Textual Inversion
最終更新:
![]() kenken2020 2022年11月23日(水) 11:15:42履歴
kenken2020 2022年11月23日(水) 11:15:42履歴
Textual Inversionメモ 
参考:What is Textual Inversion?
元:An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
元のGitHub
重要:すべてのトレーニング セットの画像は直立している必要があります。携帯電話でキャプチャした画像を使用している場合は、出力画像ディレクトリにあるinputs_gs*.jpg ファイルをチェックし、向きが正しいことを確認してください。多くの携帯電話は、90 度回転して画像をキャプチャし、画像メタデータでこれを示します。Windows はこれらを正しく解析しますが、PIL は解析しません。したがって、それらを手動で修正する (例えば、ペイントに貼り付けて再保存する) か、メタデータの解析が追加されるまで待つ必要があります。
元:An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
元のGitHub
where the initialization word should be a single-token rough description of the object (e.g., 'toy', 'painting', 'sculpture'). If the input is comprised of more than a single token, you will be prompted to replace it. Please note that init_word is not the placeholder string that will later represent the concept. It is only used as a beggining point for the optimization scheme.
- 初期化語(initialization word)はオブジェクトの単一トークンの大まかな説明でなければならない(例えば、「おもちゃ」、「絵画」、「彫刻」)。
- 入力が単一トークン以上で構成されている場合、置換を促すプロンプトが表示されます。
- init_wordは、後に概念を表すプレースホルダー文字列ではないことに注意してください。これは最適化スキームの開始点としてのみ使用される。
重要:すべてのトレーニング セットの画像は直立している必要があります。携帯電話でキャプチャした画像を使用している場合は、出力画像ディレクトリにあるinputs_gs*.jpg ファイルをチェックし、向きが正しいことを確認してください。多くの携帯電話は、90 度回転して画像をキャプチャし、画像メタデータでこれを示します。Windows はこれらを正しく解析しますが、PIL は解析しません。したがって、それらを手動で修正する (例えば、ペイントに貼り付けて再保存する) か、メタデータの解析が追加されるまで待つ必要があります。
Textual Inversionでキャラ作成テスト(そこそこ成功?)
- 目標:フィッシュル(Fischl、原神)の顔のPTファイルの作成
- ハードウェア:Colab
- 学習に使ったモデル:
- 学習画像:ネットで集めて良い感じに加工した18枚
- 学習画像サイズ:512x512
- embedding名:fischl
- Initialization Text: eyepatch,green eyes,bangs,hair over one eye,floating hair,blonde hair,long hair,twintails,two side up,black hair ribbon
- Prompt template file:hypernetwork-02.txt
- 画像タグ:[name], [filewords] だけ書かれたファイルを使用
- Dataset directory:/content/drive/My Drive/TX_test01
- Number of vectors per token:8
- 学習率:
5e-3:5000, 5e-40.005 - ステップ数:10000
- 学習にかかった時間:
2時間
Colabだと途中ブラウザがとまるが、Cloab側の実行中セルを見ると、動いている事がわかる
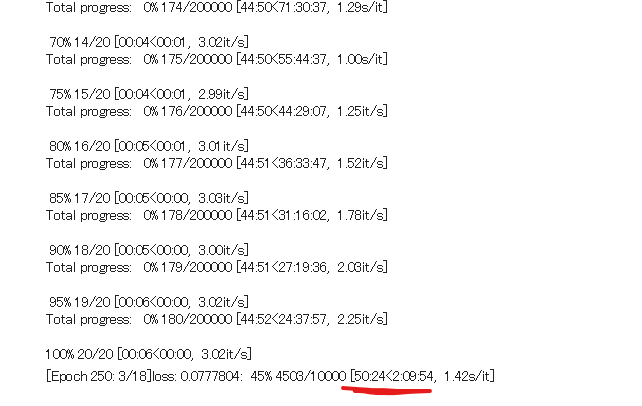
空のPTファイル作成時の設定
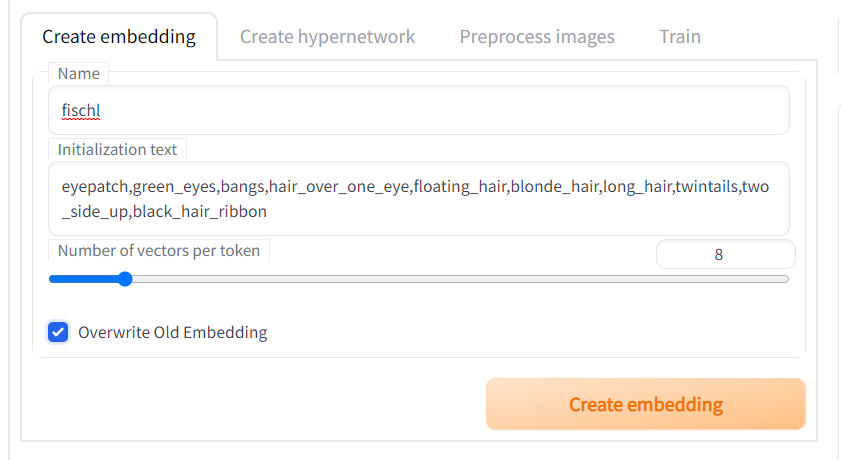
画像タグテキストファイルの設定
これで正則化画像を作っている?
