Hypernetwork
最終更新:
![]() kenken2020 2024年01月03日(水) 19:18:27履歴
kenken2020 2024年01月03日(水) 19:18:27履歴
Hypernetwork一時メモ(ある程度成功) 
参考:ダミーのハイパーネットワーク トレーニング
参考:ハイパーネットワーク スタイル トレーニング、小さなガイド #2670
画像のタグファイルには覚えてほしい特徴も、覚えてほしくない特徴もすべて書く。
Hypernetwork 使用時にキャラの特徴のタグをプロンプトに入れる。
参考:ハイパーネットワーク スタイル トレーニング、小さなガイド #2670
- 潜在拡散モデルのファインチューニングの手法の1つである「Textual Inversion」の派生?
- 元々NovelAIから
画像のタグファイルには覚えてほしい特徴も、覚えてほしくない特徴もすべて書く。
Hypernetwork 使用時にキャラの特徴のタグをプロンプトに入れる。
- 名前はあからさまに一般的なものや、多くのトークンの重みを引っ張るような名前をつけないようにしてください
- これは後でスタイルfilewords txtで[名前]を使うことにした場合、トレーニングプロンプトに反映されます
チェックリスト
- タグの単語の間はアンダーバーではなくスペースか?
- タグがアルファベット順になっていないか?
- VAEとCLIPをアンロードをアンロードしたか?
- 「Settings」→「Unload VAE and CLIP from VRAM when training」をチェックする
- 引数「--medvram」はオフか?
SD-WebUI使用時の注意点
- 引数「--medvram」をオンにしてハイパーネットワークをトレーニングしてはいけない!
- 引数「--deepdanbooru」を追加する
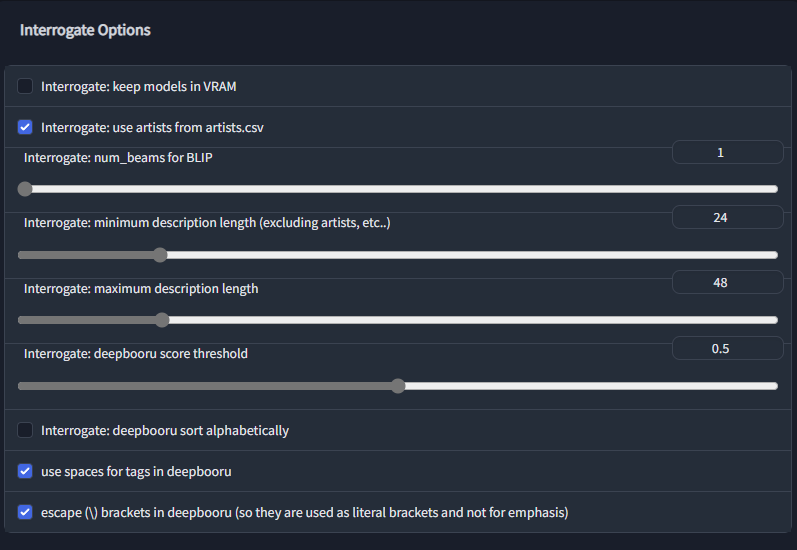
- 「Setteing」タブから以下の項目を確認する
- 「Interrogate: deepbooru sort alphabetically(ダンボールタグをアルファベット順にソート)」のチェックを外す
- 「use spaces for tags in deepbooru(deepbooru のタグにスペースを使用する)」にチェックが入っているか?
