kohya_train_network_simple
最終更新:ID:qdELzIhBUw 2023年11月03日(金) 22:18:15履歴
あかちゃんLoRAノートブック
更新情報
20231103(beta)
20230316(beta)
skkmtn_20230316.webp
xformersについて
昔学習出来てなかったトラウマとかで0.0.16が苦手な人向け
LyCorisとか新しいやつ対応について
kohya氏の最近の更新曰く
新しい鉄板設定が見つかるとか2倍速くなるとか花札対応したとかがあったら組み込みたいとは思っている。
20230215
20230210
20230206
20230205
品質はそのままに、2倍速くなったので、kohyaを20230204に更新しました。
学習は20分で終わるので、全体でも40分以内には終わると思います。

ねらい
しなくていいこと
1. Googleのアカウントを作成する
2. Huggingfaceのアカウントを作成する
ユーザー名はあとで使うのでメモっておきましょう。
既に取得済みのを使いまわすなら名前とかメールアドレスとかが見られてもいいものか要チェック。
3. アクセストークンを追加する
追加したトークンはあとで使うのでメモっておきましょう。
(必要になった時にこのページを開いてコピペするほうが安全だけど)
4. 名前を決める
プロンプトに入れる単語になり、モデルの名前になります。
たとえば zunko
5. 学習用画像を用意する
25枚くらいを目標に頑張って用意しましょう。
長方形でも良いですが、縦横の差が2倍を超えないようにしましょう。
解像度は平均768くらいはあったほうがいいです。(512x1024とかでも可)
大きいのは勝手に縮小されるので大丈夫です。
ファイル名はなんでもいいけど長いと読み取れなくなるので、
長い名前や日本語などがあったら全選択してF2を押して短く改名しましょう。
6. 画像のフォルダ分け
画像は品質ごとの3種類にフォルダ分けすることができます。
(分けなくてもいいです)
a. 高品質、とても良い画像、特に学習したい画像
b. 中品質
c. 低品質、ちょっとだけ学習してくれればいい画像
7. 画像をzipにする
a. b. cをそれぞれzipで圧縮します。
右クリックで「送る」「圧縮(zip)フォルダー」
名前はなんでもいいのでわかりやすくしましょう。
たとえば zunko_a.zip zunko_b.zip zunko_c.zip
8. 🤗にDatasetを作る
9. zipを🤗にアップロードする
10. Notebookを自分のDriveにコピーする
11. 設定
いままでの手順で用意した内容を入力します
12. 学習
三角ボタンを押します。
進捗表示が出るので終わるまで待ちましょう。
勝手にアップロードして勝手に終了するので寝ても構いません。 13. LoRAのダウンロード
🤗の自分のモデルページを開きます。
モデル名が zunko なら、
https://huggingface.co/ユーザー名/nva-zunko/tree/main
が出来ているはずです。
↓を押して zunko.safetensors をダウンロードします。
14. 結果の確認
メイキング
ノートブック作成において工夫した点など。
カスタマイズの参考にしてや。Colabのページも参考になるかも。
このノートブック自体のカスタマイズ性を上げる予定はありません。
これはあくまで入門用だから。
一応コードにコメント書くようにはしているつもり。
正則化画像とキャプションテキストへの対応は古いノートブックが参考になるかも。
古いのでそのまま実行しても動きません(そっちはもう直さない)
kohya_sd-scripts_intro
更新情報 
20231103(beta)
- 2023-11-3状態の現状に最適化されたヴァージョンです。
- 旧バージョンはもうそぐわないので、SD-scriptは最新のものを使用。
20230316(beta)
- まだ安定してないので別のノートブックを作りました
- Pythonのインストールと環境確認を入門用Notebookと揃えました
- condaでのインストールが必須です(3.9だとpsutilのバージョンが足りなさそう)
- fairscale==0.4.13はインストールしても動くようになっていました
skkmtn_20230316.webp
{kind=link}
xformersについて
昔学習出来てなかったトラウマとかで0.0.16が苦手な人向け
- バージョン指定を外せば0.0.17のdev版が入るかも
- リリース版とかタグとかは無いので、この安定版を使おうみたいなモチベはまだ無い
LyCorisとか新しいやつ対応について
kohya氏の最近の更新曰く
大きく変更したため不具合があるかもしれません。問題が起きた時にスクリプトを前のバージョンに戻せない場合は、しばらく更新を控えてください。 Stable Diffusion web UI の LoRA 機能は LoRAの Conv2d-3x3 拡張に対応していないようです。使用するか否か慎重にご検討ください。ということなので安定待ち。
新しい鉄板設定が見つかるとか2倍速くなるとか花札対応したとかがあったら組み込みたいとは思っている。
20230215
- 学習画像が一つもない場合にエラーで停止するようにした(calc_repeatが無限ループを起こすので)
- 以下のコメントに対応して動作を確認。Thanks!
