基本操作とローカルでの環境構築
最終更新:
![]() kenken2020 2022年11月24日(木) 16:23:57履歴
kenken2020 2022年11月24日(木) 16:23:57履歴
Stable Diffusion web UIの導入方法 
- 現状(2022/11)では一番人気
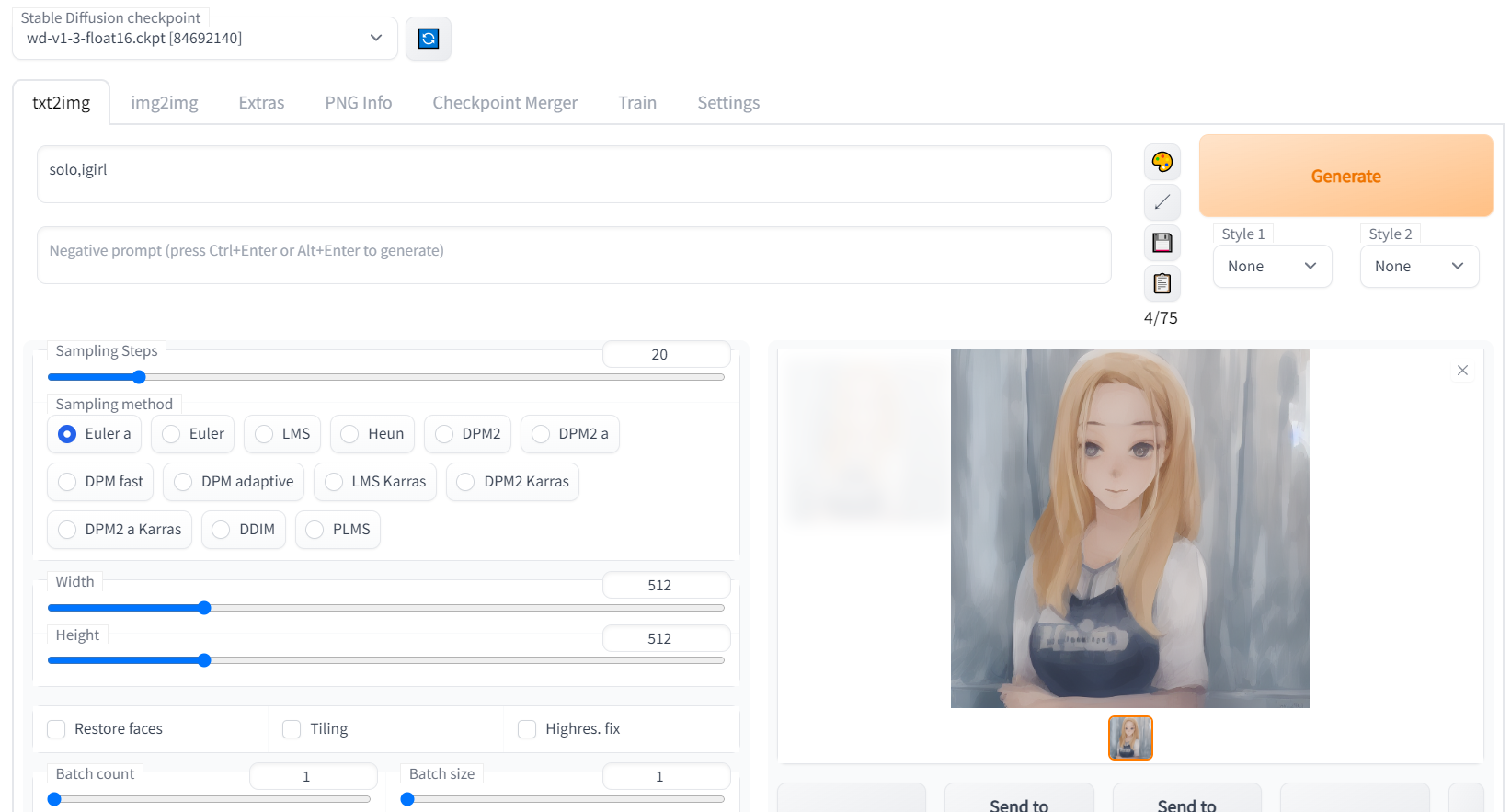
参考:画像生成AI「Stable Diffusion」でイラストを描くのに特化したモデルデータ「Waifu-Diffusion」使い方まとめ
参考:無駄を省いたStable Diffusion Web UIの導入方法。多機能でWindowsローカルGUI環境
Github:AUTOMATIC1111氏版
Github:Waifu Diffusion 1.3
依存関係:必要な依存関係
- Githubの「Installation and Running」をよく読むこと
- ソースコードがZipではなく、Git Cloneの方がアップデートが簡単なので良いかもしれない
- GITクローン
git clone https://github.com/AUTOMATIC1111/stable-diffusion-...
