11��(��) 17:50:04����
- ����
- ��������
- ���ͻ��������콻̱�ˤ��ؽ�������
- ���ȡ��롢��åȥ��å���
- GUI������ġ���
- �ؽ��Ѳ������֤��ե����������
- ����ץ���������դ���
- �ؽ��Ѳ����βù�
- ��§������
- �ؽ��μ�� sd-scripts (ľ�ܻ���)�ξ��
- �ؽ��μ�� LoRA_Easy_Training_Scripts�ξ��
- LoRA�μ����LyCORIS�ˤĤ���
- LoRA���̳ؽ�
- ���ԡ���LoRA�ؽ�ˡ
- Lora�λ�����ˡ
- LoRA�Υ�ǡ����α���/�Խ�
- LECO(Low-rank adaptation for Erasing COncepts)
- ��� / Tips
- ���������
���� 
Low-rank Adaptation for Fast Text-to-Image Diffusion Fine-tuning
��ñ�˸����С־ʥ���ǹ�®�˳ؽ��Ǥ������̤⾮�����ƺѤ��ɲóؽ�ˡ�ס�������ˡ�Ϥ����������롣
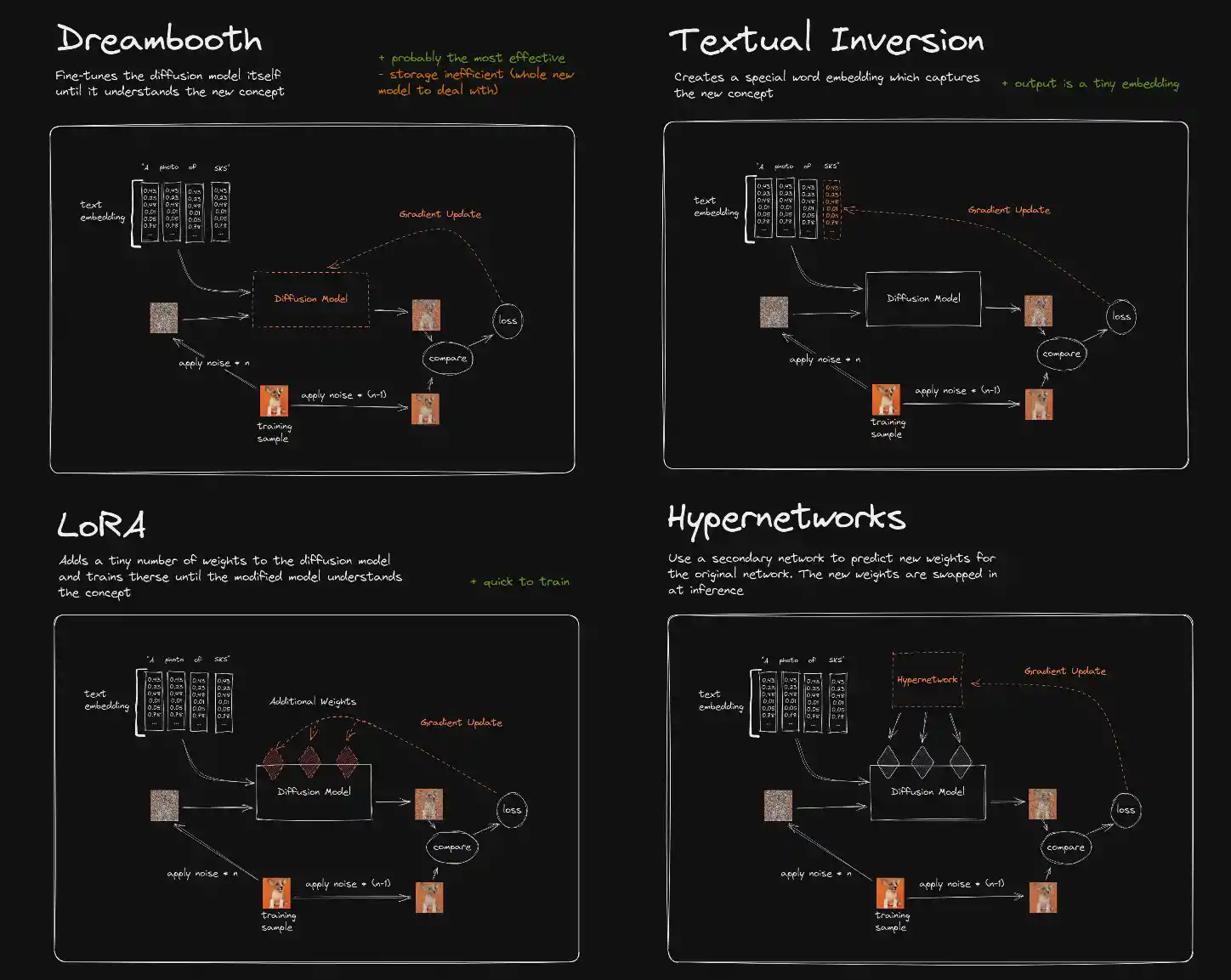
¾�γؽ�ˡ�Ȥɤ��㤦�ͤ�reddiṯ�ˤ��Ф���ʴ����Υ�����餷����
https://www.reddit.com/r/StableDiffusion/comments/...
kohya_ss��sd-scripts���о���衢sd-scripts�ڤӤ���������ġ��뤬�͵��ȤʤäƤ��롣
���Υڡ����Ǥ�sd-scripts��Ϣ�ξ���ˤĤ��ƻ��˽Ƥ��롣
�ڡ����ι������ۤȤ�ɤ���Ƥ��餺���Ť��ʤäƤ��뤳�Ȥ�α�ա�
���Υڡ�����Ȥ������������Υڡ����ΤۤȤ�ɤ�������ߤ��ᤷ��🥺
�����ξ����SD1.5�˴ؤ����Ρ���������SDXL�ξ����̵����
SDXL��Ϣ�ϥ��줫¾��Υڡ����ޤ��礦��
��ñ�˸����С־ʥ���ǹ�®�˳ؽ��Ǥ������̤⾮�����ƺѤ��ɲóؽ�ˡ�ס�������ˡ�Ϥ����������롣
¾�γؽ�ˡ�Ȥɤ��㤦�ͤ�reddiṯ�ˤ��Ф���ʴ����Υ�����餷����
https://www.reddit.com/r/StableDiffusion/comments/...
kohya_ss��sd-scripts���о���衢sd-scripts�ڤӤ���������ġ��뤬�͵��ȤʤäƤ��롣
���Υڡ����Ǥ�sd-scripts��Ϣ�ξ���ˤĤ��ƻ��˽Ƥ��롣
�ڡ����ι������ۤȤ�ɤ���Ƥ��餺���Ť��ʤäƤ��뤳�Ȥ�α�ա�
���Υڡ�����Ȥ������������Υڡ����ΤۤȤ�ɤ�������ߤ��ᤷ��🥺
�����ξ����SD1.5�˴ؤ����Ρ���������SDXL�ξ����̵����
SDXL��Ϣ�ϥ��줫¾��Υڡ����ޤ��礦��
��������
sd-scripts (kohya)
���֤Ϥ���Ϻ�Ԥ��ܤ����Ƥ���Ƥ������README�褦���äϤ��줫�����
- ������Ƴ����������https://github.com/kohya-ss/sd-scripts/blob/main/R...
- ������LoRA��������https://github.com/kohya-ss/sd-scripts/blob/main/d...
- �����ؽ��ǡ��������ɡ�https://github.com/kohya-ss/sd-scripts/blob/main/d...
- �������ޥ�ɥ饤�����ɽ��https://github.com/kohya-ss/sd-scripts/blob/main/d...
- ����DreamBooth�����ɡ�https://github.com/kohya-ss/sd-scripts/blob/main/d...
- ����Finetune�����ɡ�https://github.com/kohya-ss/sd-scripts/blob/main/d...
����
- LoRA�ؽ��ѥ���ץ�ǡ���
- https://note.com/kohya_ss/n/nb20c5187e15a
- ����ܿͤˤ�륵��ץ롣
- LoRA Training Guide
- https://rentry.org/lora_train
- 4chanͭ�֤ˤ��LoRA�ȥ졼�˥�ˡ�����ɡʱѸ��
- ��������LoRA������Ͽ
- https://rentry.co/irir_lora
- 512,768,1024�ΰ㤤����ʪ�������奨��������طʡ������Ȥ���������
- LoRA �ؽ����
- https://rentry.org/i5ynb
- ���콻̱�ˤ��Lain���褷�ʤ���������Ҥ���LoRA�����Ԥˤ��LoRA�����ɡ����ܸ��
������2023-03-15��"--caption_extension=.txt"�ΰ������ɲä�������Ū�˻��ꤷ�ʤ��ȥ����ե�����(.txt)���ɤߤˤ����ʤ����ͤ����մ������ɲä��ޤ�����
������2023-02-09���������ؽ�(NIKKE)����dim�ؽ�(��륭��� ����������)�ʤɤ��ɲä��ޤ�����
- �����������LoRA�κ�����Ͽ
- https://rentry.org/sourin_chan
- ���콻̱�ˤ��ޥ를��(�դ���ͭ�֤Υ����դ���ˡ��1��)�Ǻ�������LoRA������Ͽ�����ܸ��
- ����LoRA������⡦����
- https://rentry.org/genshin_lora
- ���콻̱�ˤ��kohya-ss�������SD������ץ�(https://github.com/kohya-ss/sd-scripts )�Ǽ��Υ�����LoRA������������ݥåץ��å��ǻ��ѡ������ܸ��
- ɮ�Ԥˤ���ɵ�:SD1.5����λ�Ժ������Ƥ������ξ���ǸŤ��ʤäƤ��ޤ������ͤˤ��ʤ��Ǥ���������
- ���콻̱�ˤ�륭��饯�����ؽ��Υ����դ���������ܸ��
- https://rentry.org/dsvqnd
- LAZY TRAINING GUIDE
- https://rentry.org/LazyTrainingGuide
- lora�äѤ���äƤ볤���˥�����Ψ9��ؽ�������
- ���������LoRA�Ρ��ȥ֥å�
- kohya_train_network_simple
- ��������˽���ʤ����ɤ��ʤ��˴�ĥ�äƤ���
- ���饦��GPU��Ȥ����ϥ����β������� Colab Instructions ������
- �ե����̿̾��ˡ�˵���Ĥ��ơ������Υե������Ⱦ�ѥ��ڡ�����������ʤ��褦�ˤ����̵��Colab�Ǥ�롣��ĥ�졣
���ȡ��롢��åȥ��å���
sd-scripts (��: kohya)
������sd-scripts�����ޥ�ɥץ���ץȤȤ��������̤˥��ޥ�ɤ��ǤäƻȤ���Ĥ�
- �ǿ���ǽ��Ȥ�����
- ���ꤷ��ư���Τ���
���ȡ���ϲ����ͤ�
- ������Ƴ����������https://github.com/kohya-ss/sd-scripts/blob/main/R...
