用語解説(SD関連)
最終更新:
![]() kenken2020 2022年11月21日(月) 17:41:00履歴
kenken2020 2022年11月21日(月) 17:41:00履歴
- 数学関連
- 機械学習、ニューラルネットワーク
- ニューラルネットワークの層(layers)
- ニューラルネットワークの種類
- ファインチューニング(Finetune)の手法
- 略語
- 用語解説
- 正規化 正則化 違い
- エポック(epoch)数とは?
- トークン・トークン化とは?
- Diffusersとは
- CLIP(Contrastive Language-Image Pre-training:対照的な言語のイメージ事前学習)とは
- Stable Diffusionとは
- 拡散モデル(Diffusion Model)、潜在拡散モデル((Latent Diffusion Models)とは
- 機械学習(マシンラーニング)」と「深層学習(ディープラーニング)の違い
- embedding(単語の埋め込み)とは?
- 単語ベクトルとは?
- コサイン類似度とは?
- 機械学習における「学習」と「推論」
- 過学習(過剰適合)とは
- 正則化とは
- VAE(Variational AutoEncoder、変分オートエンコーダ)とは何か?
数学関連 
微分するとは何か?
- 微分とは「瞬間の変化率」のこと
- 視覚的には「ある関数のある地点における接線の傾き」のこと
- 微分=「ある関数のある地点における接線の傾き」=「瞬間の変化率」
- また概念的には、微分は「ある複雑な事象の全体を非常に細かいパーツに分解して、分析すること」を意味します。
- どんなに複雑な曲線でも、単純な直線の集合に過ぎないことを教えてくれるツール
微分可能であるとは?
- 微分可能とは,関数のグラフが滑らかであること。
- 「微分係数が存在する」→「x=ax=a での接線の傾きが1通りに定まる」→ 「グラフが滑らか」と解釈できる
シグマ(Σ)による総和
- 人工ニューロンで(入力*重み付け)の総和を求める時に使う
例えば、1, 2, 3という数列の総和である1+2+3をΣを使って表すと、以下になります。
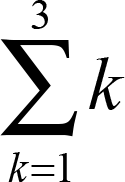
Σの下にあるk=1は初期条件、Σの上にある3は終了条件を表しており、
Σは初期条件から終了条件まで1ずつ値を変動させ、
それらの値(1, 2, 3)をΣの右にあるkにそれぞれ代入し、
代入後の値をすべて足し合わせることを意味しています。
1+2+3+…+nをΣを使って表すと、以下になります。
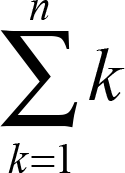
ReLU(正規化線形関数、ランプ関数)とは?
- 人工ニューロンの活性化関数で使うものの一つ
- 関数への入力値が0以下の場合には出力値が常に0、入力値が0より上の場合には出力値が入力値と同じ値となる関数である。
- ReLU(Rectified Linear Unit:正規化線形関数)とは、以下の式で表される関数のこと
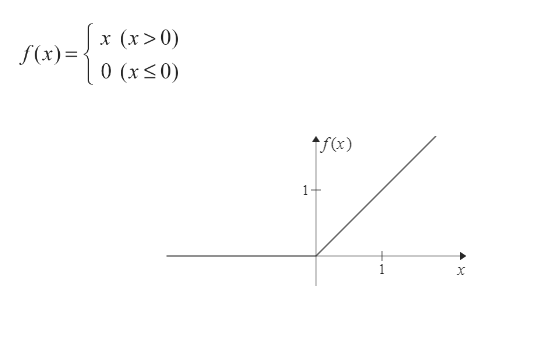

シグモイド関数とは?