「textual_inversion_templates」フォルダ→「subject.txt」ファイルの中身に「画像タグ」のプロンプトを一行ずつ(カンマなし)で並べて追記する
トレーニングの設定
失敗原因の調査
- 「Initialization Text」か「画像タグ」?
- Initialization Text→gilr
- 画像タグ→追記なし
- タグのアンダーバーを半角スペースに変換してなかったから?
- 画像タグテキストファイルの改行コード?
枚数が多すぎた?ドリームブースの設定で18枚使っていた→5枚に変更
Textual Inversionメモ
トレーニング時にVRAMからVAEとCLIPを無効にする?
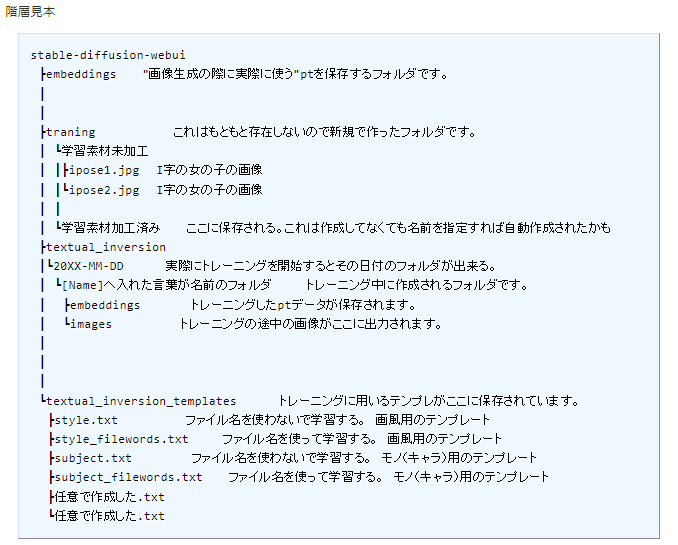
- 「--lowvramand」や「--medvram」を使用(低VRAMオプション)している場合は使えない
- 学習時に使用するモデルは一番小さいのでも十分?fullは基本数万枚の画像を追加で学習させるときに使う?
-学習させたい特徴は embedding 作成時の Initialization Text に入れる。 -学習してほしくない特徴(white background や close-up など)は画像のタグファイルに書く。 -重要なポイントは学習させたい特徴はタグに含めてはいけないということだ。言い換えるとタグに含めるのは学習してほしくない特徴。
- たとえば白髪赤目センター分けショートヘアーの c1 というキャラの顔を学習させるとしよう。
- 学習させたいタグは red eyes, white hair, parted bangs, short hair 。
- なのでこれを Initialization Text に入れる。
- すると c1 の初期特徴ベクトルは red eyes, white hair, parted bangs, short hair を合成したものになる。
- そして画像のタグファイルに red eyes, white hair, parted bangs, short hair を含めてはいけない。
- なぜならそれらの特徴を c1 という語に関連付けさせたいからだ。
Textual Inversion による学習の流れ
- 指定されたプロンプト(styles.txt などで指定)で画像を生成する。(正則化画像のこと?)
- 生成した画像と学習用画像とを比較して差異を計測
- 計測した差異を元に語のウェイトを調整。Hypernetwork の場合はプロンプト全体を調整
- 拡張機能「embedding-editor」で調整できる?