- VAEとCLIPをアンロードするか、名前を変えてwebuiを再起動する
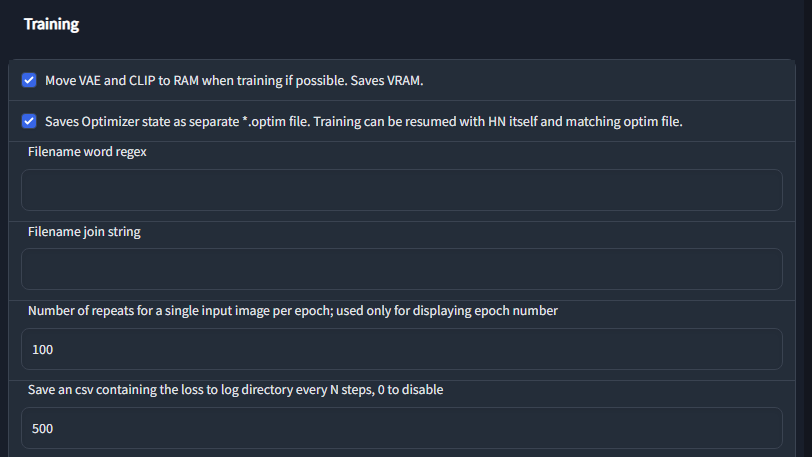
- 「Move VAE and CLIP to RAM when training if possible. Saves VRAM.(トレーニング時には、可能であればVAEとCLIPをRAMに移動してください。VRAMを節約することができます。)」をチェックする
****以下の項目を必ず確認する****
画像準備時の注意点
- 良い画像を選ぶ、量より質
- 「学習しやすそう」なデータを厳選する方が良い結果が得られる確率が高くなる
- 学習画像の枚数例
- キャラクターを覚えるには20もあれば十分
- ごく簡単なキャラクターであれば15でも十分だと思います。
- しかし、アートスタイルについては、80以上を目指してください。だいたい80から150くらい
- ハイパーネットワークのスタイル変換は、コンテンツに大きく依存することに留意してください。
- ハイパーネットワークは、学習時に使用された単語を傍受しているので、キャラクターを説明する単語がない場合は、何をすればいいのかわかりません。うまくいくかもしれないし、そうでないかもしれない。
タグの注意点
画風の場合
モデルがそのアーティスト名を認識していなくてもタグファイルにアーティスト名を入れるのは意味がある。学習後に Hypernetwork を適用して画像を作成する際に、プロンプトにそのアーティスト名を入れると画風がより固定される。
キャラ・オブジェクトの場合
キャラ・オブジェクトの場合でも、タグファイルにキャラ・オブジェクト名を入れる。学習後に Hypernetwork を適用して画像を作成する際に、プロンプトにその名前を入れると学習させたキャラ・オブジェクトを呼び出しやすくなる。
固有のキャラクターが学習データに含まれている場合キャラ名のタグは消しておいた方がいい?
→逆に、プロンプトの先頭にキャラ名を明記する!
すべてのラベルを検証し、間違っているものは削除し、足りないものは追加してください。
画像を記述することは重要です。これにより、ハイパーネットワークはトレーニング画像に近づけるために何を変更しようとしているのかを知ることができます。
プロンプトテンプレート: .txtに[filewords]のみを記述したもの。
masterpiece, best quality, [filewords], [name]
masterpiece, [filewords], [name]
best quality, [filewords], [name]
モデルがそのアーティスト名を認識していなくてもタグファイルにアーティスト名を入れるのは意味がある。学習後に Hypernetwork を適用して画像を作成する際に、プロンプトにそのアーティスト名を入れると画風がより固定される。
キャラ・オブジェクトの場合
キャラ・オブジェクトの場合でも、タグファイルにキャラ・オブジェクト名を入れる。学習後に Hypernetwork を適用して画像を作成する際に、プロンプトにその名前を入れると学習させたキャラ・オブジェクトを呼び出しやすくなる。
→逆に、プロンプトの先頭にキャラ名を明記する!
すべてのラベルを検証し、間違っているものは削除し、足りないものは追加してください。
画像を記述することは重要です。これにより、ハイパーネットワークはトレーニング画像に近づけるために何を変更しようとしているのかを知ることができます。
プロンプトテンプレート: .txtに[filewords]のみを記述したもの。
[name],[filewords]
トレーニング前の設定
Create hypernetworkタブの設定
name:fischl-pt
Enter hypernetwork layer structure:1, 2, 1
Select activation function of hypernetwork. Recommended : Swish / Linear(none):relu
Overwrite Old Hypernetwork:チェック
Enter hypernetwork layer structure:1, 2, 1
Select activation function of hypernetwork. Recommended : Swish / Linear(none):relu
Overwrite Old Hypernetwork:チェック
Trainタブの設定
Hypernetwork Learning rate
Dataset directory:/content/drive/My Drive/HN_test01
Prompt template file:/content/drive/My Drive/SD-WEBUI/textual_inversion_templates/hypernetwork-03.txt
Max steps:2500
Read parameters (prompt, etc...) from txt2img tab when making previews:チェック
Dataset directory:/content/drive/My Drive/HN_test01
Prompt template file:/content/drive/My Drive/SD-WEBUI/textual_inversion_templates/hypernetwork-03.txt
Max steps:2500
Read parameters (prompt, etc...) from txt2img tab when making previews:チェック
layer structure(全結合層、レイヤー構造)
- レイヤー構造はデフォルトのままでかまいません。
- 1, 1.5, 1.5, 1や1, 3, 1のように、最初と最後の1の間にもっと大きな数字を追加することができます。
- 一般にレイヤーを増やしたり大きくしたりすると、ハイパーネットワークはより過学習に強くなりますが、1つの学習を成功させるのにかかる時間が長くなり、生成速度が低下し、ハイパーネットワークファイルのサイズが大幅に大きくなります。
normalization layer はオフ(normalization layer をオンにして学習を成功させるのが難しい)
活性化関数の選択
- Swish/Mishはやや遅いですが、非常に安全で使い勝手が良いです。
- ドロップアウト(Dropout)は非常に便利で、過剰適合やアーティファクト(artifacts)を遅らせたい場合に使用します。
- レイヤーの正規化は使わない!