- 「Shift+右クリック」→「PowerShell ウィンドウをここに開く」をクリックで該当箇所にCDした状態でコマンドプロンプトが開く
- 必要な環境
- NVIDIA製GPU
- 10GB以上のVRAMを搭載したビデオカード
- GTX 1060 6GB
- GTX16系のグラボの場合、ひと手間かかる
- Pythonのインストールと動作確認
python -V
- Gitのインストールと動作確認
git -v
日本語化
最新のVerだと最初からローカリゼーションファイルがある?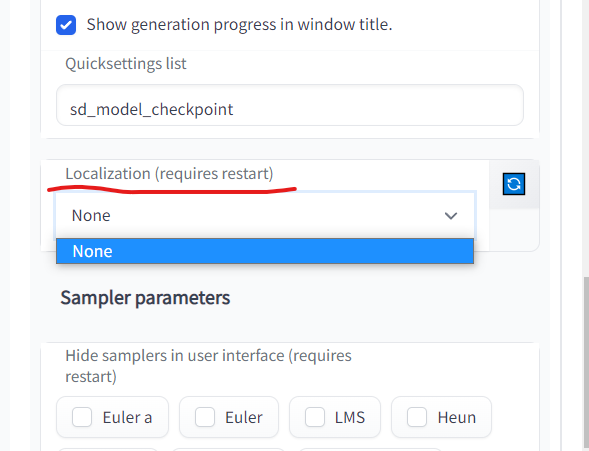
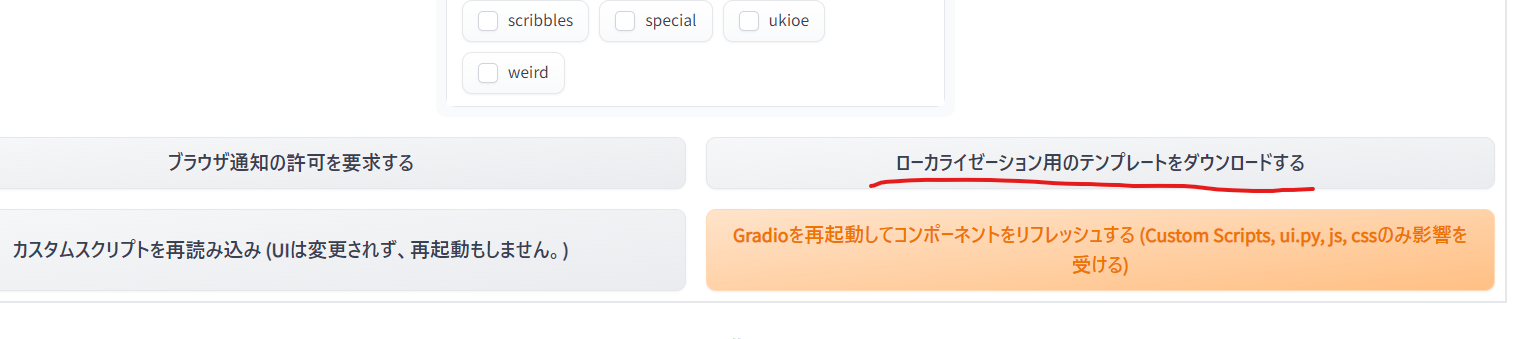
- 「Settings」→「Localization (requires restart)」から変更する
- 自分で翻訳や更新で項目が追加された場合
- 「Setteings」から「localization.json」ファイルを落とす
- 次のフォルダにある日本語化ファイルを修正する→インストールフォルダ\localizations\ローカライゼーション.json
- Winマージなどで比較する
GITでの更新
- インストールフォルダ内でShift+右クリックをしてPowerShell ウィンドウをここに開くをクリック
git pull origin master又は
git pull
- アップデート前に既存のファイルを別の場所に移す必要はない
Stable DIffusion Web UI(AUTOMATIC1111氏版)導入で躓いた点
Pythonのバージョン関連
- Anaconda→Pythonのバージョンが対応していない
- pyenv
- pyenv自身のアップデート方法
- pyenvを使ったPythonのバージョン変更はうまくいかず
- Gitのクローン方法
webui-user.bat
- 何故か起動しなかった
- Pythonのインストール先が問題だった?
- 小手先の対処法→PCの再起動
- エラー9009が出た場合、バッチ内の項目「python=」にPythonのインストール先を指定する必要がある?
- CUDA Tool KitやPyTorchはバッチで良い感じにインストールしてくれる?