/bin/bash: accelerate: command not found が発生するようになったので、お困りの方は環境構築の上あたりで !pip install --upgrade nni --ignore-installed とやってみて下さい。当方環境ではこれでOKでした。
20230210
- pip先の更新によって壊れてたみたいなのでkohyaを更新しました
- 今後も同様の問題は発生するものと思われ
- requirements.txtを一行ずつpip installすれば部分的には動くかも知れない
20230206
- 繰り返し回数が被る時のリネームをファイル単位の移動にしました
- 3つのzipの中にある画像ファイルはみんな別々の名前にしといてや
- 同じRuntimeで2回実行する時は古い画像を消すようにしました
20230205
品質はそのままに、2倍速くなったので、kohyaを20230204に更新しました。
学習は20分で終わるので、全体でも40分以内には終わると思います。
masterpiece, best quality, 1girl, skkmtn, 1boy,breastfeeding handjob,nursing handjob,breast sucking,penis,nipples,lactation, cum <lora:breastfeeding_handjob:1> <lora:skkmtn:1>

ねらい
- LoRAの雰囲気を味わえる手順書です
- なんとなくおおまかなキャラ再現が出来る程度です
- PCの性能や課金は不要です(1111で生成できることが前提)
- 学習画像は自分で用意します
- 🤗を活用します
しなくていいこと
- kohyaのバージョンは20230204版に固定しました
- requirements.txtはNotebook上のsedで修正します
- aptやpipが壊れない限り動くはず
- コマンドラインオプションは勝手に決めます(メイキングを見てね)
- 正則化画像は使いません
- キャプションテキストは使いません
- 背景処理(Katanuki等)はしません
- LoRAを作る以外の機能はありません
1. Googleのアカウントを作成する
2. Huggingfaceのアカウントを作成する