GUI������ġ���
������sd-scripts��˻Ȥ���褦�ˤ�����Τ��
bmaltais��GUI��Kohya_lora_param_gui���������ᡣKohya_lora_param_gui�����ܸ�ǿ����߷פǻȤ��䤹����
bmaltais��GUI��Kohya_lora_param_gui���������ᡣKohya_lora_param_gui�����ܸ�ǿ����߷פǻȤ��䤹����
bmaltais�� GUI
https://github.com/bmaltais/kohya_ss
GUI �Ȥ��äƤ��Ԥ� sd-scripts �˥ѥ������Ϥ������䡣��ǽ���Ѥ����åȥ��åפ�����äȤ����ڡ�
GUI�Τۤ��������������٤��Τ���䤫��������Ƥ䡣
GUI �Ȥ��äƤ��Ԥ� sd-scripts �˥ѥ������Ϥ������䡣��ǽ���Ѥ����åȥ��åפ�����äȤ����ڡ�
GUI�Τۤ��������������٤��Τ���䤫��������Ƥ䡣
- Gradio�١�����GUI��
- ��Tools�ץ��֤˥ե�������������ǽ�����롣
- ������ץ��ǤΥѥ����ΰ������������ʤ����⡩
- ��ư�ϡ�powershell�ʤ�activate.ps1��gui-user.ps1����֤˸Ƥ֤Τ��ᤤ�ʼ�ư�ǥ֥饦����Ω���夬���
- ���åץǡ��Ȥ� upgrade.ps1 ��powershell�Ǽ¹�
Kohya_lora_param_gui (���콻̱��)
https://github.com/RedRayz/Kohya_lora_param_gui
https://github.com/kohya-ss/sd-scripts �γؽ��ѤΥѥ������ꤷ�ƥ��ޥ�ɥ饤����Ϥ�GUI�Ǥ���
https://github.com/kohya-ss/sd-scripts �γؽ��ѤΥѥ������ꤷ�ƥ��ޥ�ɥ饤����Ϥ�GUI�Ǥ���
- accelerate�¹Ի��Υ��ץ����ʰ����ˡ֥ѥ����������GUI�ǹԤ���褦�ˤ����פ�Ρ�
- ñ�Τ�sd-scripts�Υ��ȡ��롦�������Ǥ���褦�ˤʤä���
- LECO�γؽ���Ǥ��롣
- �Ȥ�����bat��lora_train_command_line������Խ����Ƥ��͡�accelerate�ΰ��������äƤ��ͤ˥������ᤫ�⡣GUI��ǿ��ͤȤ��Խ����Ƥ��Τޤ�accelerate���Ϥ�����Ľ�롣
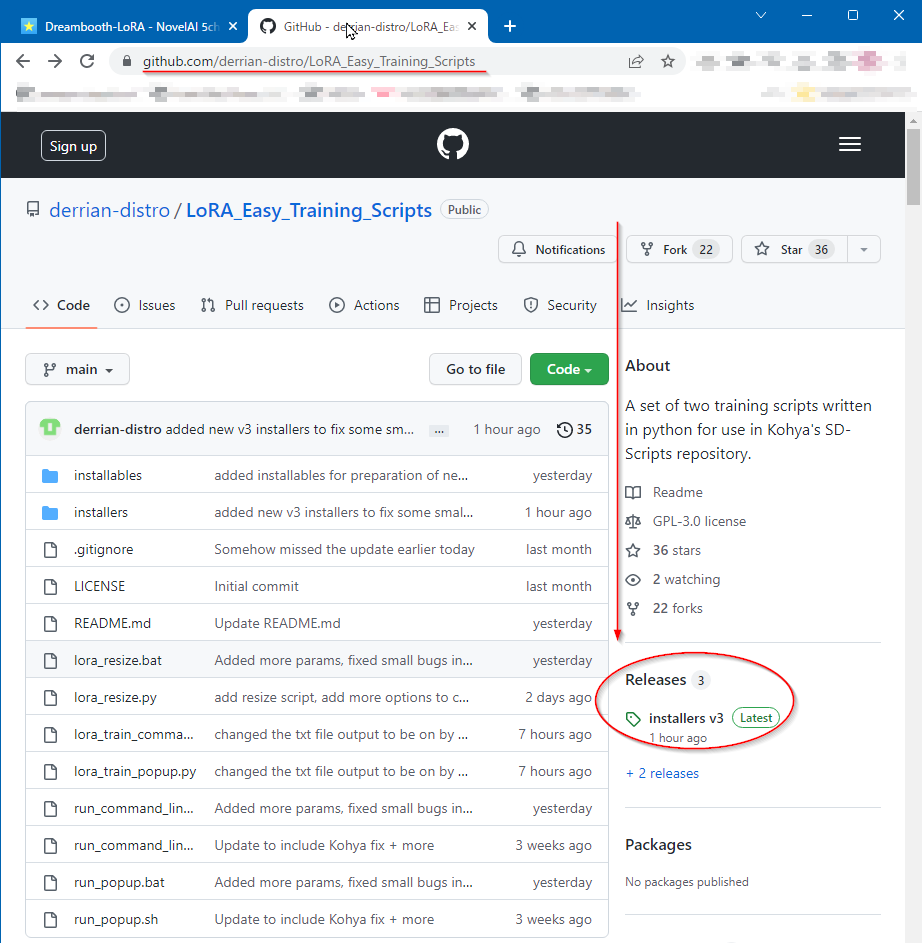
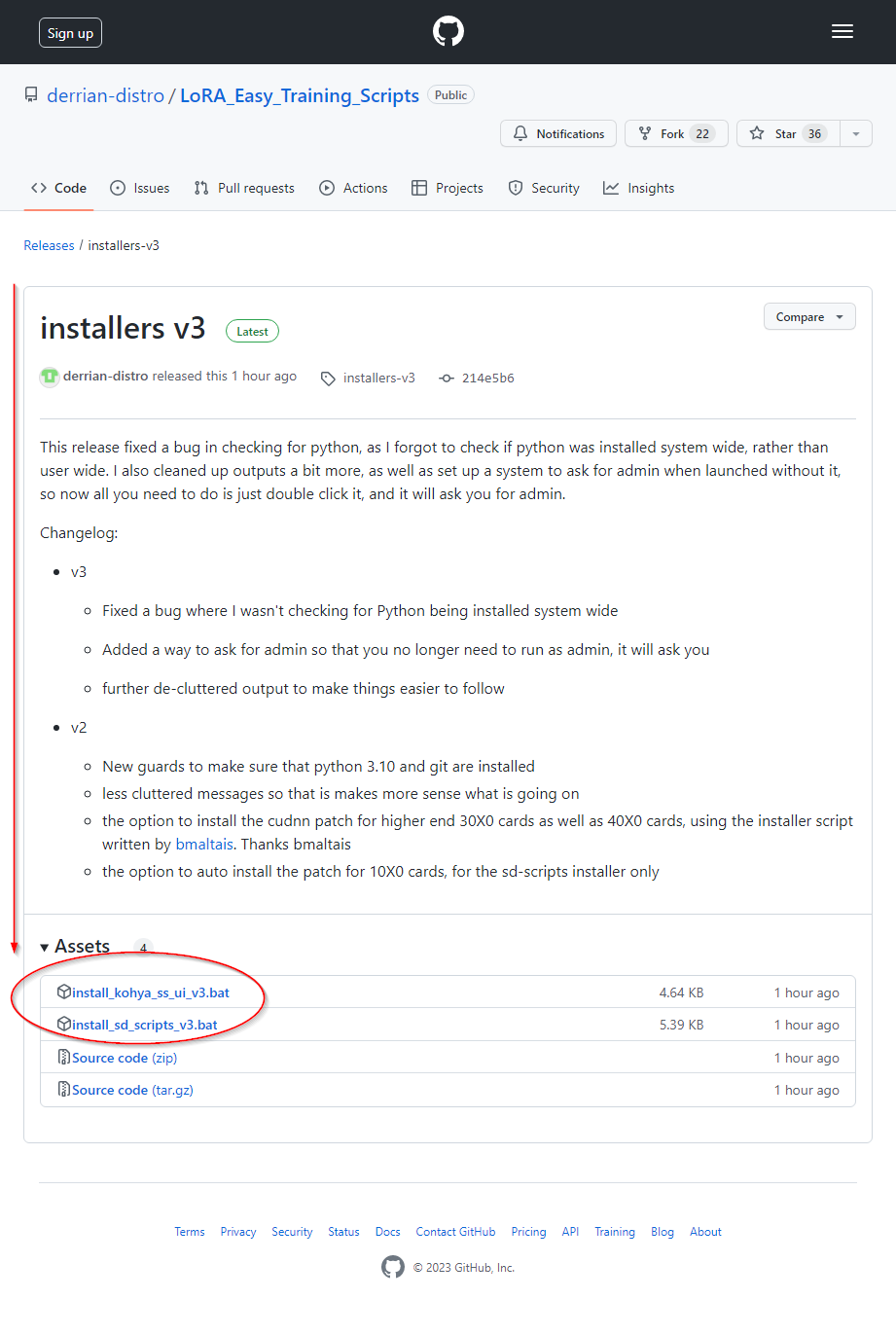
LoRA_Easy_Training_Scripts Installers
�ǽ�Ϥޤä���ʥե�����˥��ȡ��뤹�����
������å����ƴ����ԤȤ��Ƽ¹Ԥ���� sd-scripts ���Τ� Easy_Train_Scripts ��ξ���ȡ��뤷�ơ����ȡ����ν������ޤǤ�äƤ���롣
���ޤ������ʤ��ä��� Git�ȡ��� ���ƥ�ȥ饤
�狼��ʤ��Ȥ��Ѳ�����
 ���åץǡ��Ȥ�update.bat ����� upgrade.bat (�礭�ʥС�����åפΤȤ�������ľ��)
���åץǡ��Ȥ�update.bat ����� upgrade.bat (�礭�ʥС�����åפΤȤ�������ľ��)
- https://github.com/derrian-distro/LoRA_Easy_Traini...