参考:シグモイド関数の意味と簡単な性質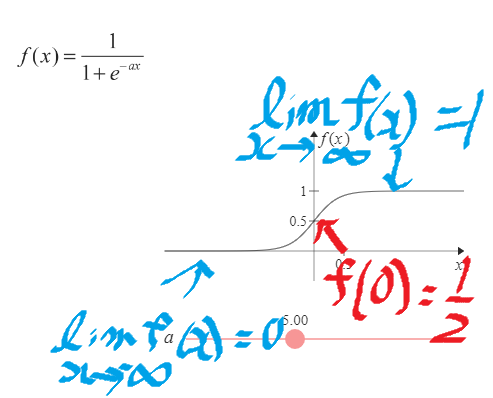
- 人工ニューロンの活性化関数で使うものの一つ
- あらゆる入力値を0.0〜1.0の範囲の数値に変換して出力する関数
- シグモイド関数とは、以下の式で表される関数のことです。aは定数
- シグモイド関数には 不連続だがよく使う関数をなめらかな関数で近似するという役割がある
- ステップ関数,符号関数など
ステップ関数(Step function)とは?
- 関数への入力値が0未満の場合には常に出力値が0、入力値が0以上の場合には常に出力値が1となるような関数
- 0を基点として、階段(step)状のグラフになるため、「ステップ関数」と呼ばれる。この基点は一般的に「閾値(いきち、しきい値、Threshold)」と呼ばれる。
- 最近のディープニューラルネットワークでは「ReLU」がよく使われる
機械学習、ニューラルネットワーク
機械学習の学習率とは?
- 学習率とは、機械学習の最適化において、重みパラメータを一度にどの程度変化させるかを表すハイパーパラメータのことです。
- 機械学習では、反復的に重みパラメータを変更していきますが、学習率の値が高いほど一度に変更する重みパラメータの大きさが大きくなるので学習のスピードは上がり、反対に低ければ学習のスピードは下がります。
- ディープラーニングにおける学習率とは、重みとバイアスのパラメーター更新を行うために、傾きに対して、どの割合で増やすかを指定する値
- 学習率を大きくしすぎると発散し、小さくしすぎると収束まで遅くなる
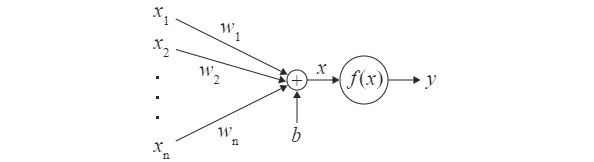
ニューラルネットワーク、人工ニューロンとは?
- ニューラルネットワークとは、脳神経のネットワークおよび脳神経の仕組みを数学的に表現したものです。
- 人工ニューロンとは、神経細胞(ニューロン)を数学的に表現したものです。ニューラルネットワークの基本的な構成要素
- 人工ニューロン≒「(入力*重み付け)の総和(Σ)+バイアス(b)」=Xとしたものを、活性化関数(fx)に入力し、yと出力したもの
- 入力→x1,x2,x3〜xn (前段のn個の人工ニューロンの出力を受ける)
- 重み付け→w1,w2,w3〜wn
- 活性化関数→f(x)
- 人工ニューロンの出力→y
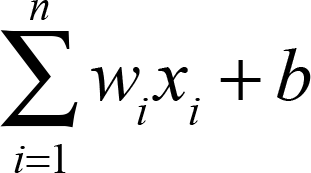
xiにwiを掛けて総和を求め、bを足します。つまり、式にすると、
重み付けとは?
- 人工ニューロンの活性化関数に入力する時に使う
- 重み付けであるwは、前段の人工ニューロンとの結び付きの強さを調整するパラメーターです。
- 直感的には、wは、神経の太さに相当します。
- w=0であれば、神経が切れているようなものです。
- 0<w<1の場合、前段の人工ニューロンの出力xを小さくして伝播します。
- w=1であれば、xをそのまま伝播します。
- w>1であれば、xを増幅して伝播します。
- w<0であれば、活性化関数の入力を減少させます。
バイアスとは?