設定関連
- VAE関連
- 画像が暗くなる入れた方がいい?
- vae は学習に影響を与える。VAE を外す場合は ckpt と同じディレクトリにある .vae.pt をリネームするか、別のディレクトリに移動する。
- Hypernetwork関連
- Hypernetwork は学習に影響を与えるので外す。
- Hypernetwork strength を1に戻す、1未満だと学習が遅くなる。
- プレビューの固定
- train タブの train で Read parameters (prompt, etc...) from txt2img tab when making previews にチェックを入れると、任意のプロンプトやパラメータでプレビューできる。
- 特にシードの固定は絶対にしておきたい。
「Accelerate」を使ったTextual Inversion
参考:Stable Diffusionを手塚治虫のキャラクターでファインチューニングしてみる(Textual Inversion)
上記サイトのClobデモ
https://colab.research.google.com/drive/186bQEj40c...
上記サイトのClobデモ
https://colab.research.google.com/drive/186bQEj40c...
- 上記デモで使う「Stable Diffusion v1-4」のモデル使用許可を認証しているか?
- 「Hugging Face」のアクセストークンを取得する
- 画面上部のメニュー→「ランタイム」→「ランタイムのタイプを変更」→「ハードウェアアクセラレータ」を「GPU」に変更する
Textual Inversionの流れ
1.ライブラリのインストール
3.Hugging Faceにログイン
4.HuggingFace Accelerateを初期化
6.新しいコンセプトの画像をcolab上にアップロードする
7.学習用の設定を行う
- diffusersのトレーニングをインストール?
- ライブラリの依存関係をインストールしている?
3.Hugging Faceにログイン
4.HuggingFace Accelerateを初期化
- ここもうちょっと
6.新しいコンセプトの画像をcolab上にアップロードする
7.学習用の設定を行う
未解決の問題点
- GPUが使われていない?
- 「use_auth_token \」を削除すると進む?
- 「--use_auth_token」は何のオプションなのか?
Cloab+WebUIでTextual Inversion(いらすとや風PT)
空のPTファイルを作る
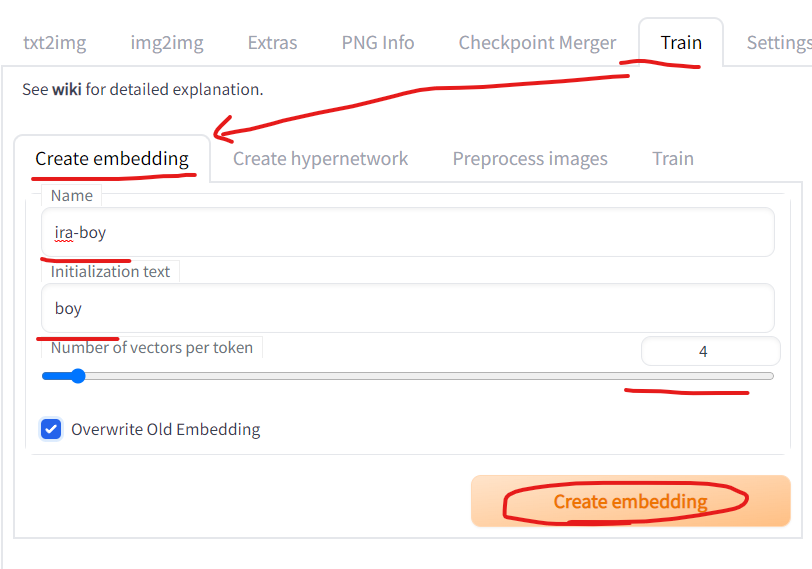
- 「Train」タブ→「Create Embedding」タブへ進む
- 「Name」にPTファイルの名称を入力
- このPTファイルの名称をプロンプトで使う
- 「Initialization text」に、その覚えさせるものに一番近い概念を入力する
- 男や男キャラならboyなど
- 「Number of vectors per token」では作成するptファイルのtoken数
- トークン毎の埋め込みベクトル数(embedding)?
- この値を大きくすればより多くの情報を詰め込めるが、より多くのトークン数を消費する
- プロンプトは 75 トークンしか入力できない。大ベクトルで良い結果を得るには、より多くの画像が必要になる。また大ベクトルは余計な情報を学習してしまう事にも注意が必要。
- 1〜8のあいだ?8で丁寧、実験では4ぐらいか?画風なら小さくてもいい?