- �����γؽ��μ��ǻȤ�EasyTrainScripts�οͤ���ä��ʰץ��ȡ��륹����ץ�
������å����ƴ����ԤȤ��Ƽ¹Ԥ���� sd-scripts ���Τ� Easy_Train_Scripts ��ξ���ȡ��뤷�ơ����ȡ����ν������ޤǤ�äƤ���롣
���ޤ������ʤ��ä��� Git�ȡ��� ���ƥ�ȥ饤
�狼��ʤ��Ȥ��Ѳ�����
���������Lora���ȡ��顼
��������ȡ��顼��1111�����줿������PYTHON��GIT��PATH���äƤ�����
start.bat��Ʊ���ե����������Ƽ¹Ԥ��Ƥ�������
start.bat��Ʊ���ե����������Ƽ¹Ԥ��Ƥ�������
- ���ޥ�ɥ饤����
- ������������(�ߤ���)
AUTOMATIC1111 SD WebUI ��ĥ��ǽ�� (��: ddPn08 GUI) ���������
��ǯ��ϻ���Ǹ�˹�������ߤ��Ƥ��ޤ������ߤ�ư��뤫�������Ǥ���
sd-webui-train-tools
https://github.com/liasece/sd-webui-train-tools
AUTOMATIC1111 SD WebUI �Ѥ� ��ĥ��ǽ
������ɥ��åפ��ƥѥ��������褯����Ƚ���롣��ñ
ư����Ȥ����̤�WebUI�åȥ��åפ��Ƴؽ����Ѥˤ����ۤ���������
ReadME������ʤΤ�google������ĥ���ʤ�
�������٤��㤯�ǿ��ε�ǽ�ϻȤ��ʤ�
AUTOMATIC1111 SD WebUI �Ѥ� ��ĥ��ǽ
������ɥ��åפ��ƥѥ��������褯����Ƚ���롣��ñ
ư����Ȥ����̤�WebUI�åȥ��åפ��Ƴؽ����Ѥˤ����ۤ���������
ReadME������ʤΤ�google������ĥ���ʤ�
�������٤��㤯�ǿ��ε�ǽ�ϻȤ��ʤ�
����¾���������ץ�
�Ȥ�����bat��4chan���Υ�����ץȤ�����
���åץǡ��Ȥ�
���åץǡ��Ȥ�
���饦��
���������Lora�Ρ��ȥ֥å�
�����˥���jupyter notebook
��Τ߾Ҳ𡣤������ٺǿ��Ǥ��äƤ���Τ�ư���ʤ��Ƥ�㤫�ʤ���
https://github.com/Linaqruf/kohya-trainer
�����˥���jupyter notebook
��Τ߾Ҳ𡣤������ٺǿ��Ǥ��äƤ���Τ�ư���ʤ��Ƥ�㤫�ʤ���
https://github.com/Linaqruf/kohya-trainer
�ؽ��Ѳ������֤��ե����������
sd-scripts �� --dataset_config ������ե�������Ϥ����ϰۤʤ�
https://github.com/kohya-ss/sd-scripts/blob/main/c... ���ɤ��
https://github.com/kohya-ss/sd-scripts/blob/main/c... ���ɤ��
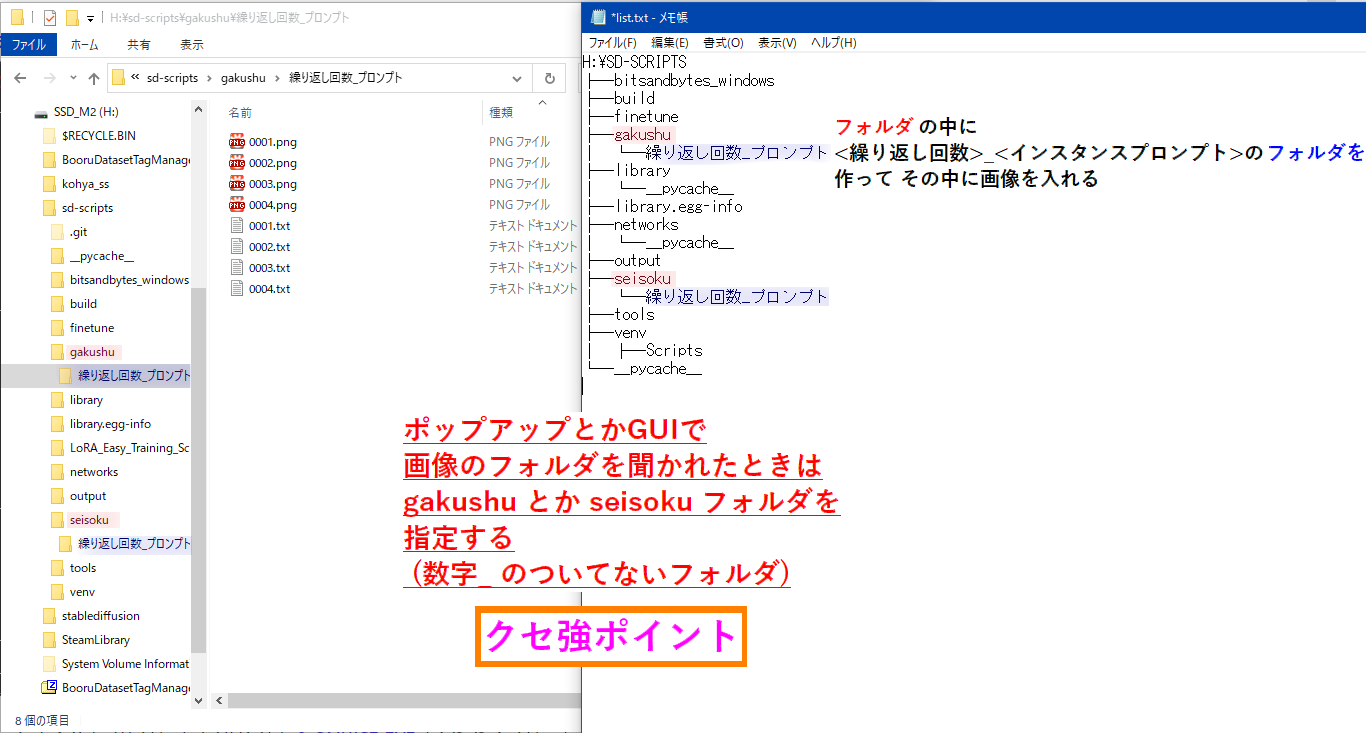
- ��Ԥβ��⤬�ܤ���
- �ե������������:
���פ����<�����֤����>_<�����ץ���ץ�>�˥�͡��ष���ؽ������ǡ����Υե������ľ�ܻ��ꤷ�ʤ��Ǥͤä���
�㤨�Т�������������
❌E:\kohya_ss\TrainDatas\001\img\40_kdy 1girl
🟢E:\kohya_ss\TrainDatas\001\img
�ְ㤦�Ȳ��������Ĥ���ޤ�����ܤ���
�㤨�Т�������������
❌E:\kohya_ss\TrainDatas\001\img\40_kdy 1girl
🟢E:\kohya_ss\TrainDatas\001\img
�ְ㤦�Ȳ��������Ĥ���ޤ�����ܤ���
- Ʊ����10�ޤdz�ǰ��ؽ��Ǥ��뤬�����ʤ��Ȥ�1�Ĥϥե������ɬ�ס�
- �ե������̾���� <�����֤����>_<�����ץ���ץ�>
- <�����֤����> �����֤�����߳ؽ��Ѳ����������1���å�(1 epoch)�Ȥ��Ƴؽ�����
- <�����ץ���ץ�> ���饹 �ƤӽФ��ѤΥ������ ���饹����ñ��ˤʤ���̣�Τʤ�������褤
- �嵭kohya��Υ���ץ���ȡ�20_sls frog�ס�Ǿ��ǿ�������ʤ� �����֤����_��̣�Τʤ���� WEBUI�ǥץ���ץȤȤ��ƽ���ñ�� �����ꤷ�Ƥ���
- ����ץ���� �ե������ɬ�ܤǤ��������Ǥʤ���硢LoRA �ϳ�ǰ̾��ץ����Ȥ��ƻ��Ѥ��ƥȥ졼�˥�Ԥ��ޤ���
- ����ץ����ˤĤ��Ƥϰʲ�
����ץ���������դ���
- ��Ԥξܤ��������դ�����
- https://github.com/kohya-ss/sd-scripts/blob/main/d...
- �ؽ��Ѥ��Ǻ�������줾������Ƥ���������ƥ����ȥե�������롣���Υƥ����ȥե�����ˤϲ����������Υץ���ץȤ�Ʊ���褦�˥����ܤ��롣
- �ƥ����ȥ��ǥ���������Ģ��1�Ĥ��ĺ�äƤ��ɤ��Τ�����WD1.4 Tagger ���Υġ����Ȥ��а쵤�˼�ư�����Ǥ���Ľ��
WD1.4 Tagger�Ǻ���
��˳ؽ��Ѳ�����Ϣ�֤˥�͡��ष�Ƥ��� (01.png, 02.png, ...�ʤ�)
Web UI �˳�ĥ��ǽ stable-diffusion-webui-wd14-tagger https://github.com/toriato/stable-diffusion-webui-...�ȡ���
��Tagger�ץ��֤Ρ�Batch from directory��
Interrogate���ȳؽ��Ѳ����Υե�����˥������դ��� .txt �ե����뤬���������
����
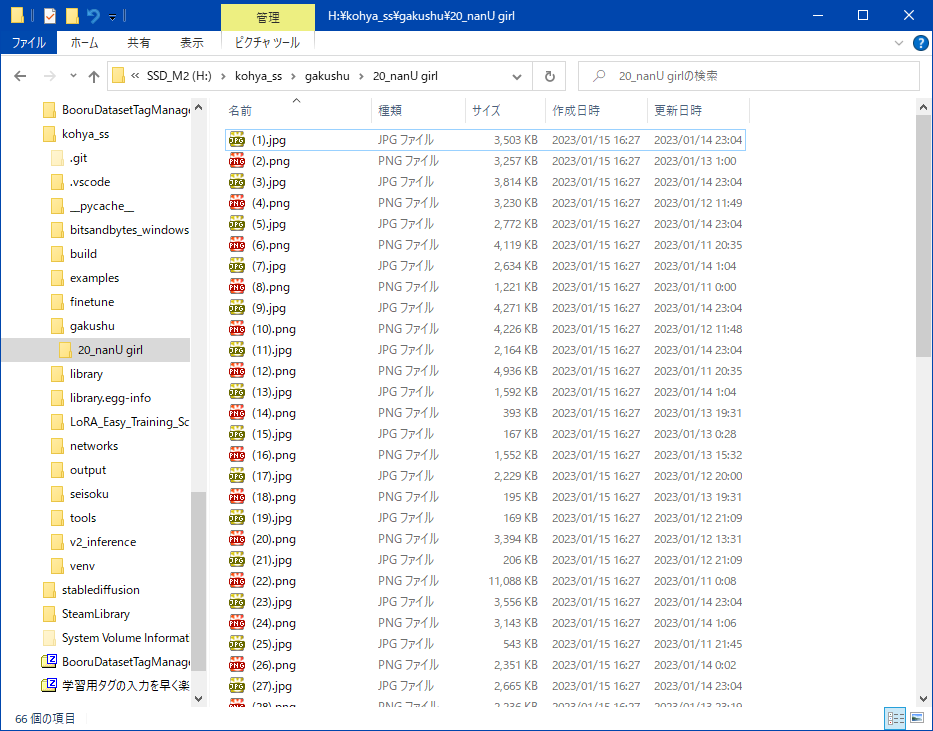
��Tagger�ץ��֤Ρ�Batch from directory��
- ���ϥե�����:�ؽ��Ѳ��������äƤ���ե����
- Interrogator:wd-14convnext
- �������������������˥��ڡ�������Ѥ���:����
- ��̤������פ���:����
����
����
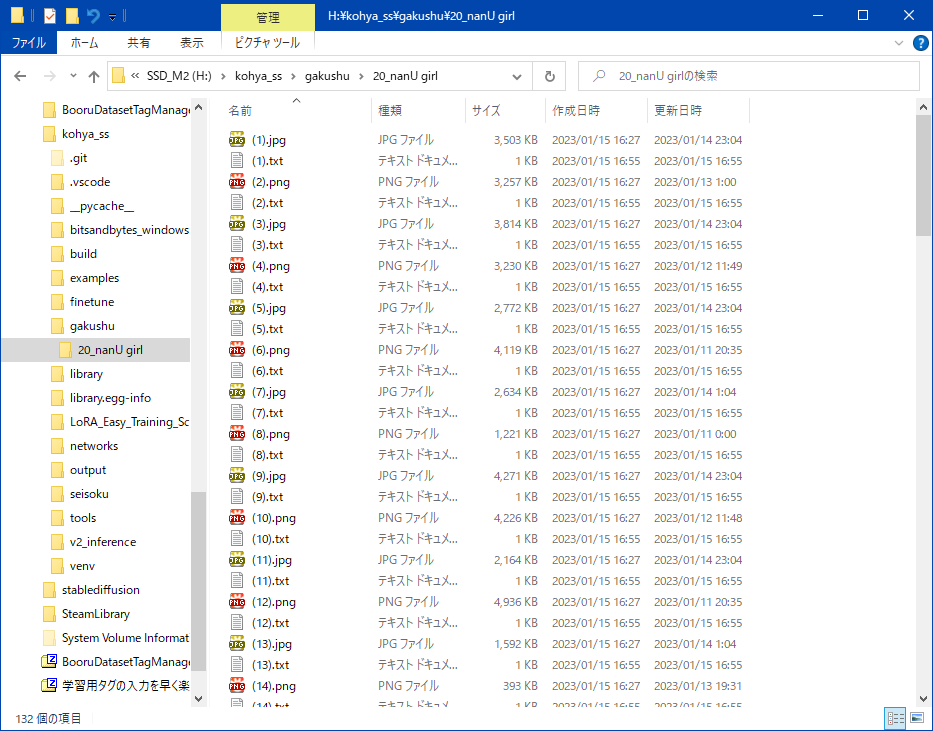
Dataset Tag Editor�Ǻ���/�Խ�
���֤�Ȥ��������Ĥ��ä���ġ����֥ǥ��쥯�ȥ�ޤ��ɤ�ǰ��ǥ����դ������ꡢ�����Ф��ʤ��Ŭ�˥����դ��Ǥ��롣
�����դ�
- �ޤ��ե�������ꤷ��Load �ʤ�����2�ĥ����å���Overwrite����Interrogators�ߤΤ������
- Interrogator Settings�β������ͥ����å���������Load�Dz����ɤ߹��ߤ�
- �ۤ�Dz����ɤ߹��ߤ�Ʊ���˥������������������Ȥ뤫�齪��ä��鼡�ϱ���Υ���File by Selection�Ǥɤβ�����Ŭ�Ѥ��뤫�����
- �Ȥꤢ��������Add ALL Displayed�Ǥ��٤Ƥβ������Ʋ���Apply selection filter��Ŭ�Ѥ��ƺǸ�˺����Save all change�Ǥ��٤�Ŭ�Ѥ�
����000�ե����뤬�ФƤ���Τ��Խ����Υƥ����ȥե�����ΥХå����åפ�
����ץ���������Խ�
- �����Ͻ���˱ƶ��������Τǡ����ֺǽ��ͭ���������������Ҥ���
- WD1.4Tagger���Ǽ�ư���������ե�����ˤ����פʥ������ޤޤ줿���ǧ�����줿���������ܤ��줿�ꤹ��Τ��Խ����롣
- BooruDatasetTagManager
- https://github.com/starik222/BooruDatasetTagManage...