- 人工ニューロンの活性化関数に入力する時に使う
- バイアスであるbは、活性化関数が活性化し始める閾値を決めるパラメーターです。
- ここで言う活性化とは、活性化関数がプラスの出力を出すことです。
- 例えば、利用する活性化関数f(x)がx>0から活性化し始める関数だったとします。
- このとき、b=−10とすれば、重み付けで調整された前段の人工ニューロンの出力が10を超えたときに、活性化関数が活性化し始めます。
バッチ正規化とは
レイヤー正規化
ニューラルネットワークの層(layers)
ニューラルネットワークの層(layers)とは?
- 層(layers)とは,ディープラーニングにおいて,DNN(ディープニューラルネットワーク)を構成・設計する際の最小構成単位の部品のこと
- 各種の「層」をノードとした計算グラフを構成することで,DNN構造の設計をおこなう
- つまりは,層をつなげて任意のグラフ構造にすると,ディープニューラルネットワークができあがる.
層の種類の一覧
1 全結合層
2 畳み込み層
3 活性化関数
3.1 [中間層] ReLU型の活性化関数
2 [出力層] softmax
4 プーリング層
5 バッチ正規化
6 ドロップアウト (正則化目的)
7 埋め込み層 (系列モデルむけの,トークン表現作成層.特にNLPでよく使う)
2 畳み込み層
3 活性化関数
3.1 [中間層] ReLU型の活性化関数
2 [出力層] softmax
4 プーリング層
5 バッチ正規化
6 ドロップアウト (正則化目的)
7 埋め込み層 (系列モデルむけの,トークン表現作成層.特にNLPでよく使う)
入力層
- 入力層は、データを入力する層です。
中間層(隠れ層)
- 中間層では、目的に応じた様々な種類の層を利用することができます。
- ただし、全結合層と活性化関数の層は、ほとんどの順伝播型ニューラルネットワークで存在します。
- 中間層の層数は、解く問題に応じた適切な層を利用しているのであれば、層数が多いほど、表現力は上がります。
出力層
- 出力層は、データを出力する層です。
- 解く問題によって利用する活性化関数や出力数が異なります。
全結合層(Affine層)とは?
- 全結合層とは、入力を共通にした複数の人工ニューロンの入力から活性化関数の入力までのことです。活性化関数は含みません。
- 全結合層は、ニューラルネットワークの構成要素の一つである
- DeepLearningの結合層で最も基本的なもの
- 全結合層の計算式がアフィン変換と同じであるため、Affine層(アフィン層)とも呼ばれますが、アフィン変換を行っている訳ではありません。よって、アフィン変換を理解する必要はありません。
- 全結合層は同じ入力に対して、複数の人工ニューロンが繋がっています。
- ニューラルネットワークにおける全結合は、前段と後段の人工ニューロンの神経の繋がり方をすべて網羅します。
- のちに、重み付けパラメーターの調整によって、それらの繋がり方の強度が調整されます。
- このように、全結合層は、前後の人工ニューロンを全結合することにより、柔軟にあらゆる神経の繋がり方を表現することができます。
- なお、全結合層の人工ニューロンの数は、多ければ多いほど、表現力が増します。
以下は、5入力3出力の全結合層と活性化関数の層を接続したもの(3つの人工ニューロン)
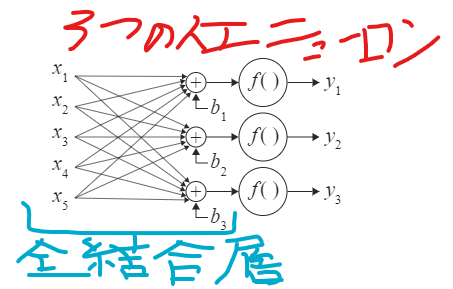
- 全結合層の単純表現
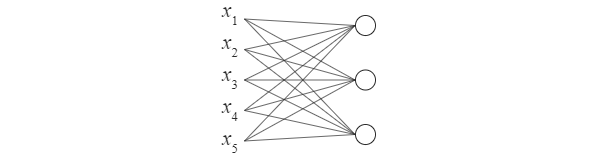
- 冒頭で示した5入力3出力の全結合層と活性化関数の層の図は、一般的には、以下のように単純化します。
- 直感的には、○が活性化関数、線と○の接合部が総和です。図では表現されていませんが、もちろんバイアスもあります。
畳み込み層 (Convolution Layer) とは?