- バッチ処理はそれなりに時間がかかる
高速化
参考:高速化できるXformersを導入しよう
xformersを導入することにより使用するメモリ減&高速化してくれます。
しかし、デメリットとして若干生成される画像が変わります。
xformersを導入することにより使用するメモリ減&高速化してくれます。
しかし、デメリットとして若干生成される画像が変わります。
- webui-user.bat内の以下を書き換える
set COMMANDLINE_ARGS=--xformers
- deepdanbooru.も使う場合は以下
set COMMANDLINE_ARGS=--xformers --deepdanbooru
Stable DIffusion Web UI(AUTOMATIC1111氏版)の使い方
バッチ設定
Batch count:バッチを何回行うのか
Batch siz:1回のバッチで何枚の画像を生成するのか
Batch siz:1回のバッチで何枚の画像を生成するのか
- Stable Diffusionは画像生成を「バッチ」単位で行う
- 1回に生成する画像が多いとVRAM使用量が増えるので、VRAMが少ない環境だとエラーが出やすくなる
- VRAMの少ない環境だと「Batch count」で生成したい数を指定し、「Batch size」は1にしておくとエラーなく安定して画像生成ができる
- Batch sizは2までならいける?
- 現状は生成ガチャのようなので、20〜30回ぐらい回してその中から選ぶ感じか?
シード値
- 「-1」だと毎回ランダム生成となる
- 当該画像のシード値を入力することで、同じ構図や雰囲気を維持して、別パターンの画像を生成することができる
CFG Scale(プロンプト強度)
- プロンプトの指示にどれぐらい従うかを示す値
- 大きくすればするほど指示に沿った内容になるが、絵自体が崩れやすくなる
- 一般的には7〜11が適当
- NovelAIの「strength」に相当?
- 「strength」の最大値は0.99、デフォルトは0.7
Denoising strength(デノイズ強度)
- ノイズ要素?
- NovelAIにおける「noise」に該当?
- 値が小さい→元絵に近い
- 値が大きい→AIが独自要素を付け足す
- 入力画像と出力画像と相違度
- 0.45〜0.75ぐらい?
Restore faces(顔の修復)
- そのままだと崩れがちな顔の補正を強力に行い、できるだけ左右対称を維持してくれます。
- 人物を描画するなら基本的にチェックを入れた方がいい?
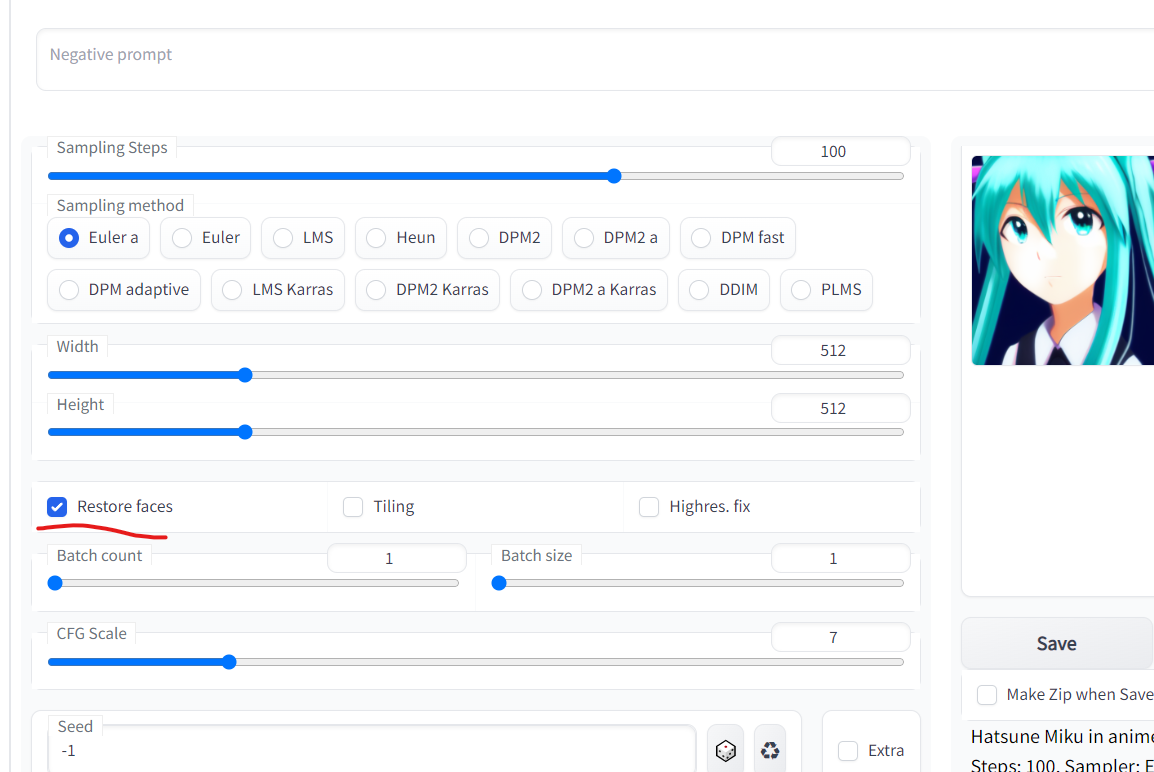
Sampling method(サンプリング手法)
- 「Sampling method」は、フィードバック工程においてどのようなアルゴリズムを採用するのか
- 基本的には「Euler a」でOK。
Sampling Steps(サンプリングステップ数)