- �ؽ��ѥ��������Ϥ�®���ڤˤ�����
- ����������Ρ֥ġ���� https://uploader.cc/s/rdw0k6qd2766czgdwwwjtn2xtmhi...
- WebUI�ѳ�ĥ��ǽ Dataset Tag Editor
- https://github.com/toshiaki1729/stable-diffusion-w... ���ܸ�README�˻Ȥ������Ƥ���
- tagger���������������ν���ΤޤޤǤ��ʤ��������פʥ��������ƥե��������Ƭ�����˵��ܤ��롣�㤨�Х��ޥ�ɥ饤���ǡ�lora_train_command_line.py�ˤξ�硢
self.shuffle_captions: bool = True # OPTIONAL, False to ignore ~~
self.keep_tokens: Union[int, None] = 3 # OPTIONAL, None to ignore ~~
�嵭�Τ褦�����ꤹ�����Ƭ����3�ĤΥ����Ͻ������Ȥ��ƻĤ�ϥ�����Ŭ���˥���åե뤷�Ƴؽ��Ǥ��롣- Dataset Tag Editor��Ȥä���ñ��������ˡ
��2.Dataset Tag Editor��Batch Edit Captions�����������Remove������
��3.�����Ф������봰�������פʥ�������������롣
��4.�ؽ���������Ӥ�����ह�륿������ٺ�����롣
��5.Remove����Edit tags�ع��ܤ��ư��Common Tags�����ˤ�Edit Tags�˳ؽ������ܡ�
��6.Prepend additional tags�˥����å��������Apply Changes to filtered images������
�����Τ褦�˺�Ȥ���ФɤΥե������ؽ���������Ƭ�˻��äƤ����Ƥ�����֤Ǥ��뤿�ᡢ�����˳ؽ����Ƥ��Ϣ�դ����䤹���ʤ롣
����ץ������դ������ͤ����λ��ͥ�����
- lora training tagging faq
- �Ѹ쥵���Ȥ����֥饦�����������ɤ⤦
- ����饯�����ؽ��Υ����դ�����
- �����Ƥβ���
- LoRA����ץ�����Խ�����
- ��̱��֥��������LoRA�Υ����դ������
- Danbooru�����ˤʤ�1�ȡ�����Υ�ɰ���
- �����ɥ�����ȤǸ��ڤ���Ƥ����tokinizer��1�ȡ�����ˤʤ�3ʸ���ʲ��ǥ쥢��ñ��פ�Ȥ���������ͭ��
�ؽ��Ѳ����βù�
- ��ʸ���������Ƥ��� kohya �Ǥ�LoRA�Ǥϥȥ�ߥϤ��ʤ��Ƥ���(�����Υ������̤˳ؽ����Ԥ���)
- ���ޤ�ˤ⾮��������(200px�Ȥ�)��Upscayl�ʤɤdz��礷�Ƥ����� bucket_no_upscale ��ˤ���
- �طʤ��ڤ�ȴ���ϲ������礭����·���Ʋ����Υġ���Ǥ��ȳڡ�
- �ڤ�ȴ�������طʿ��ˤĤ��� (�ޤꤿ����)




- �������ڤ�Ф�������ä���3D�ڥ����(Win10�ʤ�ɸ�ࡢ11�Ǥ�ɸ�फ��ꥹ�ȥ餵�줿���ɥ��ȥ��ˤ����)�Υޥ��å�����Ǥ����������ڤ�ȴ���䤹�����餽������gimp�ʤ����Ĵ����
- ���������Τ��ɤ������������ä���ABG_extension�����Τ��Ф���ǤĤ��Ƥߤ��館����Ȥ��㤦���ʡġ������
- ABG_extension
- https://github.com/KutsuyaYuki/ABG_extension
WebUI��extension��anime-segmentation �� 1111 �ǻȤ���褦�ˤ�����ġ��������طʤ�Ʃ�ᤷ�������طʤˤ�����ޥ�����������Ϥ���
- stable-diffusion-webui-rembg
- https://github.com/AUTOMATIC1111/stable-diffusion-...
u2net_human_seg �����꤬���礦���ɤ���
- �ڤ�ȴ���Υ�������ġ���
- https://12.gigafile.nu/0629-bc2ae51e82ab361567d60e...
- Lama-Cleaner
- https://github.com/Sanster/lama-cleaner
WebUI��extension�⤢�� Extensions_URL
��§������
LoRA�����Ӥ�ͤ���ȴ���Ū�����ס��ʤ���Ʃ����§���θ��̤�̵���Ȼפ��롣
- ChatGPT����۩���ֲ�ؽ����ޤ��뤿��Τ�Ρ�
- ����ץ����Ĥ����餽�Υץ���ץȤdzؽ��������ǥ��Ȥä�(Ŭ���ʥͥ��ƥ��֥ץ���ץȤ�Ĥ���)��������Ф����������Τ����ܤ����Ϥ狼��ʤ��Τ�ï���ƥ�����
- ��Ļ�õ���Υ���������פ�Ф�����������̤Υ������˺��ƽʤ��ʤ�Τ��ɤ�����˳ؽ��������̤Υ�����β������Ϥ��Ƥ���������
- ¾��ΥΡ��ȥ֥å������Ѥ��Ƥ���ΤdzΤ��ʻ��ϸ����ʤ�������§��������Ʊ���褦�ʲ����dzؽ��������������§�������ˤĤ������饹�ȡ��������§�����������Ƥ���������褦�ˤʤ롣ñ�ˡֳؽ���������§��������ĤȤ�ؽ�����פȤ�����ư�Τ褦�˻פ��롣
��§���������� (����å�����Ÿ��)


Ʃ����PNG����§�������ˤ���
Ʃ����§���ϸ��̤��ǧ�Ǥ��ʤ����ᡢ���ɬ�����Ϥʤ����������Ի����⡣
Web UI �˳�ĥ��ǽ Generate-TransparentIMG �ȡ��뤹��
https://github.com/hunyaramoke/Generate-Transparen...
Generate TransparentIMG ���֤ǡ��ֽ��ϥե�����פˤ���§����������¸���number_of_generation�פˤϺ���������������Ϥ��Ƽ¹�
Web UI �˳�ĥ��ǽ Generate-TransparentIMG �ȡ��뤹��
https://github.com/hunyaramoke/Generate-Transparen...
Generate TransparentIMG ���֤ǡ��ֽ��ϥե�����פˤ���§����������¸���number_of_generation�פˤϺ���������������Ϥ��Ƽ¹�
����
�ؽ��μ�� sd-scripts (ľ�ܻ���)�ξ��
�ʲ��ϰ���(Optimizer��AdamW8bit��Ȥä�������)
venv��activate ����
��Ĺ���ΤDz��Ԥ��Ƥ��뤬�����Ԥ��ä����Ƥ�1�Ԥǽ�����
�⤷���Ϲ����� ^ ������դ���� ^ľ��β��Ԥ�̵�뤵�졢ʣ���Ԥ�ʬ�����ޤ����ϤǤ���
venv��activate ����
.\venv\Scripts\activateaccelerate launch �ιԤ����Ϥ��Ƽ¹�
��Ĺ���ΤDz��Ԥ��Ƥ��뤬�����Ԥ��ä����Ƥ�1�Ԥǽ�����
�⤷���Ϲ����� ^ ������դ���� ^ľ��β��Ԥ�̵�뤵�졢ʣ���Ԥ�ʬ�����ޤ����ϤǤ���
accelerate launch --num_cpu_threads_per_process 1 train_network.py --pretrained_model_name_or_path=D:\stable-diffusion-webui\models\Stable-diffusion\model.safetensors --train_data_dir=D:\sd-scripts\training --output_dir=D:\sd-scripts\outputs --reg_data_dir=D:\sd-scripts\seisoku --resolution=512,512 --save_model_as=safetensors --clip_skip=2 --seed=42 --color_aug --min_bucket_reso=320 --max_bucket_reso=1024 --lr_scheduler=cosine_with_restarts --lr_warmup_steps=500 --keep_tokens=1 --shuffle_caption --enable_bucket --mixed_precision=fp16 --xformers --lr_scheduler_num_cycles=4 --caption_extension=.txt --persistent_data_loader_workers --bucket_no_upscale --caption_dropout_rate=0.05 --optimizer_type=AdamW8bit --learning_rate=1e-4 --network_module=networks.lora --network_dim=128 --network_alpha=64 --max_train_epochs=10 --save_every_n_epochs=1 --train_batch_size=2
- ���Ģ�ʤɤ˥��ԥڤ���
- ɬ����ʬ�������
- �Ǹ�˲��Ԥ��ä�1�Ԥˤ���
- �����ߥʥ�(Powershell��)��Ž���դ���
- �¹�
- ���Ģ����¸���Ƥ����м��饳�ԥڤǻȤ���
����
- .txt��ĥ�ҤΥ����ե�������ɤޤ���
--caption_extension=.txt�ʤ��ؽ�����LoRA�������ե�������ɤ�Ǥ��뤫�ϡ�Aditional network��ĥ��ǽ��WEBUI�˥��ȡ��뤷�ơ�Trainning info�Υȥ�����ƥ����ꥹ�Ȥ�̵ͭ��Ƚ�̤Ǥ��롣
�ܤ�����LoRA�Υ�ǡ����α���/�Խ������
- 'Triton'���顼
A matching Triton is not available, some optimizations will not be enabled.