- 要メールアドレス(さっき作ったGoogleので良い)
- https://huggingface.co/
ユーザー名はあとで使うのでメモっておきましょう。
既に取得済みのを使いまわすなら名前とかメールアドレスとかが見られてもいいものか要チェック。
3. アクセストークンを追加する
- https://huggingface.co/settings/tokens
- 「New Token」を押す
- Name: 任意
- Role: write
追加したトークンはあとで使うのでメモっておきましょう。
(必要になった時にこのページを開いてコピペするほうが安全だけど)
4. 名前を決める
プロンプトに入れる単語になり、モデルの名前になります。
たとえば zunko
5. 学習用画像を用意する
25枚くらいを目標に頑張って用意しましょう。
長方形でも良いですが、縦横の差が2倍を超えないようにしましょう。
解像度は平均768くらいはあったほうがいいです。(512x1024とかでも可)
大きいのは勝手に縮小されるので大丈夫です。
ファイル名はなんでもいいけど長いと読み取れなくなるので、
長い名前や日本語などがあったら全選択してF2を押して短く改名しましょう。
6. 画像のフォルダ分け
画像は品質ごとの3種類にフォルダ分けすることができます。
(分けなくてもいいです)
a. 高品質、とても良い画像、特に学習したい画像
b. 中品質
c. 低品質、ちょっとだけ学習してくれればいい画像
7. 画像をzipにする
a. b. cをそれぞれzipで圧縮します。
右クリックで「送る」「圧縮(zip)フォルダー」
名前はなんでもいいのでわかりやすくしましょう。
たとえば zunko_a.zip zunko_b.zip zunko_c.zip
8. 🤗にDatasetを作る
- https://huggingface.co/new-dataset
- Dataset name: nva-Zunko (決めた名前の頭にnva-をつける)
- 他はいじらない
- 「Create dataset」を押す
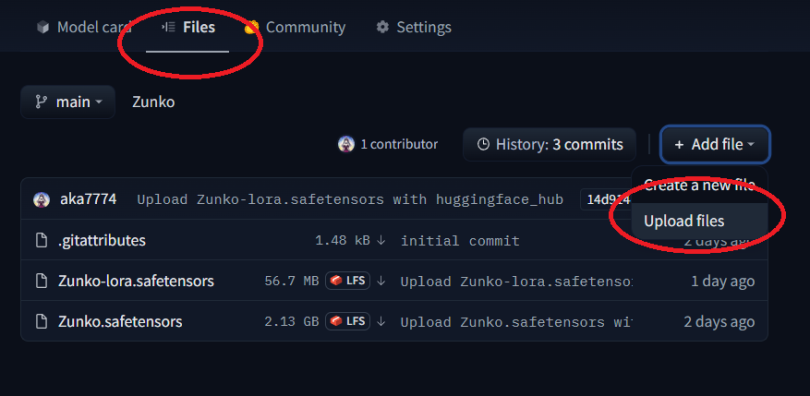
9. zipを🤗にアップロードする
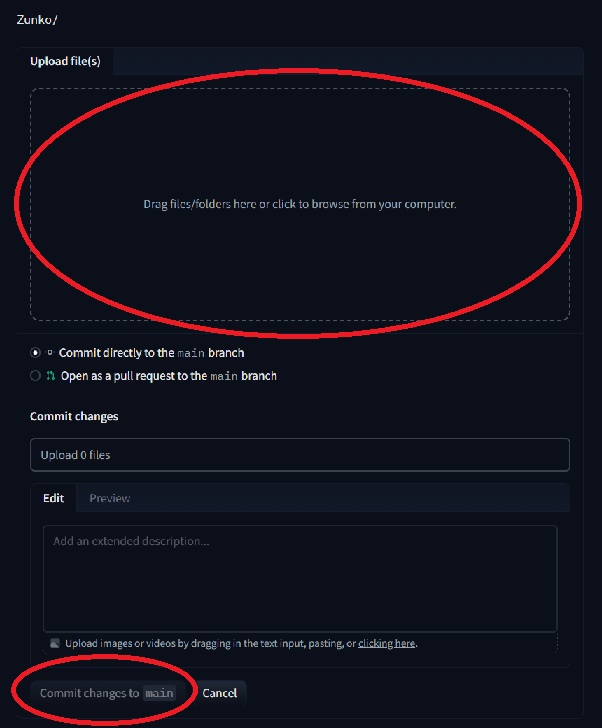
- 「Files」タブの「Add File」の「Upload Files」