- トークン毎の埋め込みベクトル数(embedding)?
- トークン数は追加機能の「Tokenizer」で調べる!
- 「Create embedding」を押すと「embeddings」フォルダ内に空のptが作成される
トレーニングの設定を決める
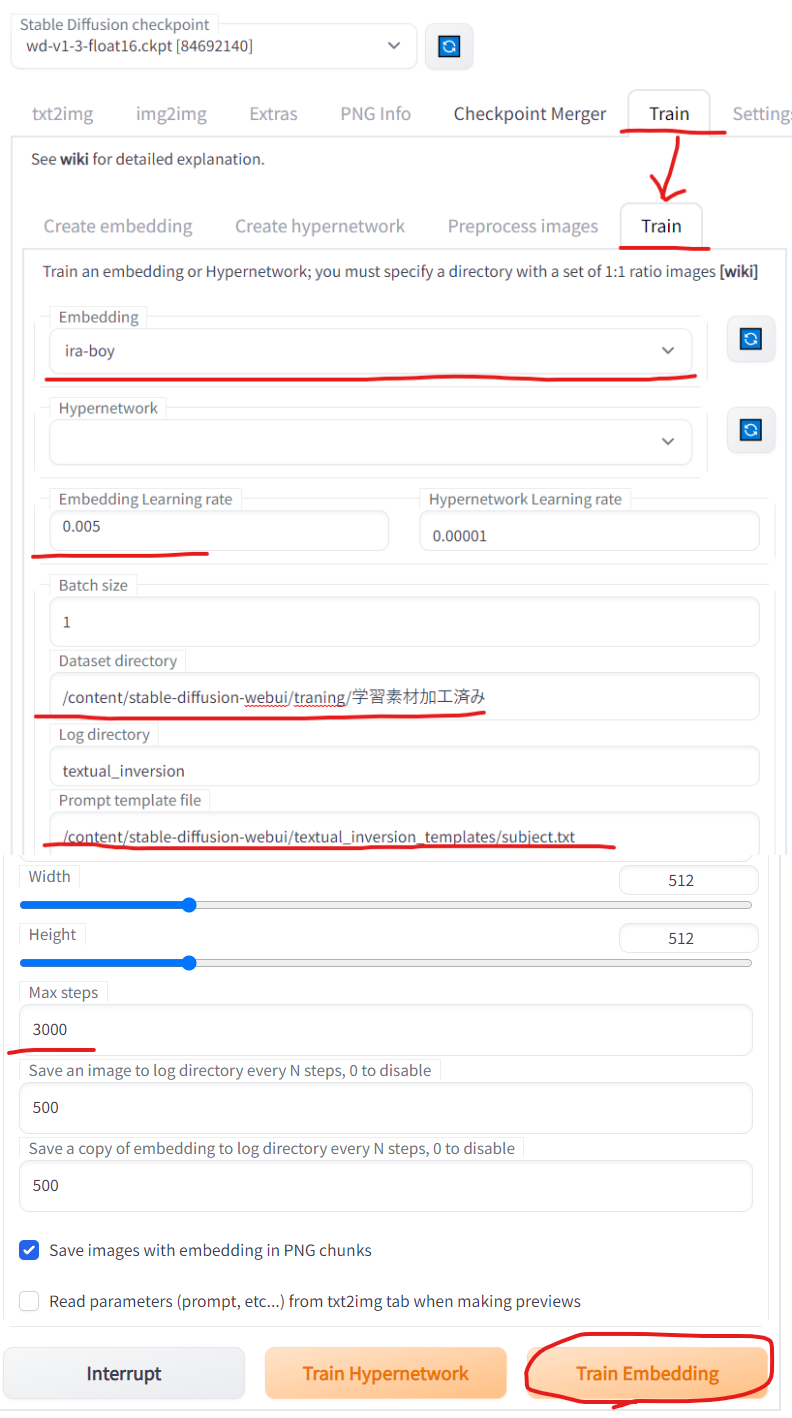
- 「Train」タブ→「Train」タブ
- 「Embedding」
- 「embeddings」フォルダ内のptの一覧が表示されるので、先ほど作成した空のptを選択する
- 「Embedding Learning rate」
- 学習率、学習の深度を決める数字
- 高すぎる値を設定すると embedding(PTファイル)が壊れる(最初はデフォの数値で試す)
- training info textbox に「Loss: 〇〇」が表示された場合、学習に失敗し embedding は死んだ事を意味する。これはデフォルト値では絶対に起こらない
- 複数の学習率を指定することもできる
- 「Batch size」
- 1回の学習に使う画像枚数。これを上げると、VRAM を余計に使い計算速度も落ちるが、精度が上がる。
- 「Dataset directory」
- 加工済の画像を保存したフォルダのパスを指定する。
- 「Prompt template file」
- 1行にひとつプロンプトが書かれたファイル。
- これはモデルをトレーニングするときに使われる。
- 何を学習するかによって使うべきtxtファイルが違う
- 学習はtxtファイルの中にあるpromptにそって行われる
- 独自に編集することによって結果が変わる
- 学習させたくないワードを書いておくと良い?