ステップ数
ステップ数。20000以下であれば十分。
5000〜10000の範囲なら、私の学習速度スケジュールでもそこそこ使えると思います。しかし、10000〜20000の範囲では、細かい部分がたくさん出てくることに気がつくはずです。
5000〜10000の範囲なら、私の学習速度スケジュールでもそこそこ使えると思います。しかし、10000〜20000の範囲では、細かい部分がたくさん出てくることに気がつくはずです。
- 12500から15000steps?
学習率(Learning rate)
- 学習率が低いほど、小さなステップ数でニューラルネットワークが崩壊(ノイズだらけ)しやすくなる?
- 学習率が高いほど?
- 序盤:低い学習率(5e-5、学習が速いがNNも崩壊しやすくなる?)で数百ステップ?回し
- 中盤:
デフォのままやるとノイズだらよくわからんのになります。
Learning rateは0.000005(5e-6) または 0.0000005(5e-7) のようなすごく小さい数が必要です。
ちなみに画像が悪いのかもしれませんが、0.0000005(5e-7)ではいい結果は得られませんでした。
私が提供できるヒントの 1 つは、ハイパーネットワークのトレーニングに(e-5)0.00005 の学習率を使用することです...デフォルトの 0.005(1e-4)を使用すると、非常に迅速に NaN に到達します。
- 5e-5(0.00005)
- 5e-6(0.000005)
- (9000~25000の間のどこかでオーバートレーニングが始まり、ハイパーネットワークを殺し始める
- 12000を超えたら、低いトレーニングレートに切り替え、オーバートレーニングやハイパーネットワーク死による影響を回避することができるようになる
- 5e-7(0.0000005)
学習スケジューラを設定する
学習速度 5e-5:100、5e-6:1500、5e-7:10000、5e-8:20000
| 表記 | 意味 | 数値 |
| 1e-2 | 1×10−2 | 0.01 |
| 1e-3 | 1×10−3 | 0.001 |
| 1e-4 | 1×10−4 | 0.0001 |
| 1e-5 | 1×10−5 | 0.00001 |
| 1e-6 | 1×10−6 | 0.000001 |
| 1e-7 | 1×10−7 | 0.0000001 |
| 1e-8 | 1×10−8 | 0.00000001 |
| 1e-9 | 1×10−9 | 0.000000001 |
トレーニング中のプレビュー
警告 トレーニング中はtxt2imgにネガティブプロンプトを入れないようにしましょう。
clipを1、cfg scaleをデフォルトに保ち、メインプロンプト領域のみを使用します。
これはRead parametersオプションがオンの時のみ発生すると思われます。
また、ネガティブプロンプト付きのプレビュー画像で2つのハイパーネットワークをトレーニングしましたが、これらのハイパーネットワークを使用中にネガティブプロンプトを削除すると、トレーニング中に壊れたようにゴミが返され、トレーニング中のネガティブプロンプトでは正常に機能します。これは何らかのバグだと思います。
シードの固定は絶対にしておきたい。
clipを1、cfg scaleをデフォルトに保ち、メインプロンプト領域のみを使用します。