Error caught was: No module named 'Triton'
�ؽ��μ�� LoRA_Easy_Training_Scripts�ξ��
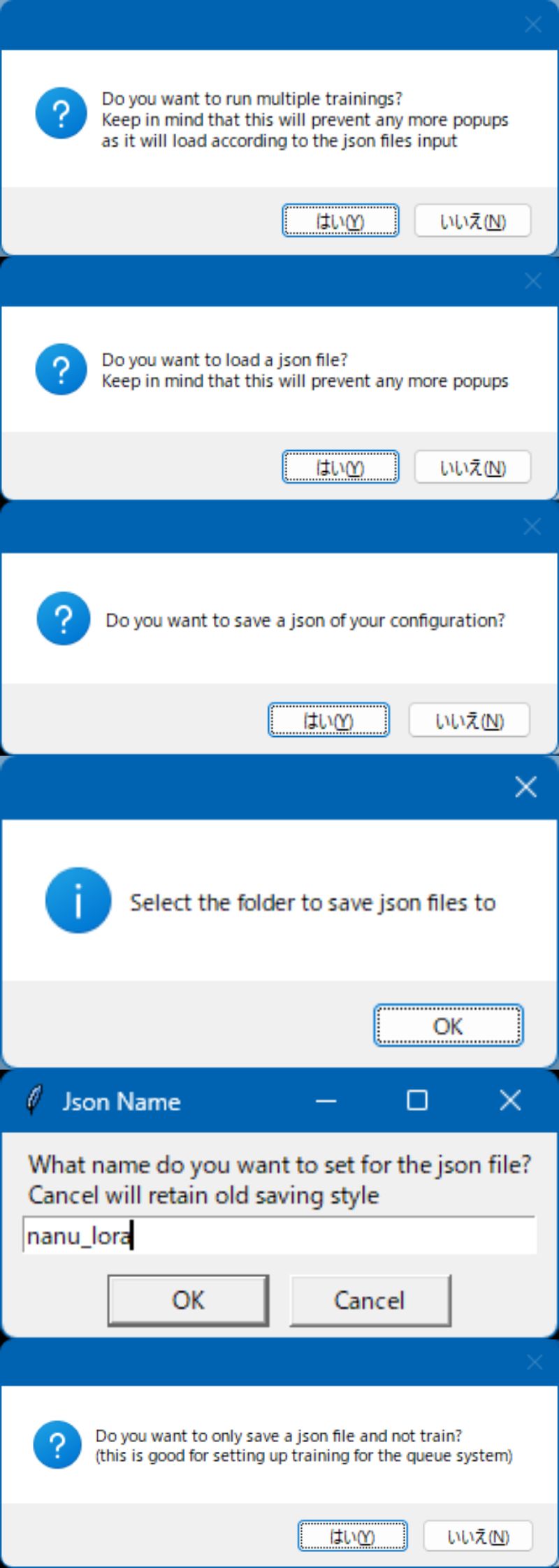
�ݥåץ��å��Ǥ�Ȥ����
- run_popup.bat��¹�
- �ݥåץ��åפ˥ѥ�������缡���Ϥ���
- ����夬����Ԥ�
LoRA_Easy_Training_Scripts �ݥåץ��å��Ǥμ����� �������� (2023-04-02����)
����å�����Ÿ�� ���åץǡ��Ȥʤɤ����Ƥ��Ѥ��
�狼���ѥ������Ф���cancel���Ȥ��Хǥե�����ͤ����롣
�Ѹ줬�狼���Ȥ��ϥ������åȻ��äƥ����ʹ���ƥ�����ư�����Ȥ��Ĥʤ�ï���狼������
ư��(2023-03-04) �����˥��ץǤ����Ω���ʤ��ʤ뤬��� 2���֤ǥ��ߤˤʤ�ޤ�����
�狼���ѥ����� �����ǥǥե�����ͤ�����
���濴�����˥��ϥ��ޥ�ɥ饤��������ɤ�Ȥ����� lora_train_command_line.py
�狼���ѥ������Ф���cancel���Ȥ��Хǥե�����ͤ����롣
�Ѹ줬�狼���Ȥ��ϥ������åȻ��äƥ����ʹ���ƥ�����ư�����Ȥ��Ĥʤ�ï���狼������

�狼���ѥ����� �����ǥǥե�����ͤ�����
���ޥ�ɥ饤���Ǥ�Ȥ����
- ArgsList.py�˥ѥ��������
��������Τ�ArgsList.py�κǽ���������ꡣ�ؽ��١����ˤʤ��ǥ롢�ؽ��Ǻ�ե�����ξ�ꡢ�������ɬ�����ꤹ�롣�狼���Ȥ����Ϥ��Τޤޤˤ��Ȥ���
��ˡ�ϰʲ��ͤˡ�ʸ����(str)�� r"c:\hogehoge"���Τ褦�����ϡ�����(float,int)�Ϥ��Τޤ��ͤ����ϡ�False�ȤʤäƤ�����ʬ��True��ͭ���ˤʤ롣
�ʲ�ArgsList.py�����ܸ���
- run_command_line.bat��¹�
- ����夬����Ԥ�
���ץƥ��ޥ�����
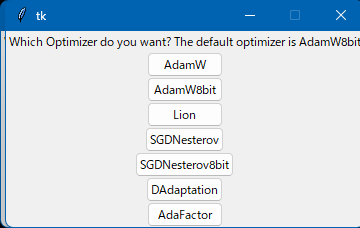
Adafactor
������ưOptimizer��AdamW�������«���٤����Ϥä�����ä�LoRA�ǤϻȤ����ͤϤʤ���LoRA���Finetuning�ʤɤ��絬�ϳؽ��˸����Ƥ��롣
Ad�ʤ�Ȥ���ȤäƳؽ����Ƥߤ���ʤ��ؽ����Ƥʤ��Τ��Ǥ����ᤷ���ä��Τǡ�����ǥޡ������Ƥ�������Τ�Ͽ���Ƥ����ޤ�������å�����Ÿ��
Ad�ʤ�Ȥ���ȤäƳؽ����Ƥߤ���ʤ��ؽ����Ƥʤ��Τ��Ǥ����ᤷ���ä��Τǡ�����ǥޡ������Ƥ�������Τ�Ͽ���Ƥ����ޤ�������å�����Ÿ��
2023/02/22�������Adafactor��������









LoRA�μ����LyCORIS�ˤĤ���
LyCORIS�ˤĤ���
https://github.com/KohakuBlueleaf/LyCORIS
LoRA�ο������ؽ���ˡ��ޤȤ��ݥ��ȥꡣ�̾��LoRA�����ǽ���������⤷��ʤ�����®��(it/s)���٤���
��Ȥ��LoCon�Τߤ��ä������Τ��˿��������르�ꥺ����ɲä���LyCORIS�����礵�줿��
https://github.com/KohakuBlueleaf/LyCORIS
LoRA�ο������ؽ���ˡ��ޤȤ��ݥ��ȥꡣ�̾��LoRA�����ǽ���������⤷��ʤ�����®��(it/s)���٤���
��Ȥ��LoCon�Τߤ��ä������Τ��˿��������르�ꥺ����ɲä���LyCORIS�����礵�줿��
LyCORIS �Υ��ȡ���Ȼ�����ˡ
sd-scripts��venv��
�ؽ����˻��Ѥ���ˤ�network_module�� lycoris.kohya ����ꤹ�롣
�����Ͽ��ͤ�����
�������
ɸ���Extra Networks�����kohya-ss�������sd-webui-addtional-networks�ǻ��ѤǤ��롣
pip install lycoris_lora�ǥ��ȡ��뤹�뤳�Ȥǻ��Ѳ�ǽ��
�ؽ����˻��Ѥ���ˤ�network_module�� lycoris.kohya ����ꤹ�롣
python3 sd-scripts/train_network.py --network_module lycoris.kohya --network_dim ���� --network_alpha ���� --network_args "conv_dim=����" "conv_alpha=����" "dropout=����" "algo=lora"����1�Ԥ����Ϥ����
�����Ͽ��ͤ�����
�������
--network_module lycoris.kohya --network_dim 64 --network_alpha 32 --network_args "conv_dim=64" "conv_alpha=32" "dropout=0.05" "algo=lora"�����ǻ��Ѥ���ˤ�1111��Extension��a1111-sd-webui-locon������a1111-sd-webui-lycoris�Υ��ȡ��뤬ɬ�ס�
ɸ���Extra Networks�����kohya-ss�������sd-webui-addtional-networks�ǻ��ѤǤ��롣
LoRA���
LoRA�Ϥ��μ���ˤ�äơ����Τ褦��ʬ������
| NO | LoRA�μ��� | LoRA��̾�� | ���ѥͥåȥ���⥸�塼�� (network_module) | ���ѥѥ��� (network_args) | ��ǥ�ޡ��� | ���� |
| �� | LoRA | LierLa/�ꥨ�� (kohya��LoRA) | networks.lora | (�ʤ�) | �� kohya�ǥޡ���������ץȻ��� | �����ΰ�̣�Ǥ�LoRA�Ǥ��줬�縵 |
| �� | LoCon | ����LoCon | locon.locon_kohya | network_args 'conv_dim=XXX' 'conv_alpha=XXX' | �� LyCORIS�ǥޡ���������ץȻ��� | LierLa���ĥ��������LoCon LyCORIS�ˤʤ����˥������줿ʪ |
| �� | C3Lier/���ꥢ (kohya��LoCon) | networks.lora | network_args 'conv_dim=XXX' 'conv_alpha=XXX' | �� kohya�ǥޡ���������ץȻ��� | kohya��LoCon | |
| �� | LyCORIS��LoCon | lycoris.kohya | network_args 'conv_dim=XXX' 'conv_alpha=XXX' 'algo=lora' ���� network_args 'conv_dim=XXX' 'conv_alpha=XXX' 'algo=locon' | �� LyCORIS�ǥޡ���������ץȻ��� 'disable_conv_cp=True' �Ǻ���������Τϥޡ����Բ� | LyCORIS��LoCon | |
| �� | ����¾LyCORIS | LoHa | lycoris.kohya | network_args 'conv_dim=XXX' 'conv_alpha=XXX' 'algo=loha' | �� LyCORIS�ǥޡ���������ץȻ��� | ���̤�������� |
| �� | (IA)^3 | lycoris.kohya | network_args 'conv_dim=XXX' 'conv_alpha=XXX' 'algo=ia3' | �� LyCORIS�ǥޡ���������ץȻ��� | ||
| �� | LoKR | lycoris.kohya | network_args 'conv_dim=XXX' 'conv_alpha=XXX' 'algo=lokr' | �� LyCORIS�ǥޡ���������ץȻ��� | ||