- 画風かオブジェクトかの選ぶ
stable-diffusion-webui\textual_inversion_templates\ファイル名を使い画風を学習させる場合 style_filewords.txt
ファイル名を使わず画風を学習させる場合 style.txt
ファイル名を使いモノを学習させる場合 subject_filewords.txt
ファイル名を使わずモノを学習させる場合 subject.txt
- 「Max steps」
- トレーニングが終了するステップ数。画像1枚をモデルに学習させたときに1ステップと数える。
- トレーニング画像を1周すると 1 epoch。
- 1ステップで複数の画像を学習させるにはバッチを使うが、未サポート。
- 何step学習を回すか。デフォは10万が入っているが過剰
- 途中で停止や再開が出来る(「Interrupt」アイコンを押す)
- 3000、1万、3万くらいで指定して様子見がいいかも
- 「Train embedding」の方を押す
- Cloabで学習画像の指定
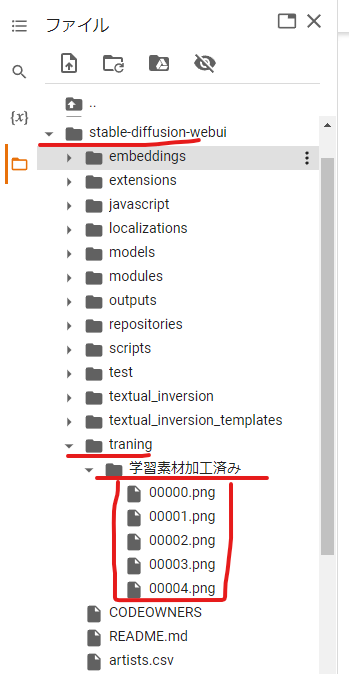
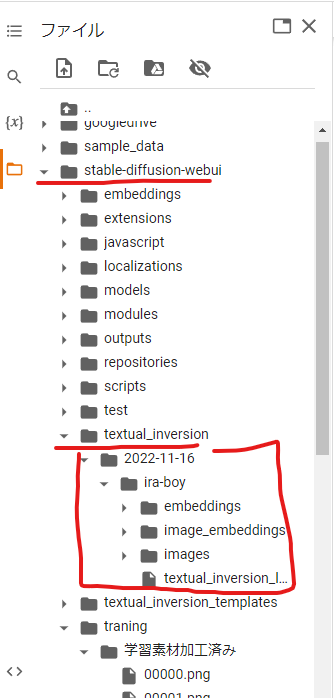
- 「textual_inversion」→「学習の日付」→「学習の名前・PTファイル」→「images」フォルダを見ると学習途中の画像が表示される
トレーニングの中断と再開
トレーニングの中断
トレーニングの再開
- 「Interrupt」を押してトレーニングを止めると、自動的に「embeddings」フォルダ内の指定したptにはそのstepまでの学習結果が記録される
- 途中結果のPTファイルをコピーして別起動のStablediffusionで確認し、十分ならトレーニングを終える
トレーニングの再開
- 空のptを作成するstepを飛ばし、前回学習に用いたptファイルを「Embedding」で指定するだけ
- 中から再開する場合には「Learning rate」を落とした方が良い結果が出る?
Colabでフォルダをダウンロードする
- Stable DIffusionが動いている時は保存が難しい?
#先頭に!マークをつけるとコマンドを使える又は
!zip -r /content/folders.zip /content/folder-name
from google.colab import files
files.download('file_name')

コメントをかく