- 「Sampling Steps」は、画像生成にあたってのフィードバック工程を何回行うのか
- 初期設定20
- 110が一つの目安?(VRAMとの相談)
画像の保存先
- 生成した画像は、ブラウザで「名前を付けて画像を保存」しなくても、「Stable Diffusion web UI」をインストールしたフォルダの下層の「output」内に、「txt2img-grids」「txt2img-images」に分けて保存されています。
- 「txt2img-grids」は、1回に複数の画像生成を行ったときの画像が一覧状態となったものが保存されています。
- 「txt2img-images」は過去に生成した画像がすべて保存されています。
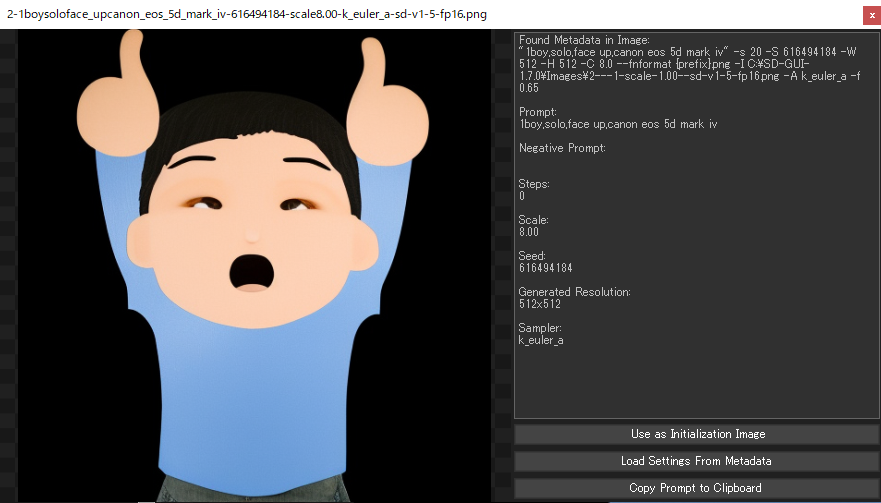
- 「txt2img-images」に保存されているファイルは、名前に生成時のプロンプトが自動的に挿入されているほか、メタデータとしてシード値や生成時の設定が埋め込まれているので、同設定での画像再生成ができます。
メタデータやシード値の確認
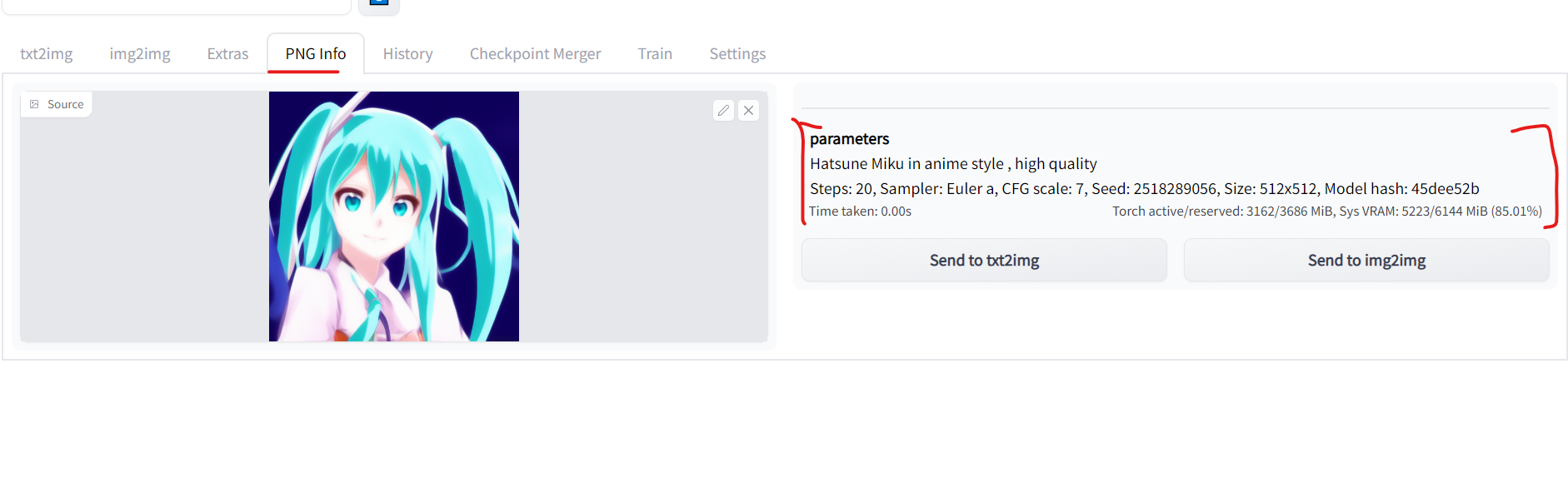
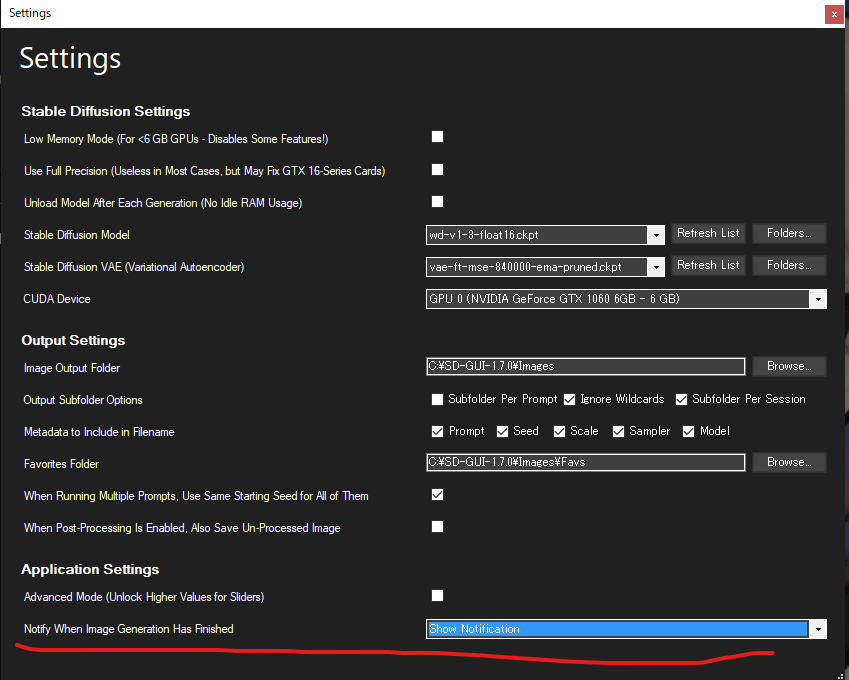
処理終了時にブラウザポップアップ通知
- 「Settings」タブの一番下
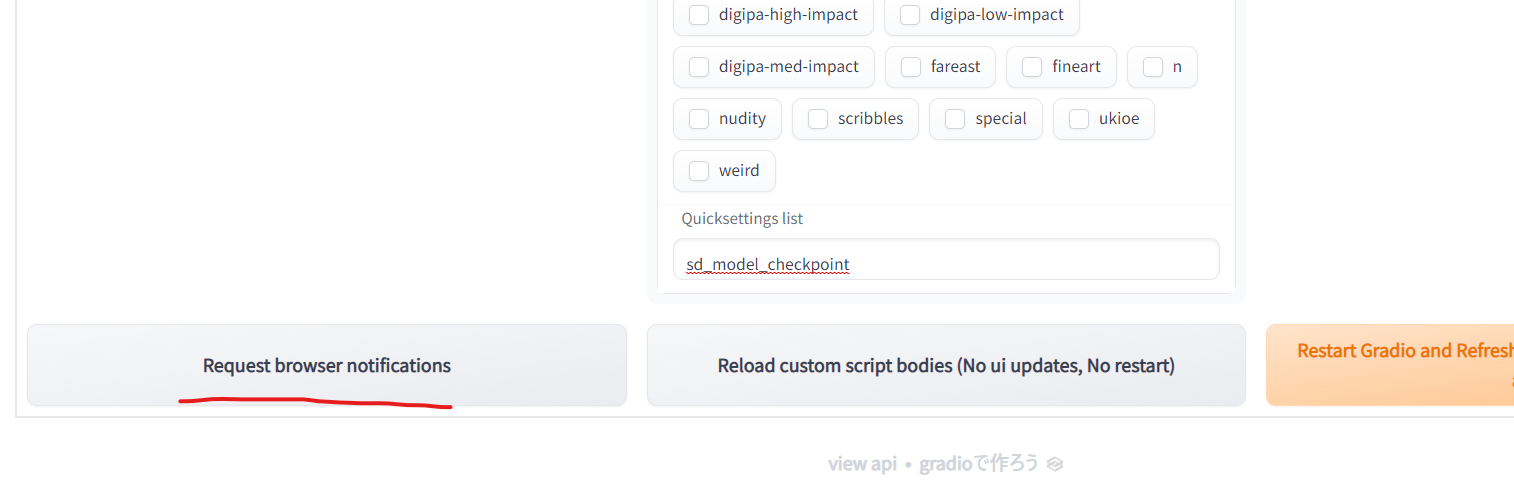