- 畳み込み層は、畳み込み演算を入力に適用し、次の層に結果を渡します
- 畳み込み層は、元の画像からフィルタにより特徴点を凝縮する処理
- 畳み込み層は単純型細胞をモデルに考えられたもので、単純型細胞と同様、特定の形状に反応するように構成される。
活性化関数とは?
- 活性化関数とは、重み付けで調整された前段の人工ニューロンの出力を後段の人工ニューロンに伝播させる際に、伝播のさせ方を決める関数のことです。
- 活性化関数の例として、ReLUやシグモイド関数などがあります。
ニューラルネットワークの種類
畳み込みニューラルネットワーク(CNN)とは?
- CNNは画像認識や動体検知に使われるニューラルネットワーク
- ここでいう畳み込みとは、簡単に言うと画像の特徴を際立たせること
- 一般的なニューラルネットワークと違い、CNNは畳み込み層とプーリング層でできています。
- 畳み込み層で抽出した特徴をもとに特徴マップを作成します。
- プーリング層では、特徴マップの要約を行います。
- 学習可能な畳み込み層を含み,構成する層の数が合計4層以上の,ディープニューラルネットワークのことを指す.
- メインの処理が,「畳み込み層」を用いた画像の2D畳み込み(空間フィルタリング)であるニューラルネットワークであることから「畳み込みニューラルネットワーク」と呼ぶ.
順伝播型ニューラルネットワーク(FFNN)とは?
- 順伝播型ニューラルネットワークとは、入力層、中間層、出力層の順で信号が伝播するニューラルネットワークのこと
- 順伝播型ニューラルネットワークは、数学的にはただの合成関数です。
- 順伝播型ニューラルネットワークをもっとシンプルに言うと、データを入力すると別のデータが出力される関数です
- 順伝播型ニューラルネットワークの表現力を上げるために、活性化関数は、非線形にする必要があります。
- 活性化関数を線形にすると、活性化関数の表現力が落ち、さらに中間層で層を重ねても表現力が上がりません。
再帰型ニューラルネットワーク(RNN)とは?
ファインチューニング(Finetune)の手法
ファインチューニング(転移学習)とは何か?
参考:転移学習とは?ファインチューニングとの違いや活用例をご紹介
- 転移学習とは、機械学習におけるひとつの手法
- 従来の手法(ディープラーニング、深層学習でない場合?)である『教師あり学習』は、あらかじめ正解を与えて学習を行うフローとなっていて、正解を導くために大量のデータが必要となり、かつ学習時間も膨大にかかるのが難点だった
- 転移学習は、タスクの仮説立てを行ううえで、別のタスクですでに学習された知識を転用し、仮説立てを行わせる手法となる
- 大量のデータと学習にかかる時間を大幅に削減できるため、非常に効率的な手法として注目されている
- 転移学習の関連手法には、ファインチューニングや蒸留がある
- これらの手法に共通する点は「学習済みのモデルを再利用する」こと
- 転移学習
- 既存の学習済みモデルのデータは変更せず、新たに追加したモデルのデータのみ学習する
- ファインチューニング
- ファインチューニングでは既存の学習済みモデルの一部と、新たに追加したモデルを合わせた全体の微調整を行う。こうしてモデル全体のデータを再学習することで、汎化性能をより向上させる
- 蒸留
- 蒸留は既存の高度で大きなネットワークをシンプルなネットワークに軽量化する目的で用いられる
- 例)自然言語処理(英和翻訳モデルにドイツ語翻訳機能を追加する場合)
- 転移学習であればモデルはすでに英和翻訳を学習しているので、少量のドイツ語のデータセットを追加するだけでドイツ語翻訳をスピーディーに学習することができる