| �� | DyLoRA | lycoris.kohya | network_args 'conv_dim=XXX' 'conv_alpha=XXX' 'algo=dylora' |
��������������λ�����ˡ�����extensions
| 🎴����(�ץ���ץȻ���) | ɬ��extensions | �б�LoRA | TEnc/UNet���θ��̥ѥ������� | ����LoRA | ɸ��Υե���������ե���� (�ѹ��ϲ�ǽ) | ���� |
| <lora:> | (̵��) | LoRA(��) LoCon(��,��,��) LyCORIS(��,��,��,��) | �Բ�(���ζ��ٻ���Τ�) | �� | models\LoRA | 1111ɸ�ൡǽ����� v1.5.0�ʹߤ�LyCORIS�ˤ��б� |
| <lyco:> | a1111-sd-webui-lycoris | LoRA(��) LoCon(��,��,��) LyCORIS(��,��,��,��) | �� | �� (����λ���������) | models\LyCORIS | v1.5.0����ɸ�ൡǽ����������뤿�ᡢ����Ū�˻Ȥ�ɬ�פ�̵���ʤä� a1111-sd-webui-locon�ε�ǽ�����Ǥ�LyCORIS�������르�ꥺ����б� 🎴�ܥ����LyCORIS���֤������˽��衢<lora:>��Ʊ���褦�˼�ư���Ͻ���� �ե�������֤����� |
| �ץ���ץȻ���ʤ� | Additional Networks | LoRA(��) LoCon(��,��,��) | �� | �Բ� | extensions\sd-webui-additional-networks\models\lora | �ץ���ץ����ϤǤϤʤ���ĥ���֤ǻ��� |
����LoRA�λ������ˡ
v1.5.0�ʹߤǤϻ���λ������Ѥ�äƤ���Τ�����
LoRA�ξ��Ǥ� lbw= ����ꤹ��褦�ˤʤä�
LoRA�ξ��Ǥ� lbw= ����ꤹ��褦�ˤʤä�
| ���� | ������(IN02����ꤹ����) | ���� | |
| <lora:> | <lora:"lora name":1:1:lbw=IN02> | "lora name"�θ�ˡ�TEnc:UNet �ζ��٤���ꤷ�Ƥ��顡lbw=���dz��ػ��� | |
| <lyco:> | DyLORA�ξ�� | <lyco:"lora name":1:1:1:lbw=IN02> | "lora name"�θ�ˡ�TEnc:UNet:Dyn���ζ��٤���ꤷ�Ƥ��顡lbw=���dz��ػ��� |
| DyLORA�ʳ� | <lyco:"lora name":1:1:lbw=IN02> | "lora name"�θ�ˡ�TEnc:UNet���ζ��٤���ꤷ�Ƥ��顡lbw=���dz��ػ��� ��ά����Dyn�ϥǥե�����ͤȤ���None���������åȤ���� | |
<lora:>��<lyco:>�λȤ�ʬ���ˤĤ���
v1.5.0�ʹߤǤϡ�lycoris�ץ饰�������פˤʤꡢ1111����¢��LoRA��������������Ѥˤʤä���
���ΰ� a1111-sd-webui-lycoris ��Ƴ������ɬ�פϤʤ���<lyco:>��Ȥ�ɬ�פ�̵���ʤä�
���ΰ� a1111-sd-webui-lycoris ��Ƴ������ɬ�פϤʤ���<lyco:>��Ȥ�ɬ�פ�̵���ʤä�
LoRA���̳ؽ�
U-Net�γ����̤˳ؽ�Ψ��Dim/Alpha�����Ǥ���褦�ˤʤä���
������ؤ�LR�����������뤳�ȤDz����ؤαƶ��餷����Ǥ��롣
������ؤ�LR�����������뤳�ȤDz����ؤαƶ��餷����Ǥ��롣
���ԡ���LoRA�ؽ�ˡ
��ؽ�������LoRA�줳�줹�뤳�Ȥǡ��ܤ��礭�������ꡢ�����ȥ饤�����������������˺٤�����ʬ�Τߤ��ѹ��Ǥ���LoRA�������Ǥ����ˡ��
���Τ�̾�ΤϤʤ���ʣ���ʹ��������뤿��Ĺ���������ޤ�Ƥ������ɲƤ��줿�˥��������ΤǷǺܢ�
649: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�2023/05/04(��) https://fate.5ch.net/test/read.cgi/liveuranus/1683...
1������ǥ�A�ǽ��ϲ���B��Ф�
2������ǥ�A�˽��ϲ���B��1�������ؽ������Ʋ�ؽ�LoraC����
3������ǥ�A�˲�ؽ�LoraC��ޡ������ƥ��ԡ�����ǥ�D����(�ץ���ץ�̤���Ϥ��Ƚ��ϲ���B������������ʤ���ǥ�)
4�����ϲ���B��ù����Ʋù�����E����(���βù���ʬ��������LoraH��ȿ�Ǥ����)
5�����ԡ�����ǥ�D�˲ù�����E��ؽ������Ʋù�LoraF����
6��2����5�ι������̤ν��ϲ���B�ǹԤ��ù�LoraF��ʣ�����
7������ǥ�A��ʣ���βù�LoraF��ޡ��������Ʋù���ǥ�G����(flat�ǤϺ������پ夲���Ѥ�Lora���۹��Ĵ�����ƥޡ���)
8������ǥ�A�Ȳù���ǥ�G�ǥ�ǥ뺹ʬ����Lora�������ƴ�����LoraH���Ǥ���(dim��Ĵ���Ϥ����ǹԤ�)
��Tips
1������ǥ�A�ǽ��ϲ���B��Ф�(�ù�����E�Ȥκ�ʬ���Ϥä��ꤹ��褦�˲ù�����Ȥ褤���쥤�䡼ʬ������вù�����E����䤹���ʤ�)
���ù���������ץ�
�ե�åȲ�LoRA�ξ�硣
���ù����òù��墪
��ŵ��https://fate.5ch.net/test/read.cgi/liveuranus/1683...

����¾�ˤɤΤ褦��LoRA�����뤫�� https://huggingface.co/2vXpSwA7/iroiro-lora/tree/m... ��ߤ���ɤ�
���ԡ����ؽ�ˡ�Ϥ�����⻲�ͤˤʤ롣
https://rentry.co/kopiki_lora
���Τ�̾�ΤϤʤ���ʣ���ʹ��������뤿��Ĺ���������ޤ�Ƥ������ɲƤ��줿�˥��������ΤǷǺܢ�
649: ����ŷ������wiki���Ƥ����鵰ƻ���г�(i) ��0.774����ä�2023/05/04(��) https://fate.5ch.net/test/read.cgi/liveuranus/1683...
>318flat����Lora���������äƤ���ʴ����Ǥ��äƤ롩
1������ǥ�A�ǽ��ϲ���B��Ф�
2������ǥ�A�˽��ϲ���B��1�������ؽ������Ʋ�ؽ�LoraC����
3������ǥ�A�˲�ؽ�LoraC��ޡ������ƥ��ԡ�����ǥ�D����(�ץ���ץ�̤���Ϥ��Ƚ��ϲ���B������������ʤ���ǥ�)
4�����ϲ���B��ù����Ʋù�����E����(���βù���ʬ��������LoraH��ȿ�Ǥ����)
5�����ԡ�����ǥ�D�˲ù�����E��ؽ������Ʋù�LoraF����
6��2����5�ι������̤ν��ϲ���B�ǹԤ��ù�LoraF��ʣ�����
7������ǥ�A��ʣ���βù�LoraF��ޡ��������Ʋù���ǥ�G����(flat�ǤϺ������پ夲���Ѥ�Lora���۹��Ĵ�����ƥޡ���)
8������ǥ�A�Ȳù���ǥ�G�ǥ�ǥ뺹ʬ����Lora�������ƴ�����LoraH���Ǥ���(dim��Ĵ���Ϥ����ǹԤ�)
��Tips
1������ǥ�A�ǽ��ϲ���B��Ф�(�ù�����E�Ȥκ�ʬ���Ϥä��ꤹ��褦�˲ù�����Ȥ褤���쥤�䡼ʬ������вù�����E����䤹���ʤ�)
���ù���������ץ�
�ե�åȲ�LoRA�ξ�硣
���ù����òù��墪
��ŵ��https://fate.5ch.net/test/read.cgi/liveuranus/1683...