- 設定したのにポップアップ通知がされない場合は以下を確認する
- Chromeブラウザのアドレス入力欄の左端にあるアイコンをクリックし、通知設定を確認
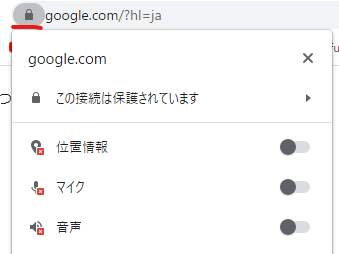
- Windows→システム→通知とアクション→ChromeブラウザがONになっているか確認する

「MKD Stable Diffusion GUI」 の導入
- 一番導入が簡単
導入
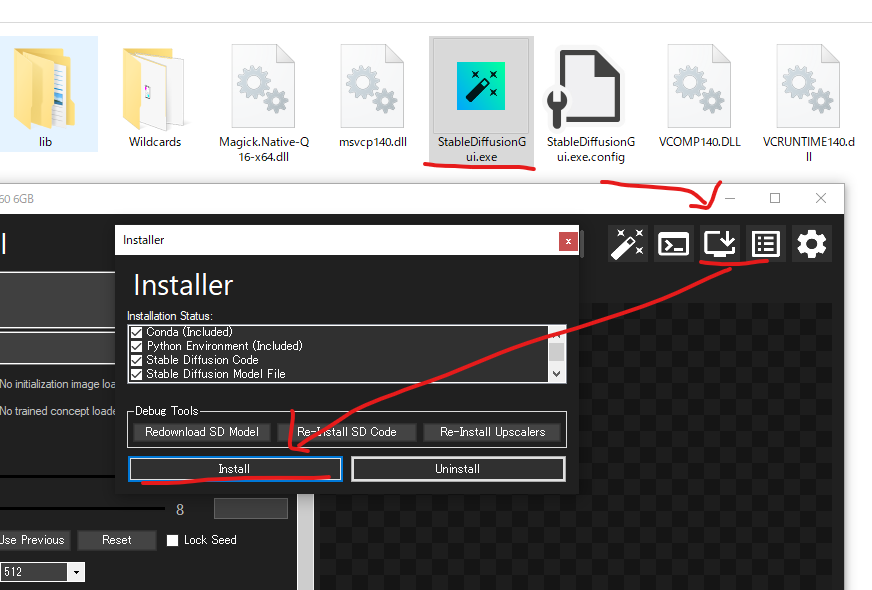
詰まっている箇所
- メタデータがうまく付与されていない
- I2Iで再出力した画像には付与される
- Stable DIffusion Web UIで使った画像はうまく認識してくれる
「MKD Stable Diffusion GUI」 の使い方
処理終了時の通知
モデルデータの追加・切り替え
モデルデータの追加
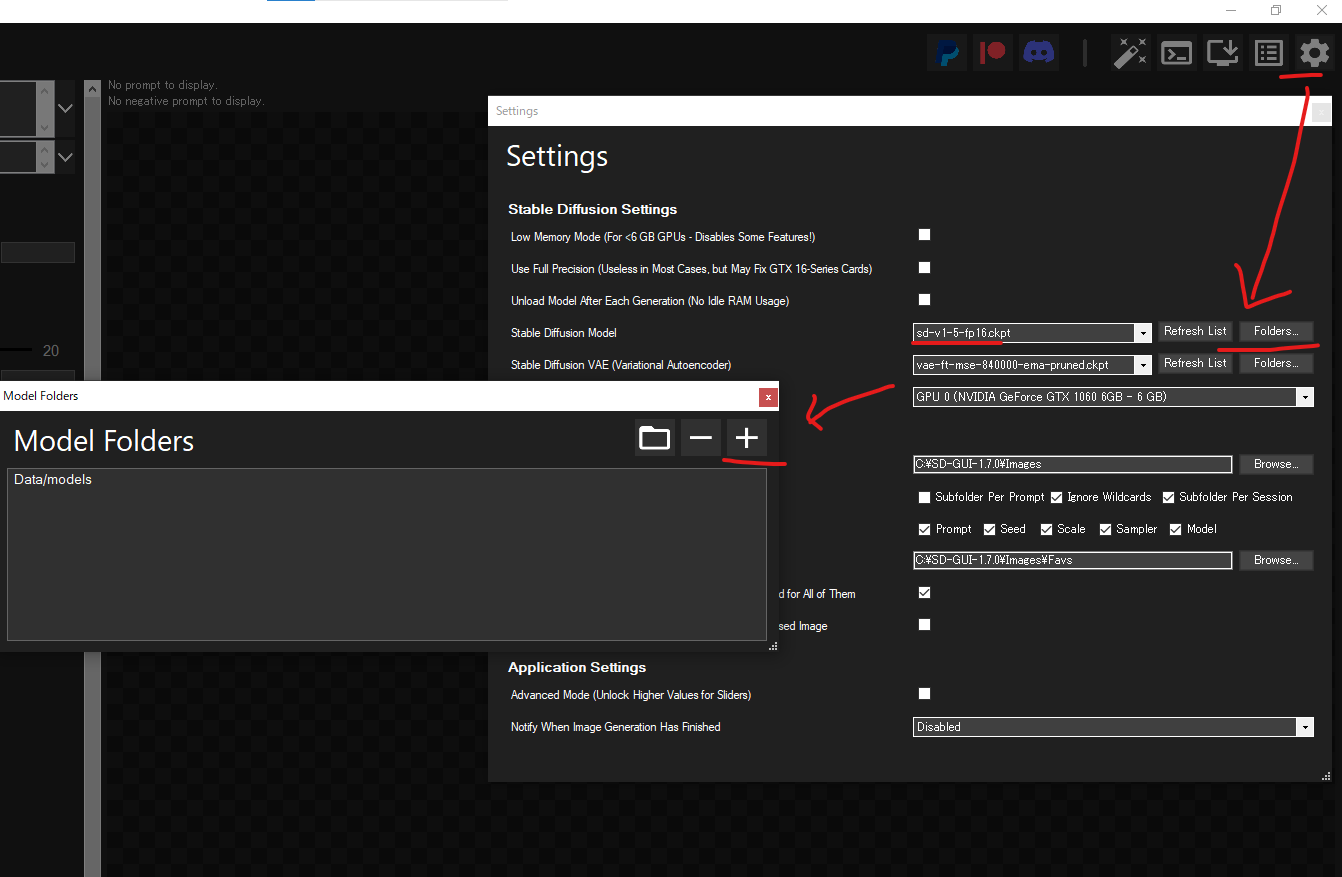
モデルデータの切り替え
1.Ctrl + M キーのショートカットキーを押す
2.矢印キーで使用モデルを選択して Enter キーで決定
モデルデータの切り替え
1.Ctrl + M キーのショートカットキーを押す
2.矢印キーで使用モデルを選択して Enter キーで決定
アップスケーリング
- ポストプロセスで設定する?
- 出力した画像しか適用できないのか?