- 自然言語処理や画像解析の際、転移学習によって、既存のデータに少量のデータを追加するだけで、別のデータにも活用することが可能になる
- 必要な訓練データが少ない場合や、訓練データが大量にあり正解ラベルがない場合にも、短時間の学習が可能になる
ファインチューニングの種類(Stable Diffusion関連)
- Hypernetwork
- Textual Inversion
- Dreambooth
- 情報量:Textual Inversion>Dreambooth>Hypernetwork
- 3者の違い
学習データを少量足すことで新しい概念を獲得 (Text InversionやDreamBooth) する、
特定のテイストの画像が得意なモデルに修正をする (Waifu Stable DiffusionやTrinart Stable Diffusion)、
英語以外のプロンプトに最適化したモデル (Rinna Japanese Stable Diffusion) を作る、な
Dreamboothは、Text to Image拡散モデルの追加学習手法
Text to Imageでは、○○風といった追加した対象の「ニュアンス」を表現することができるようになるのに対し、Dreamboothでは、追加した対象「そのもの」を忠実に生成することができるようになる点に大きな違いがあります。
Textual Inversionは、新しい単語の埋め込みベクトルを学習するのに対して、Dreamboothは、出現頻度の少ない既存の単語を使用し、それを条件として拡散モデルのパラメータを更新する。
Textual Inversion はテキストエンコーダーを調整する。Hypernetwork はテキストエンコーダーと U-Net との間に追加のネットワークを挿入して、その追加ネットワークを調整する。
Hypernetworkとは何か?
- 画風の調整に向いてる。
- 学習時間が短く準備の手間も少ない
- 「Textual Inversion」と違い、プロンプトを追加しなくても出力に影響を与えるので、プロンプトを加えることで絵そのものが大きく変化するのを防ぐことが出来る?
- 大きなネットワーク内の複数のポイントで単一の小さなニューラルネットワークを適用する?
- 指定した画像の特性を学習し、自分好みのキャラを生成しやすくできるようにするネットワーク?
Textual Inversionとは何か?
参考:いらすとやでTextual Inversionを試す
参考:What is Textual Inversion?
参考:What is Textual Inversion?
- 好きなコンセプトを表す3〜5枚の画像を用いて、新たにそのコンセプトをモデルに学習させる手法
- スタイルを表す新規の単語の埋め込みベクトルを学習する?
- 「Stable Diffusion」のモデルに、独自のオブジェクトや画風を覚えさせることができる
- 既存のパラメータは一切更新しないで、既存モデルに新規の単語を追加することで、その単語が追加画像のスタイルを表すように学習される。
- 使用する画像は、配色やスタイルが統一されている必要がある。
- 生成するオブジェクトと同じオブジェクトの画像で学習した方が良い?
- text-to-imageモデルの単語埋め込み層をファインチューニングし、画像の画風やモチーフを新しいワードに圧縮する
- そのワードを使って画像生成のための指示を与えれば、圧縮された情報を再現することができるようになる
- 背景を塗りつぶしたり、タグ修正したりする手間が追加で発生する
- トレーニング中に使用したモデルではうまく機能しますが、別のモデルではうまく機能しない
DreamBoothとは何か?