- 3つのzipをドロップかクリックで選択して「Commit changes to main」を押す
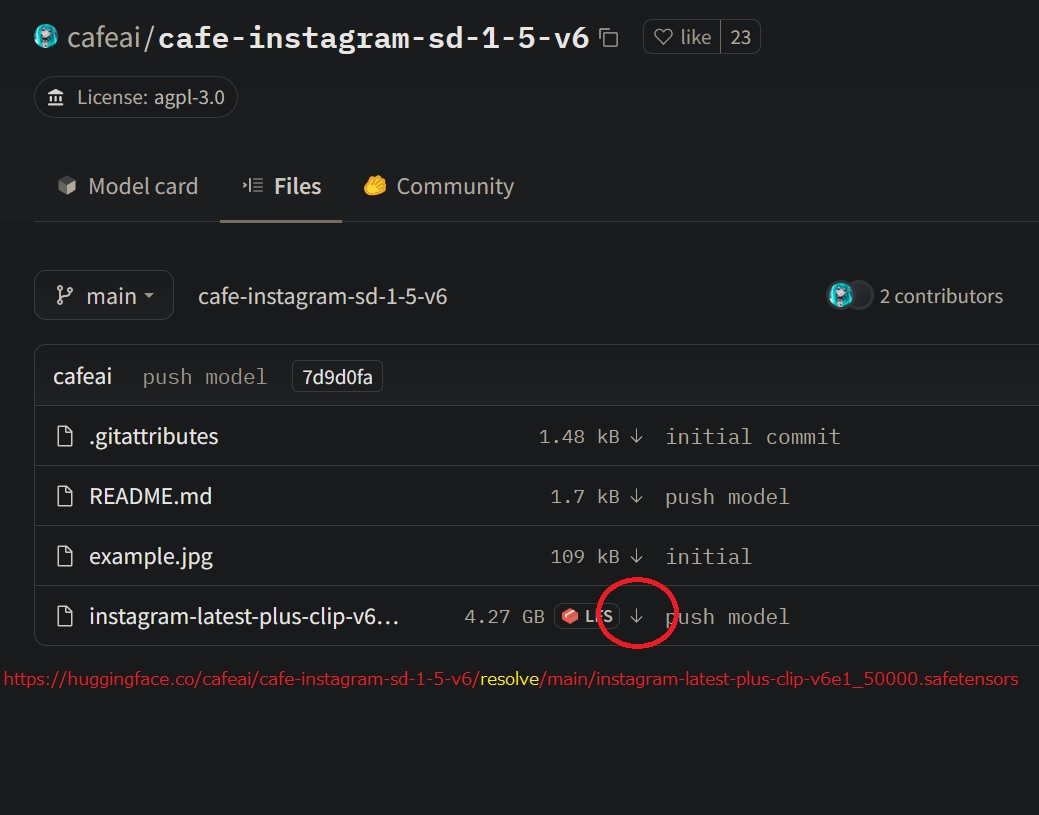
- アップロードされたファイルの行にあるファイル名ではなく「↓」を右クリックしてURLをコピーしてメモっておく
10. Notebookを自分のDriveにコピーする
- https://colab.research.google.com/drive/1XBDdsczuD...
- File
- Save a copy in Drive
11. 設定
いままでの手順で用意した内容を入力します
- Huggingfaceのユーザー名 手順2
- Huggingfaceのwriteトークン 手順3
- モデルにつける名前 手順4
- 学習画像zip(品質A〜C)のURL 手順6〜9
12. 学習
三角ボタンを押します。
進捗表示が出るので終わるまで待ちましょう。
勝手にアップロードして勝手に終了するので寝ても構いません。
13. LoRAのダウンロード
🤗の自分のモデルページを開きます。
モデル名が zunko なら、
https://huggingface.co/ユーザー名/nva-zunko/tree/main
が出来ているはずです。
↓を押して zunko.safetensors をダウンロードします。
14. 結果の確認
手元の1111で動作確認しましょう。
1111起動後ColabのNotebookに戻り、左端の📁を押して
stable-diffusion-webui\models\Lora を右クリックしてアップロードを押す
手順13.でダウンロードした zunko.safetensors を選択
1111のsettingタブ→stable diffusion→
Clip Skipを2にしといてね
txt2imgタブから🎴を押してLoRAを選択後Refreshを押して
ダウンロードしたモデル zunko を選択するとプロンプトに <lora:zunko:1> が追加される。(もう一度押すと解除)
好きなモデルで試すことが出来ますが、学習元のモデルは ACertainty です。
https://huggingface.co/aka7774/fp16_safetensors/re...