シームレス画像の作成:Generate Seamless (Tileable) Images
- Ver1.7でチェックボックスが無い?
brick wall texture
img2imgの使い方
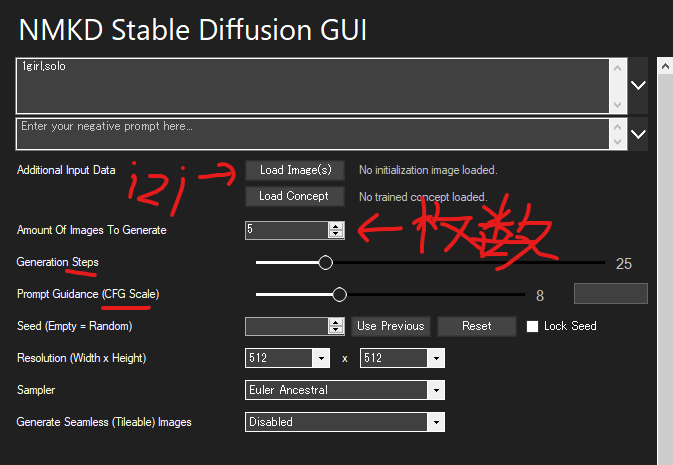
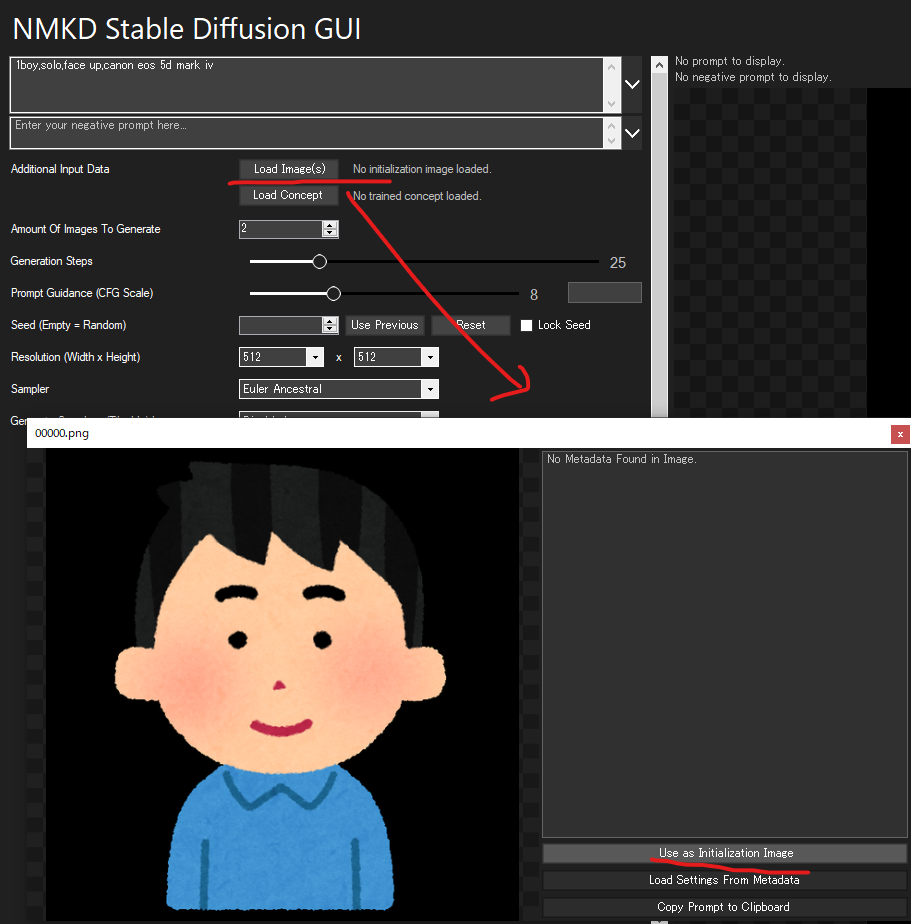
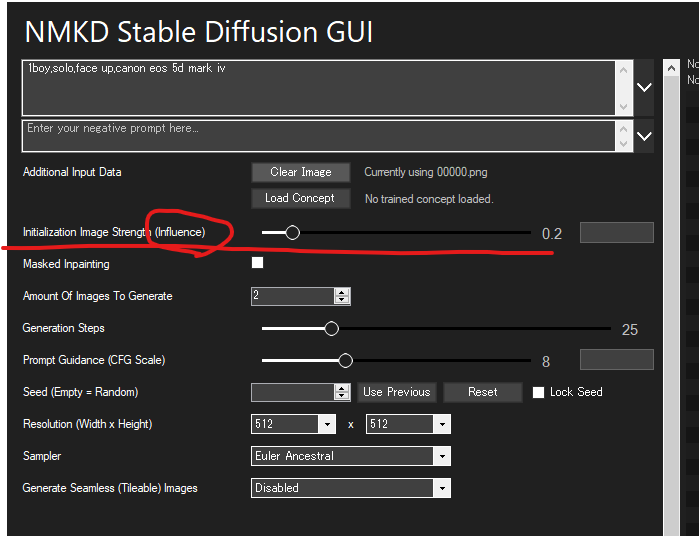
画像作成AIで作った画像のメタデータを参照する
NovelAI
参考A
参考B
参考B
- 最初に「webui-user.bat」を起動してはいけない
- 「set COMMANDLINE_ARGS=」に「--xformers」を追加する
- 「GFPGAN」を「stable-diffusion-webui\models」フォルダに入れる
- コピー元の「stableckpt\animefull-final-pruned」フォルダの「model.ckpt」ファイルを「stable-diffusion-webui/models/Stable-diffusion」フォルダへコピーする
- 「model.ckpt」ファイルを「final-pruned.ckpt」へリネームする
- コピー元の「stableckpt」フォルダにある「animevae.pt」ファイルを先程と同じフォルダに入れる
- 「animevae.pt」ファイルを「final-pruned.vae.pt」へリネームする
- 「stable-diffusion-webui\models」下に新しく「hypernetworks」フォルダを作成する
- コピー元の「stableckpt\modules\modules」のファイルをすべて「hypernetworks」フォルダにコピーする
- Setting画面の「Stop At last layers of CLIP model」を「2」にして「Apply Settings」する
- Eta noise seed deltaを31337
- eta (noise multiplier) for ancestral samplers: 0.67
ハローアスカ(アスカテスト)

プロンプトの内容:masterpiece, best quality, masterpiece, asuka langley sitting cross legged on a chair
ネガティブプロンプトの内容:lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts,signature, watermark, username, blurry, artist name
サンプリングのステップ数:28
サンプリング形式:Euler
CFG Scale(プロンプトの強度):12
初期Seed:2870305590

コメントをかく