- DreamBoothは、元々Googleの非公開の画像生成モデルであるImagenを対象にした手法
- DreamBoothとは、数枚の被写体画像 (例 : 特定の犬) と対応するクラス名 (例 : 犬) を与えてファインチューニングすること
- Text-to-Imageモデルに新たな被写体を学習させる手法
- Dreamboothでは、まず事前に学習されたText to Imageの拡散モデルに数枚の特定の被写体が写る画像と、識別子となるプロンプトを与え、追加学習させる
- 加学習されたモデルは、識別子を用いた様々なプロンプトに応じて画像を生成することが可能となる
略語
DNN(ディープニューラルネットワーク)
CNN ( 畳み込みニューラルネットワーク、Convolutional Neural Networks)
FFNN(順伝搬ニューラルネットワーク、Feed Forward Neural Network,)
RNN(再帰型ニューラルネットワーク)
用語解説
正規化 正則化 違い
参考:ディープラーニングの正規化と正則化
- 正規化
- 一般に機械学習においては、前処理においてデータを扱いやすい(学習しやすい)形に整える事。
- これをしないと、特徴ごとのスケールの差でレンジが大きいものがより影響を与えてしまうのでよくない。
- 正則化
- 最近のディープラーニング界隈では、モデルが過学習しづらくするために課すペナルティの事を総称して正則化と呼んでいる。
Dropout(ドロップアウト)とは
- 正則化の一種
- Dropoutはニューラルネットワークの過学習を防ぐために提案されたテクニック
- 一定の確率でランダムにニューロンを無視して学習を進める正則化の一種だ。
- 訓練時にランダムでニューロンを消去していくことで、毎回異なるニューラルネットワークを学習していることになる。
- 学習中のエポックごとに,異なるニューロンをランダムに除去したネットワーク構造で学習を繰り返すことにより,簡単な処理であるがディープニューラルネットの強力な正則化を行うことができるテクニック
エポック(epoch)数とは?
参考:エポック(epoch)数とは【機械学習 / Deep Learning】
- エポック数とは、「一つの訓練データを何回繰り返して学習させるか」の数のこと
- 多すぎず(過学習)に少なすぎないエポック数を指定することによって、パラメーターをうまく学習させることができる
- 良いエポック数とは汎化性能があるパラメータ集合を見つけること
- Early Stopping:学習が進んで精度の向上がこれ以上見込めないとなったら、そこで学習を止める
- 学習は各データを順番に入力しモデルのパラメータを更新していくのですが、このとき全ての学習データを一通り使用した状態を1エポックといい、この1サイクルを回した回数をエポック数という
トークン・トークン化とは?
参考:Fast WordPiece Tokenization:WordPieceによるトークン化を高速に実行(1/2)
- テキストを単語、サブワード、記号などのモデルにとって意味をなすであろう最小の単位に分割すること
- これにより構造化されていない入力文字列を機械学習(ML:Machine Learning)モデルが取り扱いやすい形式に変換する事ができる
- 深層学習ベースのモデルでは、各トークンがembeddingベクトルにマッピングされ、モデルに入力される
- 自然言語処理アプリケーションではトークン化が基本的な前処理ステップとなる
Diffusersとは
参考:最先端の機械学習モデルを利用できるDiffusersのインストール
- Diffusersとは拡散モデルの推論と学習のためのモジュール式ツールボックス
- 簡単に言うと「Diffusers」は機械学習を行う上での便利ツール
- 様々なDiffusionモデルを共通インターフェイスで利用するためのパッケージ
- Stable Diffusionモデルも多数利用出来る
- HuggingFaceがDiffusersを開発している
CLIP(Contrastive Language-Image Pre-training:対照的な言語のイメージ事前学習)とは
- CLIPは画像の分類に利用されるモデル、自然言語処理の技術を応用する
- CLIPは「画像」と「キャプション」の組み合わせからなるデータセットでトレーニングされている
- CLIPは画像エンコーダーとテキストエンコーダーの組み合わせである
- トレーニングデータを学習して結果を比較し、モデルに反映して精度を向上させる
- これをデータセット全体で繰り返すことにより、「dog(犬)」というテキストを犬の画像と結びつけられるようになる