ぐちゃぐちゃな絵が出てきたら、おそらく過学習です。
モデルページにあった -000009 から -000001 までのファイルを試してみましょう。
(数字はepochで、数字の無いモデルはepoch 10です)
あるいは、プロンプトにある
全然似てない絵が出てくる場合は、学習不足か強度不足です。
うまくいったら naked などのキーワードを追加して学習の度合いが適切か確認しましょう。


1111起動後ColabのNotebookに戻り、左端の📁を押して
stable-diffusion-webui\models\Lora を右クリックしてアップロードを押す
手順13.でダウンロードした zunko.safetensors を選択
1111のsettingタブ→stable diffusion→
Clip Skipを2にしといてね
txt2imgタブから🎴を押してLoRAを選択後Refreshを押して
ダウンロードしたモデル zunko を選択するとプロンプトに <lora:zunko:1> が追加される。(もう一度押すと解除)
好きなモデルで試すことが出来ますが、学習元のモデルは ACertainty です。
https://huggingface.co/aka7774/fp16_safetensors/re...
ぐちゃぐちゃな絵が出てきたら、おそらく過学習です。
モデルページにあった -000009 から -000001 までのファイルを試してみましょう。
(数字はepochで、数字の無いモデルはepoch 10です)
あるいは、プロンプトにある
<lora:zunko:1>の数字を0.1ずつ下げてみましょう。
全然似てない絵が出てくる場合は、学習不足か強度不足です。
(zunko:1.1)の数字を0.1ずつ上げてみましょう。
うまくいったら naked などのキーワードを追加して学習の度合いが適切か確認しましょう。
masterpiece, best quality, 1girl, zunko <lora:zunko:1>

masterpiece, best quality, 1girl, zunko, naked <lora:zunko:1>

メイキング
ノートブック作成において工夫した点など。
カスタマイズの参考にしてや。Colabのページも参考になるかも。
このノートブック自体のカスタマイズ性を上げる予定はありません。
これはあくまで入門用だから。
一応コードにコメント書くようにはしているつもり。
正則化画像とキャプションテキストへの対応は古いノートブックが参考になるかも。
古いのでそのまま実行しても動きません(そっちはもう直さない)
kohya_sd-scripts_intro
- Huggingfaceに最初にログインする
- get-pipとhuggingface-hubの相性が悪くて、先にログインしないとエラーになる(というバグが最近増えた。いずれ直るかも)
- 環境の情報表示
- たぶん要らないけどメンテのために残している
- T4よりしょぼいGPUが割り当たる可能性を気にしてたけど数か月で当たったことがない
- 「最初に Rumtime - Change runtime type で GPU を選ぶ。」は最近不要になった(昔はNoneに戻されていた)
- !sudo apt-get -y install python3.10
- リポジトリを追加してるノートブックが多いけど無くても動いた(違いは不明)
- !sudo cp `which python3.10` /usr/local/bin/python
- 行儀が悪いけど後のコードが読みやすくなるので・・・
- python 3.8と併用したい時にはこういうことをしないようにしましょう
- !sudo python get-pip.py
- aptで更新すると古いpipが入ってうまくいかないことがあった
- torchのインストールは時短のため割愛
- torch==1.13.1+cu116 が最初から入ってる
- どうせT4はcu112なのでどっちでも実質変わらんはず
- xformersはこのバージョンでいける
- 一時期うまくいかん報告が上がってたけどなんかうまく動くようになった
- kohyaは動くバージョン(20230204)で固定
- 自分のリポジトリに1個だけfork出来るので動作確認できたバージョンに更新していくつもり
- 絶対にこのバージョンじゃないと嫌なら自分のとこにforkしておくと安心かもね
- !sed -i "s/fairscale==0.4.4//g" requirements.txt
- kohya氏はColabでテストしてないかColabに対応する気がないので毎回いじる必要がある
- modelは固定
- URLを変えるときは、下のほうの pretrained_model_name_or_path も変える必要がある
- 出来るだけ無垢なモデルに教え込むといいのが出来るらしい
- ベストはNAIっぽいけど赤ちゃんにリーク品をダウンロードさせる訳にはいかないので・・・
- pruned, fp16, safetensorsのモデルにしないとメモリが足りなくなる
- だいたい2GBくらいのだと良さそう 詳しくはModels
- でかいほうが良い学習が出来るかも知れないけど個人的には気にしなくていい差なんじゃないのって思う
- trainは一旦ディレクトリ構造を無視してunzip