これはRead parametersオプションがオンの時のみ発生すると思われます。
また、ネガティブプロンプト付きのプレビュー画像で2つのハイパーネットワークをトレーニングしましたが、これらのハイパーネットワークを使用中にネガティブプロンプトを削除すると、トレーニング中に壊れたようにゴミが返され、トレーニング中のネガティブプロンプトでは正常に機能します。これは何らかのバグだと思います。
シードの固定は絶対にしておきたい。
トレーニングの注意点
もし、結果が思わしくないと感じたら、clipskipが1に設定されていることを確認してください(これはOFFにすることです)。
VAEも結果に干渉しますので、clipskipをオフにしてもうまくいかない場合は、オフにしてテストしてください。
もしあなたのモデルがVAEを使用しているのであれば、VAEをオンにしておいてください。トレーニングに影響があるかどうかは分かりませんが、念のため。
他のハイパーネットワークをアンロードしてください。トレーニングに影響するかどうかは分かりませんが、念のため。
VAEも結果に干渉しますので、clipskipをオフにしてもうまくいかない場合は、オフにしてテストしてください。
もしあなたのモデルがVAEを使用しているのであれば、VAEをオンにしておいてください。トレーニングに影響があるかどうかは分かりませんが、念のため。
他のハイパーネットワークをアンロードしてください。トレーニングに影響するかどうかは分かりませんが、念のため。
トレーニング中止の判断
モデルが壊れてプレビューテストでカラフルなノイズが出たら、少し戻るだけでなく、さらに前のモデルを選んでその先の学習を行い、学習率をさらに下げてください
学習データを途中で変更しないで、最初からやり直した方が良い。
損失が0.3を超えたら、ハイパーネットワークが壊れている可能性があるので、学習レートを下げましょう。
もし、ある時点でゴミのようになったと感じたら、数千ステップ戻って、トレーニングレートを0に上げてトレーニングを再開してください
(5e-7より低くすることは不必要で、時間がたくさんない限り、あまり効果がないでしょう。)
- 過学習?
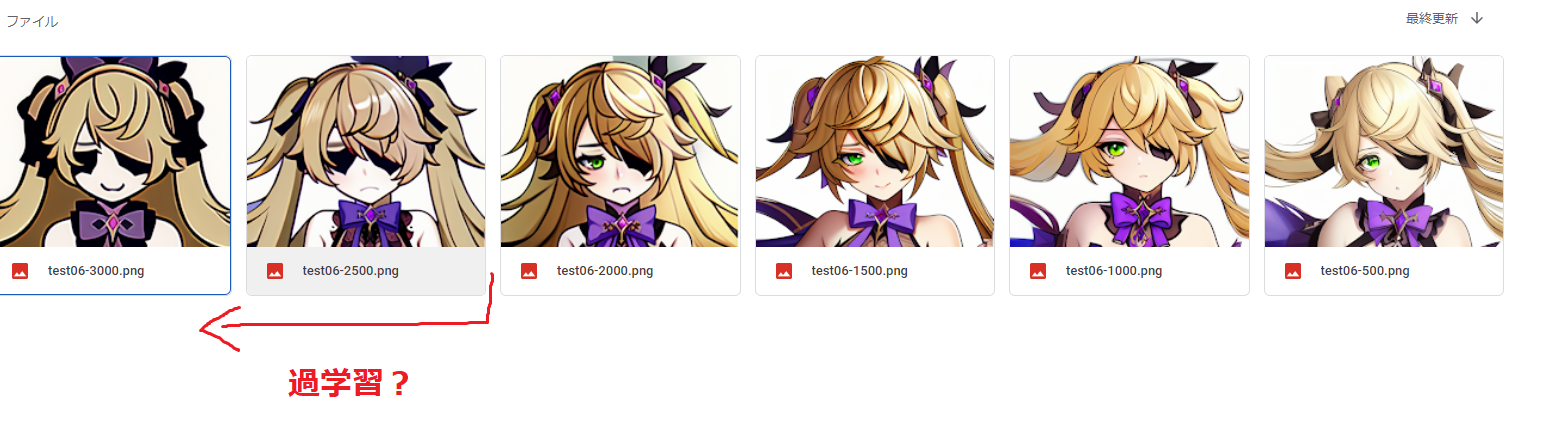
↓のように、ノイズだらけになると確実に失敗している

トレーニングの再開
- 「Setteing」→「Saves Optimizer state as separate *.optim file. Training can be resumed with HN itself and matching optim file.」
- オプティマイザーの状態を別の *.optim ファイルとして保存します。 HN 自体と一致する最適化ファイルを使用してトレーニングを再開できます
- その後「\stable-diffusion-webui\textual_inversion\datehere\hypernetworknamehere」に保存されているすべての.ptファイルをコピーし、「\stable-diffusion-webui\models\hypernetworks」 にコピーします。
- ハイパーネットワークの更新は「Setteing」で出来る

コメントをかく