- CLIPはモデルの仕組みではなく事前学習方法である
- CLIPの考え方として、zero-shot(初めてみるデータセット)でもうまく画像を分類できるようにする、というのが目的
- 今までのように画像とラベルのペアを集めて、それを教師データとして学習することには非常にコストがかかる
- CLIPではWebから大量の画像とテキスト(画像のタイトルや説明)のペアを取得する
Stable Diffusionとは
- Stable Diffusionは複数のコンポーネントとモデルで構成されるシステムである
- テキストを理解する「テキストエンコーダー」と、それを基に画像を生成する「画像ジェネレーター」に大まかに分けらる
- 画像ジェネレーターは「画像情報クリエイター」と、「画像デコーダー」の2つに分けられる
- テキストを理解する「テキストエンコーダー」と、それを基に画像を生成する「画像ジェネレーター」に大まかに分けらる
- 主要なコンポーネントは、入力テキストを単語ベクトルに出力する「テキストエンコーダー(ClipText)」
- 入力されたトークン埋め込みベクトルとノイズを処理された画像情報テンソルに出力する「画像情報クリエイター(UNet+Scheduler)」
- 入力された画像情報テンソルを色・幅・高さからなる画像に出力する「オートエンコーダー・デコーダー」からなります。
- テキストをノイズと共に入力してトレーニングされることで、ノイズ除去の際にテキストデータを考慮し、テキストに沿った画像を生成できる
拡散モデル(Diffusion Model)、潜在拡散モデル((Latent Diffusion Models)とは
- 「潜在拡散モデル」はその前身ともいえる「拡散モデル(diffusion model)」と呼ばれるモデルをより効率的にしたもの
- 拡散モデルとは画像に加えたノイズを除去して元画像を復元する事を学習をする
- ガウス ノイズを追加して画像を劣化させる関数と、このノイズを除去するための単純な画像復元ネットワークという 2 つの単純な部品から構築されてる
- モデルはノイズの多い画像を入力として受け入れ、ノイズを除去したクリーンな画像を出力する
機械学習(マシンラーニング)」と「深層学習(ディープラーニング)の違い
- 機械学習の1つの技術としてディープラーニングがある
- ディープラーニング(深層学習)は、機械学習の手法であるニューラルネットワークという分析手法を拡張し、高精度の分析や活用を可能にした手法
- 単層のパーセプトロン(人工ニューロン=神経細胞ニューロンの数式モデル)から多層パーセプトロンへ
- オートエンコーダーにより、層ごとに段階的に学習を行うことで学習効果が出すことが可能なった
- 教師あり学習≒ラベル?
- 教師あり学習:入力データとデータ処理結果の正解(教師)を同時に与える
- 正解を参考に、他の入力データについても分類(識別)したり、今後の動向を予測(回帰)したりすることが可能になる
- 教師なし学習:入力データのみを与える
- コンピュータは、データの共通項や法則性を独自に見つけ出してグループ化する(クラスタリング)ことができる
- 強化学習:入力データとコンピュータの出力結果に対する評価を与える
- コンピュータは評価がもっとも良くなるよう判断し出力を調整する
- ニューラルネットワーク(neural network)とは、人間の脳内のニューロン同士の結びつきを参考に作られた学習手法で、入力層・隠れ層(中間層)・出力層の3層構造になっているのが特徴
- 入力層・隠れ層(中間層)・出力層の各層をつなぐそれぞれのルートに重みが設定されていて、重みの強弱を調整することで、正しいデータ分析ができるようになる
- 深層学習では、ニューラルネットワークの隠れ層(中間層)を大幅に多層化しているので、自力で分析・抽出に必要な特徴を見つけ、精度の高いデータ処理を行うことが可能
embedding(単語の埋め込み)とは?
- 自然言語処理系の何やかんや
- 文字列を計算可能な形に変換する
- ベクトルの表現方法を工夫することで単語や文章の特徴をベクトルに表現できる
- 近い意味の単語同士を近いベクトルとなるように変換することで、ベクトルの距離や類似度で、単語の意味(っぽいもの)を表せるようになる
- 文書の類似度を計算するときによく使われるコサイン類似度を見る
- 単語埋め込みとは、単語を低次元(と言っても200次元程度はある)の実数ベクトルで表現する技術のこと
- 近い意味の単語を近いベクトルに対応させることができるとともに、ベクトルの足し引きで意味のある結果(例えば king - man + women = queen)が得られるのが特徴
単語ベクトルとは?