- kohyaで一番ややこしいのが「画像がありません」エラーだと思っている
- 繰り返し回数は後で決めたいからzipで固定しないほうがいいよね
- 100stepsに出来るだけ近づけるよう繰り返し回数を計算する
- キャラによって集められる画像枚数が違うのを吸収する仕組み
- 24枚の画像を8枚3組に分けて6,4,2回繰り返す(96steps)のがデフォルトってイメージ
- 100枚超でやると学習時間は増えます(別に支障はない)
- 繰り返し回数を適用するためリネームする
- 雑にコピペしてしまったけど4種類以上に増やすなら書き直したほうが綺麗かも
- トレーニング
- resolutionは1024に出来るけど高解像度の打率はあんま変わらない印象
- 768で学習して768x768か512x768で出すのが最も安定した
- 変えるならmin_bucket_reso, max_bucket_resoも忘れずに揃えましょう
- enable_bucketによって長方形の画像うまいこと対応してくれる
- jpgでもいけるので画像は適当に放り込んで良さそう
- batch_sizeには余裕があるので4とかに上げても動くかも
- VRAM 16GBなので将来対応も余裕
- mixed_precisionはfp16。生成時もfp16モデルと合わせて使う想定
- learning_rateはちょっと高めにしといてダメなら低epochのを使おう作戦
- 1e-2だとさすがに破綻した
- 結局10epochのが一番出来がいい気がする
- num_cpu_threads_per_processは1がいいらしいとkohya氏が言ってた気がする
- max_data_loader_n_workersはColabのCPUが2スレッドだし増やすとメインメモリを食うので2
- メインメモリは12.6GBしかないのでけちけち使う必要がある
- color_augを外してcache_latentsにすることも出来るが効果は実感できなかった
- seedはなんでも良さそうだけど今回は114514は勘弁しておいた
- clip_skipはSD2系で2がデフォルトらしいので・・・
- lr_schedulerは一番最後に実装されたやつが一番いいのではないかと思っている
- network_dim は 4chan で流行った128にしてある
- あとから変換ツールで下げることは出来るらしいので高めで良いかなと
- resolutionは1024に出来るけど高解像度の打率はあんま変わらない印象
- アップロード
- ほんとは1epochごとにアップロードしたかったけど全体が速くなったんでまあいいかって感じ
このページへのコメント
cudaのバージョン下げれないからダメだ。締め出しされてる。
またエラーが出て出来なくなってますね…
TypeError Traceback (most recent call last)
<ipython-input-7-5455251dd218> in <cell line: 53>()
52 res = get_ipython().getoutput("nvcc -V | grep 'Cuda compilation tools, release' | grep -o '[0-9.]*'")
53 if not res[0].startswith('11.8'):
---> 54 raise RuntimeError("CUDAのバージョンが変わった " + res)
55
56 # RAMの容量取得(GiB)
TypeError: can only concatenate str (not "SList") to str
止まりました バージョン変わったかな?
if not res[0].startswith('12.2'):
これでチェックは通りましたが弊害があるかも
現状動くものに更新しました。sd-scriptsも最新のものを使用します。
ありがとうござます。息子の命が救われました。
本当にありがとうございます。英雄です
ありがてぇ
10/10 現在、以下のようなエラーが出て動作しないですね…。
解決方法わかる方、いらっしゃればどうか教えて頂きたいです…。
external/xla/xla/stream_executor/cuda/cuda_dnn.cc:435] Loaded runtime CuDNN library: 8.5.0 but source was compiled with: 8.6.0. CuDNN library needs to have matching major version and equal or higher minor version. If using a binary install, upgrade your CuDNN library. If building from sources, make sure the library loaded at runtime is compatible with the version specified during compile configuration.
エラー内容は違えど昨日から正しく動作しないみたいだね
ubuntuのバージョンが更新されたのかな?
どのバージョンならエラーが出ないかわかりますか?
自分のやり方が悪いのか、バージョンが合ってないのか
ダウングレードしても同様のエラーが出てしまって…