����¾�ˤɤΤ褦��LoRA�����뤫�� https://huggingface.co/2vXpSwA7/iroiro-lora/tree/m... ��ߤ���ɤ�
���ԡ����ؽ�ˡ�Ϥ�����⻲�ͤˤʤ롣
https://rentry.co/kopiki_lora
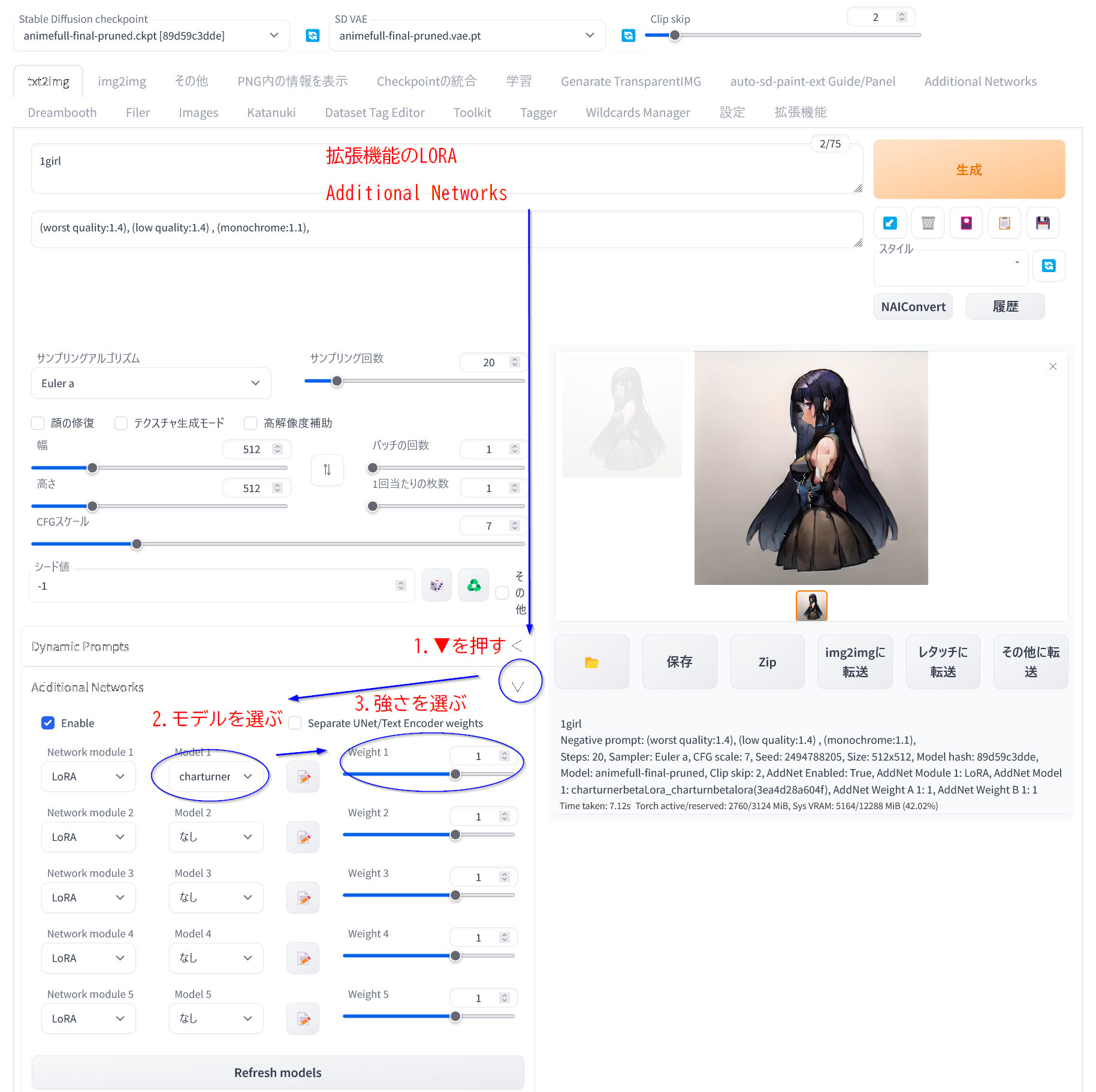
�Ȥ�������1 WebUI�˳�ĥ��ǽ�ȡ��뤷�ƻȤ�
- �ֳ�ĥ��ǽ�ץ��֤Ρ�URL���饤�ȡ���פ� https://github.com/kohya-ss/sd-webui-additional-ne... �����Ϥ��ƥ��ȡ��� )
(Web UI �� �������> ��Additional Nerwork�ץ��֤ǥե�����ξ����ɲý����)
��txt2img�פ��img2img�פβ��̤κ��������ˡ�Additional Networks ���פ��ɲä���Ƥ���Τ�
Enable ����model������merge��Ψ��weight�Υ��饤������Ĵ������
�狼���Ȥ��Ѳ���
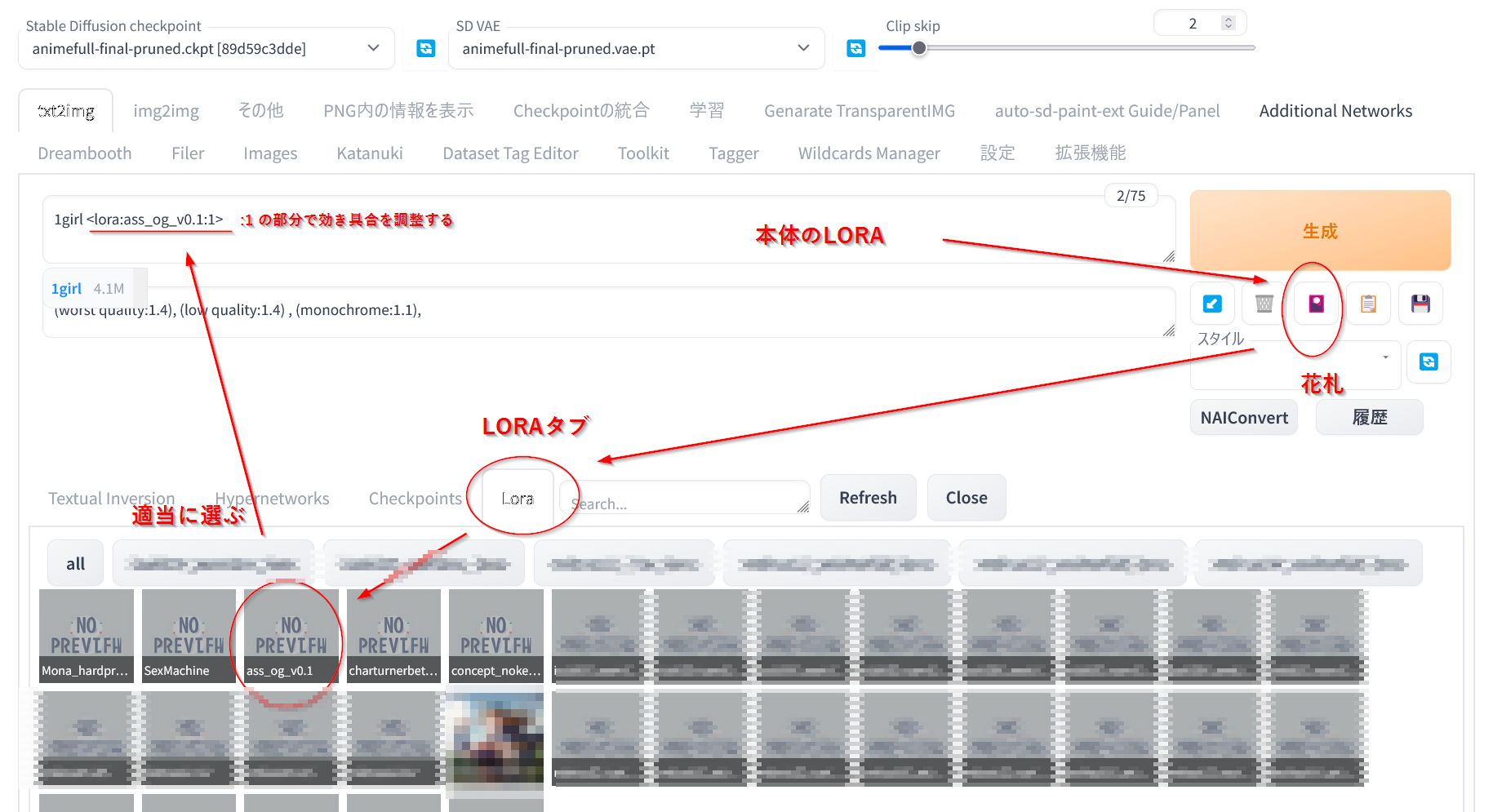
�Ȥ�������2 WebUI�����ε�ǽ�ΤߤǻȤ�
- stable-diffusion-webui\models\lora �˽��ä� .pt �� .safetensors�ԡ�����
Texutual Inversion, Hypernetworks, Lora ��3�ĤΥ��֤��Ф�Τ� Lora ������
�����������֤� <lora:�ե�����̾:��Ψ>�ߤ����ʥ������ץ���ץȤ��ɲä����
�फ�����˺��줿lora��ư���Ȥ�����
�狼���Ȥ��Ѳ���
WebUI���ĥ��ǽ�ι�����Ĵ�Ұ����Ƥ�ɤä����Ǥ�ư���Ϥ�
LoRA�Υ�ǡ����α���/�Խ�
- WebUI��Extra Networks > Lora ���֤� �����˥ޥ��������С����ƽФ�(i)��å������lora�κ����ѥ�����Ȥ�줿������ɽ�������(������Ǥ����)
- Additional-networks��ĥ��ǽ�ȡ��뤹��������륿��(Additional-networks)�����ǡ����Խ��Ȥ��ȥ졼�˥ǡ����Ȥ������
��ǡ����α���(Additionak Networks Extension)
- ����(Additional-networks)�˰�ư����
- Model path filter��õ������LoRA��̾��������ƥե��륿����Ƥ���
- Model ���鳺������LoRA�����֤Ⱦ����ɤ߹��ޤ�ޤ�
��1��UI�Υ���ץ�
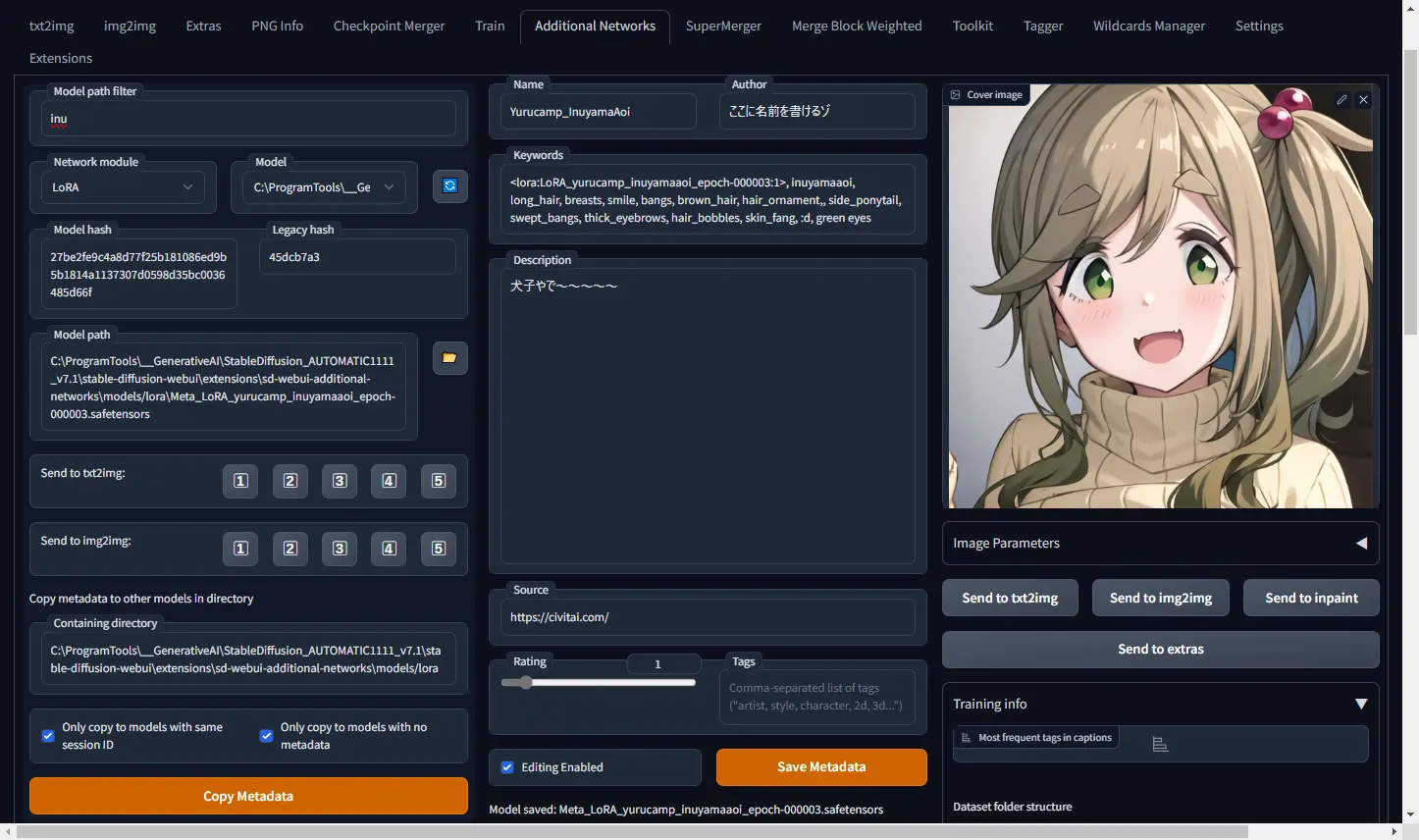
��2���ȥ졼�˥ǡ����Υ���ץ롣�ǿ���sd-scripts�dzؽ����줿LoRA�ϡ�Tagger���դ���줿�����Ȥ��Υ������ɤ줰�餤�ޤޤ�Ƥ��뤫������դDZ����Ǥ���褦�Ǥ���
�����ͥåĤα�������ꤷ���� ���ĥ���������ɤ�����˺�줿���LoRA�⤳��ǥ������ǧ���ƥץ���ץȤ������лȤ��뤫�⤷��ʤ���������
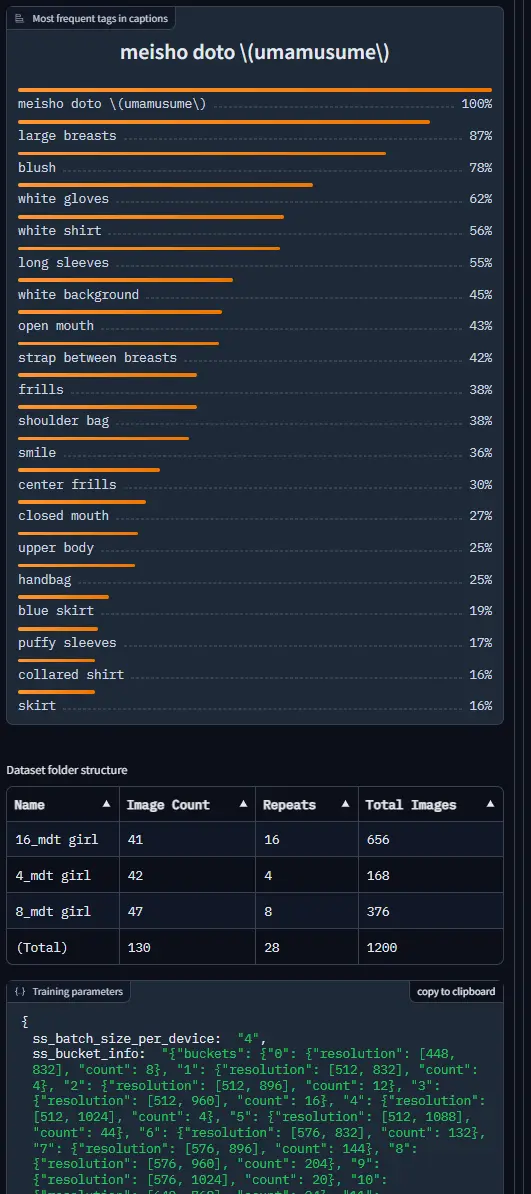
��ǡ������Խ�
- �Խ�������LoRA���ɤ߹���������ǡ��ޤ�ʤ��β��Τۤ��ˤ����Editing Enabled�פ˥����å��������
- ��ǡ������Խ����롣
�Ȥꤢ����Keyword��˥ȥꥬ���ץ���ץȡ�Description�˻�¿������ʸ��CoverImage�˥�����Ѳ��������ꤷ�Ƥ������ɤ����Ȼפ� - ��Save Metadata�פ�LoRA����¸����ޤ������ʤߤ��Խ����Τ�Τϡ֡���.safetensors.backup�פ���¸���Ƥ����Ƥ����褦�Ǥ���
�ʤ�LoRA�ϥƥ����ȥ��ǥ����ǤդĤ��˳������Ȥ��Ǥ����ȥ졼�˥�������(network_dim":"16"�Ȥ�) ������ǧ���뤳�Ȥ��Ǥ��ޤ���
����������¤�Description����ľ���Խ�����ΤϤऺ���������ʤΤǡ�GUI�������ꤹ��Τ�̵��äݤ��Ǥ���
LECO(Low-rank adaptation for Erasing COncepts)
https://github.com/p1atdev/LECO
�ץ���ץȤ�������γ�ǰ��ä����궯��������Ǥ��롣
�㤨�С�miko��������yae miko�˱�������Ƥ���Τ�������Ȥ��ä����Ȥ��Ǥ��롣
�ץ���ץȤ�������γ�ǰ��ä����궯��������Ǥ��롣
�㤨�С�miko��������yae miko�˱�������Ƥ���Τ�������Ȥ��ä����Ȥ��Ǥ��롣
����
�ؽ��������٤�bfloat16��NVIDIA��Ampere����(RTX30)�ʹߤ�GPU�Τ��Ѳ�ǽ������ʳ���GPU�Ǥ�float32�侩��
��� / Tips
���椫��ؽ���Ƴ�������
���ޥ�ɤ˰ʲ��ΰ����ȥѥ�����ꤹ��гؽ����˳ؽ��Ѥߤ�LoRA�νŤߤ��ɤ߹��ߡ����������ɲädzؽ��Ǥ��ޤ���
--network_weights=
���
���Ƥ�LoRA�ؽ��Ǻ���� ���10��20����������ޤǤ���Ǥ��� ���ݥå����⤦5�Ǥ����� ���ƥåס�500�ʾ�ˤ���ʡ���������ޤDz�ž��®�� ��������2048x2048�ʾ�Ȥ��Ǥʤ���Ф��Τޤ�������� ����ץ����/�������Խ�̵���Ǥⲿ������Ф���ޤ��� ��§�����ʤ��Ǥ�졡���Ԥθ�����¿ʬ��������ʤ� �ؽ����Ƚ��ϥ�ǥ��·����
���ڥå��˴ؤ���Tips
VRAM8GB�Ǥ�512x512��Batch size2��;͵��ư����
gradient_checkpointing��ͭ���ˤ����VRAM8GB��1024x1024��Ǥ��롣
�ִ�Ū��ʪ�������20GB����Τ�16GB�ʾ夢�ä��ۤ����¿���
���ۥ����torch�С�������max_data_loader_n_workers���ͤˤ�뤬��20-60GB���롣
gradient_checkpointing��ͭ���ˤ����VRAM8GB��1024x1024��Ǥ��롣
�ִ�Ū��ʪ�������20GB����Τ�16GB�ʾ夢�ä��ۤ����¿���
���ۥ����torch�С�������max_data_loader_n_workers���ͤˤ�뤬��20-60GB���롣
���������
- ����Ū��Lora�ϸ�����DreamBooth�ߤ����˳ؽ�������ʬ�ե�������ǥ�˥ޡ������뤿��κ�ʬ�ѥå��ߤ����ʤ��Ȥ��ƻȤ���������Ǻ���Ȥ뤫�顢���θ���Ŭ�Ѥϸ������߷פȰ㤦�Ȥ����ʤ�䡢�ʤ�ǿ������»��ब���롣
- Lora����§�ֺ�ä���ǥ��Ʊ������(SD-v1.x�� or SD-v2.x)�פǤ���Ŭ�ѤǤ��ؤ��ǡ��פ����Any�Ȥ��Ǻ�ä�Lora��WD1.4�ʹߤȤ��ˤϻȤ��ؤ����εդ⤷����䡣
- �褯�����Ȥ�������HyperNetwork�Ϸ����ޤ����Ǥ���ȿ�ǤϤ���Ȥ�ߤ�����ǡ�����ɡ�
- Extra Netrowks�Ǵְ㤨��SD1.x�Ѥ�LoRA��SD2.x�ǻȤ���WebUI��Ƶ�ư����ޤǥ��顼�����٤ȻȤ��ʤ��ʤ뤫�����դ��
- �ޤ���Lora��ʣ��1�ܤǽŤͤƻȤ��ȳ����������䤹���ʤ롣Ŭ�Ѥ��������ؤ��㤦��硢����Ŭ�ѽ���륨�����ƥ��Ȥ��Ǥ��餷���館����Ȥ��㤦���ʡ�����ɡ�
- ��ˤ���̤����Ū�˺�ʬ�ѥå��ߤ����ʤ��䤫���ǥ뤴�Ȥ˺�Ŭ����Ψ�Ϥ��㤦���ä��ꤹ��ǡ����ä��Υ�ǥ�Ǥ�1�ܤǤ��礦�ɤ褫�ä����ä��Υ�ǥ�Ǥϳ�����������Ȥ������̤ˤ���ǡ���Ψ��Ŭ�٤��Ѥ��䡣
- ����Ū�����ۤ���Ȥ���kohya��ˤ���ĥ��Lora�䤱�ɸ����μ����Ǥ�Lora��DreamBooth�������ƥ��Ȥ��Ǻ�줿�ꤹ�뤫���ä��ݤˤϤ��ä���ˤ���褦�ˤʡ�
- ��ĥ��ǽ������kohya��ˤ���ĥ��Lora�Τߤ��б��䡣���ε�ǽ�����ϸ����μ����ǤǤ�Ԥ����Ȥ��㤦���ʡ�����ɡ�
- Lora����§�ֺ�ä���ǥ��Ʊ������(SD-v1.x�� or SD-v2.x)�פǤ���Ŭ�ѤǤ��ؤ��ǡ��פ����Any�Ȥ��Ǻ�ä�Lora��WD1.4�ʹߤȤ��ˤϻȤ��ؤ����εդ⤷����䡣
���Υڡ����ؤΥ�����
SDXL(pony)��LoRA�ؽ��Ϥ�褦�Ȥ��Ƥ����֤����Ǥ�����������ۤܽ�Ĺ�ˤʤ��ΤǤ�����ĹLoRA��ꤿ�����Ϥɤ�����Τ��ɤ��Ȥ�����ޤ��Ǥ��礦����
����Ū�ˤ�
�ؽ�����������Ĺ�Τޤ������ or ����������������������ˤ��� or �岼ʬ�䤷��������2�ե�����ˤ���
�ؽ����ꡧ��1024px�Τޤ� or ���Ӥ���Ƥ�ʤ�1216px���餤�ˤ��� or ������Ĵ���Ǥ���ġ���Ȥ��ʻȤ����Ȥ��Ƥ��뤳�Υ����TrainingGUI���������Ǥ��ʤ�����
aspect ratio bucketing�Ȥ��������Υ����ڥ�����˹�碌�������٤dzؽ����뵡ǽ������ΤDz������Τޤؽ��Ǥ��ޤ��衣
������--enable_bucket�Ĥ����ͭ���ˤǤ��ޤ�
��ޤʲ������꤬�Ȥ�������̵�̤ʸ��ڻ��֤�����ޤ�����
���Ԥ��դ�ʪ�ȸ����ޤ����ɳؽ��ϼ��Ԥ�¿���������������Ƥ�Τ�ʬ����Ť餤��
�����־��Ť��ʤäƤ��ޤ�����
���������������ޤ���
XL�Ǥγؽ���ˡ�β���ʤ�
�������������
bmaltais�� GUI����
SDXL�Υץꥻ�åȤ��ͤ��⤹������
�����ƻȤä�������Ŭ�٤˺��ʬ�ˤ��ɤ���������
���Ȳ�ؽ��������䤹����ǎ�
epoch���ȤΥ����֤ώ����ޤ�����ꤷ�������ɤ�����
Additional-networks��ĥ��ǽ��Ȥ��������ġ��������������ɤ�
���ʤ�����
kohya������3~4000���ƥåפǺ��ȤǤ���ΤϤǤ��������ɡ���ɴMB�����̤ˤʤäƤ��ޤ��ޤ���
civitai���֤��Ƥ���LoRA�ե����븫�Ƥ�����礭����144MB�ʤΤˡġġ�
�����äƤ�ե����륵�����˴ؤ������Ϥʤ��ʤ���������ʤ���Ǥ�����
����ɸ��Ū�˥ե����륵�������ޤ����ˡ�������Ǥ��礦����
--save_precision "fp16"����ꤹ������̤�Ⱦ�����ޤ�
LoRA_Easy_Training_Scripts��GUI��������GUI���Ƥƥ��åץǡ��Ȥ����顣�֤ä��ޤ����������5��ʹߤ������ʹ��������ä��ߤ�����