- 参考:【自然言語処理】単語ベクトルとは?
- 単語ベクトルとは単語を数値情報に変換したもの
- Word2Vec(word to vector)→Skip-gram や CBOW
- 単語の持つ意味や性質を活用することで、次元数を減らしていく
- 分散表現:ベクトルの各要素に単語を割り振るのではなく、各要素には単語を構成する要素が割りふる
- 例えば「りんご」を分散表現したい場合、『赤い』『丸い』『食べ物』の要素から構成する
- TVとかでたまに見るSNSのトレンドの可視化もこれ?

コサイン類似度とは?
- コサイン類似度とは、2つのベクトルが「どのくらい似ているか」という類似性を表す尺度
- コサイン類似度は0から1の間で表現され、1に近いほど類似する
- 2つのベクトルがなす角のコサイン値のこと
機械学習における「学習」と「推論」
参考:コレ1枚で分かる「『学習』と『推論』――機械学習の2つのプロセス」
- 機械学習における「学習」とは、 大量の学習データの統計的分布から、特徴の組み合せパターンを作り出すプロセスのこと
- 例えば、学習データである「ネコ」「イヌ」「トリ」の画像から、それぞれに典型的な特徴の組合せパターン(=推論モデル)を作る
- 機械学習における「推論」とは、「学習」で生成した「推論モデル」に当てはめ、その結果を導くプロセスのこと
- 例えば、未知の写真からその特徴を抽出し、「推論モデル」にその特徴を照合する
過学習(過剰適合)とは
参考:過学習とは?初心者向けに理由から解決法までわかりやすく解説
- データ全体の傾向がつかめなくなっている
- 過学習とは、「コンピューターが手元にあるデータから学習しすぎた結果、予測がうまくできなくなってしまった」という状態
- 過学習に陥っている予測モデルは、データ全体の傾向がつかめずに1つ1つの要素にフィットしすぎている傾向にある
- 過学習に気づけないと予測モデルが改善できない
- 予め訓練データと検証データ、テストデータに分けておく
- 訓練データと検証データ、テストデータにはそれぞれ役割があり、これらを準備することで予測モデルを作ってから検証することができる
- 訓練データ:モデル作成するために使うデータ
- 検証データ:モデルの精度を検証していくためのデータ
- テストデータ:未知のデータの代わりに最終的に精度を確かめるためのデータ
- 検証のプロセスを行っていく代表的な手法は2つ
- ホールドアウト法
- 交差検証法
- 過学習の対策は基本的にモデルの自由度に制限をかける
正則化とは
- 正則化とは、複雑になったモデルをシンプルにすることで過学習を解決するという手法
- どんな分析手法においても過学習対策に使える最も汎用性の高い手法
VAE(Variational AutoEncoder、変分オートエンコーダ)とは何か?
参考:【Stable Diffusion】VAEを変更して画質を上げる
- Stable DiffusionのオリジナルなVAE「kl-f8 autoencoder」
- 品質向上?
AutoEncoder(オートエンコーダ、自己符号化器)とは何か?
参考:オートエンコーダ(自己符号化器)とは|意味、仕組み、種類、活用事例を解説
- ニューラルネットワークの1つ
- 入力されたデータを一度圧縮し、重要な特徴量だけを残した後、再度もとの次元に復元処理をするアルゴリズム
- ディープラーニングは、このオートエンコーダを何層にも重ね合わせてできた構造を持っている。オートエンコーダの仕組みはそのままディープラーニングの仕組みだと言える
- オートエンコーダは、ただデータの圧縮と復元をするだけだが、VAEはデコードする際に変数を混ぜることで、入力とは少し違う出力する

コメントをかく